공룡책 - 운영체제 정리4.1
본 게시물은 Abraham Silberschatz의 Operating System Concepts 공룡책을 참고하며
개인적으로 공부 및 정리한 자료입니다.
1.메인메모리
2.가상메모리
3.저장시스템
가상메모리 Virtual Memory
일반적으로 한 시스템의 다수의 프로세스들은 CPU와 메인 메모리를 공유하게된다. CPU를 공유하는 부분에 있어
작업 부하로 인해 Wait시간이 길어질 뿐 심각한 이슈는 발생하지 않지만 메모리의 여유가 없이 지나치게 많은 Request가 발생할경우 . 머신상 오류가 나게 된다. 이러한 이슈를 해결하기 위해 메모리 관리기법으로 가상메모리 방법이 등장하게 되었다.
가상메모리는 메모리 관리 기법중에 하나로 , 머신에서 실제 사용하는 자원을 이상적으로 추상화하여 프로그램에 실제 메모리주소를 할당하는것이 아닌 가상의 메모리 주소를 할당하여 제공하는 방식이다.
가상메모리를 통한 메모리 관리 기법은 멀티태스킹 운영체제에서 주로 사용되며 실제 주 기억장치 (RAM) 보다 큰 메모리 영역을 제공하는 방법으로 사용된다.
즉 가상메모리의 주요기능은 1. 주 기억장치 (RAM)의 효율적 관리 , 2. 메모리 관리의 단순화 , 3. 메모리 용량및 안정성 보장을 위해 고안된 기술이라고 볼수있다.
가상으로 만들어진 주소를 가상 주소 ( virtual address ) 또는 논리 주소 ( logical address) 라고 하고 주소값은 0부터 시작하여 공간의 끝까지 연속한 일련의 주소값을 가지게 된다.
실제 메모리 상의 유효한 주소는 물리적 주소 ( physical address ) 또는 real address 실주소 이며 페이지 프레임으로 구성되어있다.
또한 주소의 범위를 주로 공간!으로 정의하여 가상 메모리 주소 범위는 가상 주소 공간, 물리적 주소의 범위를 물리 주소 공간 이라고 정의한다 .
가상 주소 공간은 메모리 관리 장치 (MMU)에의해 물리적 주소로 MAPING하여 변환되며 paging 요청과 , segmentation으로 구현이되어진다. ( 즉 코딩을할때 주소공간이 상대적 공간에서 프로그램을 짜게되므로 하드웨어 관점의 실 주소에 대해 고민할 필요가 사라지게 된다. )
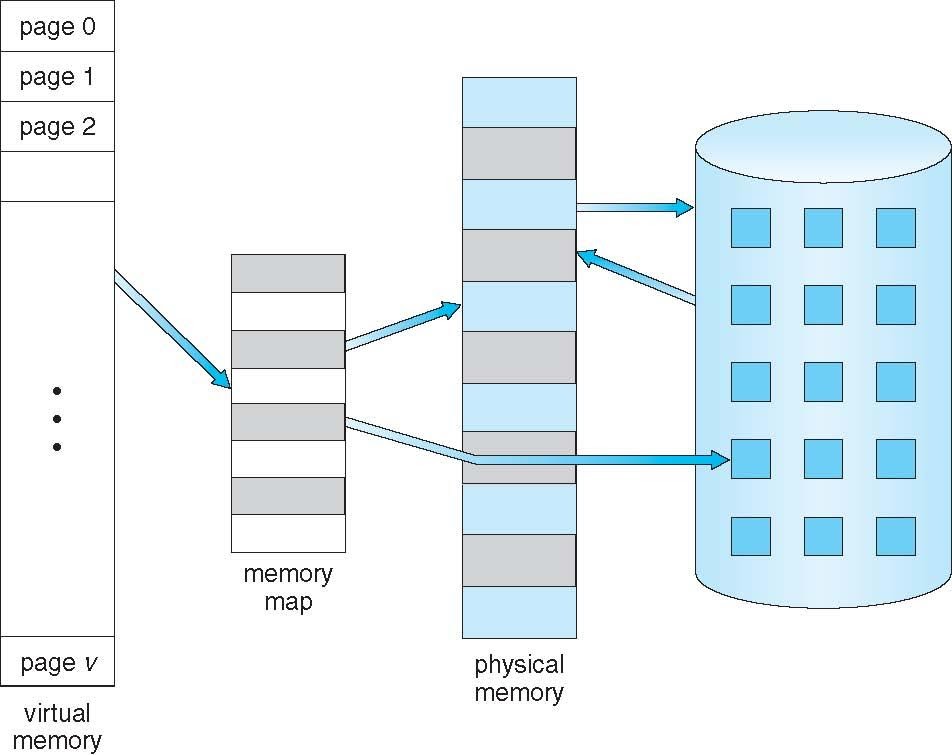
가상메모리 도입 배경
과거 부터 현재까지 많은 OS 설계자들은 RAM의 성능에 대해 고민해 왔다고한다.
왜 ? 왜 고민했을까? 아래의 상황을 들어보며 생각해보자
VM(Virtual Memory)를 사용하지 않는 시스템 상에서 어떤 프로그램을 실행 시 10KByte의 용량을 차지하는 프로그램이 존재한다면 해당 시스템이 가져야할 메모리는 최소 10K Byte 이상의 스펙을 가져야 한다. 하지만 만약 9999Byte의 메모리를 가지는 RAM이라면 Memory 부족으로 인한 Error를 사용자에게 알리게 된다 .
만약 이러한 상황에서 멀티태스킹이 진행 된다면 상황은 더 악화될것이다.
다시말하면 시스템의 메모리 용량은 항상 시스템에서 실행되는 가장큰 프로그램의 용량보다 커야한다는 조건이 나타나게 된다.
그렇다면 어떠한 시스템을 설계시 시스템을 실행하기 위해 필요한 최소한의 메모리 용량은 얼마일까?
메모리가 수용할수 있는 시스템의 최대 메모리 할당량은 얼마가 되는가에 대해 질문을 던지기 시작하게 된다.
1. 메모리는 순차적 그리고 지역화되어있는 특성이 있다. 2. 프로그램을 실행하기 절차를 보자면
명령어 READ, -> DATA READ -> 결과 메모리에 저장 각 절차를 처리하는데 200byte가 할당된다고 한다면 600byte를 할당하여 프로그램을 실행할 수 있다 .
( 즉 코드 실행시 메모리에 할당되어야하지만 전체적인 프로그램관점에서는 다량의 메모리할당이 필요하지 않는다 . )
( 또한 전체적인 프로그램 코드가 동시에 필요로하지 않게된다. )
( 결론적으로 부분적으로 로드된 프로그램을 실행할 수 있는 능력을 고려하여 프로그램이 물리적인 제약이 없도록 설계하여 프로그램 실행시 적은 메모리를 사용하여 많은 프로그램이 동시에 실행가능 하도록 해야하므로 궁극적으로 CPU의 작업이 늘어나게 된다 단 ! 응답시간과 처리시간에 영향을 끼치지 않는다 . ) .
이후 기능을 수행하는 코드 혹은 데이터를 위한 메모리 할당은 하드디스크같은 보조 기억장치에 위치하여 작업이 진행되게 된다 .
가상주소 공간 ( Virtual-address Space )이란?
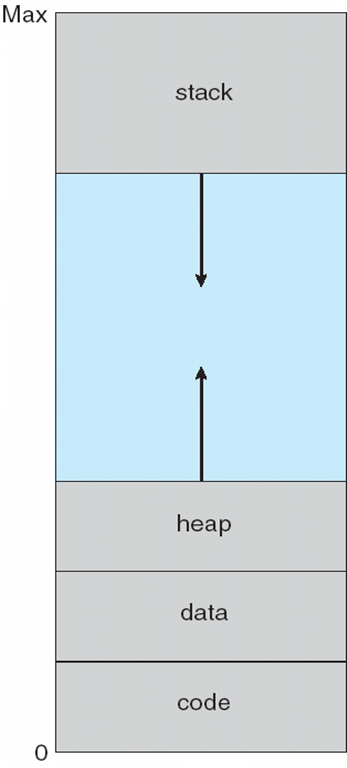
가상공간개념을 설명하기에 앞서 일반적인 주소공간에 대한 설계적 내용을 설명하고자 한다.
일반적으로 logical address space는 Max logical address 인 Stack영역은 아래로 주소공간을 할당하며 Heap영역은 위로 할당하도록 논리적 주소공간을 설계하여 주소공간의 사용을 극대화 하게 된다.
즉 가상 주소 공간이란 프로그램이 사용할 수 있는 최대 주소 공간으로 정의하게 되며 .
이 메모리관리 기법은 Register(가장 영향이 미치는 레지스터는 Base & limite register이다 )의 크기와 관련이 있는 1. CPU 아키텍쳐에 따라 주소를 지정하는 비트의 수에 영향을받게되어 달라지며 2.운영체제에 따라 영향을 받게된다.
즉 주소공간은 CPU 아키텍쳐에 영향을 받게된다는 말이다.
즉 32bit CPU는 0~ 2^32 = 4294967296bit = 4Gbyte 까지의 주소공간을 나타낼 수 있기때문에 RAM은 4GB까지 인식하는 이유이다.
* Heap영역은 동적 메모리로 런타임에 의해 크기가 결정되고 Stack은 정적 메모리가 저장되는 영역으로 컴파일 타임에의해 크기가 결정된다.
Heap은 전역 변수를 다루게 되며 사용자가 직접 관리해야 하는 메모리이며 Stack은 함수, 지역변수, 매개변수가 저장되는 LIFO방식( PUSH, POP ) 으로 관리가 된다.
* code 영역은 실행할 프로그램의 코드가 저장되는 영역으로 텍스트 영역이라고도 부른다. 즉 CPU의 입장에서는 코드영역의 저장된 코드화된 명령어를 라인으로 가져가서 처리하게된다.
*DATA영역은 전역 변수와 정적 변수가 저장되는 영역으로 프로그램의 시작과함께 할당되며 종료시 소멸된다.
만약 힙과 스택이 할당되지 않은 메모리영역은 홀이라고 하고 힙과 스택이 주어진 NEW PAGE로 커질 때 까지 물리적 메모리가 필요하지 않게된다.
Virtual Address와 Memory Management Unit 에 관하여 .
가상 주소 공간은 메모리 관리 장치 (MMU)에의해 물리적 주소로 MAPING하여 변환되며 paging 요청과 , segmentation으로 구현이되어진다. ( 즉 코딩을할때 주소공간이 상대적 공간에서 프로그램을 짜게되므로 하드웨어 관점의 실 주소에 대해 고민할 필요가 사라지게 된다. )
MMU가 없다면 CPU가 RAM에 접근 시 메모리 주소를 물리적 메모리 주소에 그대로 접근하게 된다 하지만
MMU를 사용하게 된다면 가상주소를 통하여 매핑된 물리적 메모리주소에 접근하게된다 .
그러나 위에서 말했던것과같이 32bit 0~4GByte에 해당하는 메모리를 하나씩 매핑하게되면 부하가 커지게된다.
그렇기때문에 MMU는 RAM을 일정한 크기의블록 페이지로 나누어 각 블록을 독립적으로 처리하는 방식이 고안되었다.
만약 첫 코드라인의 명령문이 물리적 메모리 공간을 초과하는 주소에 접근을 시도하게 된다면 Page Fault 현상이 발생하게된다.
MMU & RAM Slice -> Paging기술의 도입.
Paging 기능을 도입하게 되며 프로그램을 로드시 전체 프로세스를 메모리로 가져오거나 필요시 독립적인 메모리 블록인 페이지를 메모리로 가져올수 있게 되었다.
이에따라
1. 불필요한 I/O가 제거되며 I/O의 감소하는 효과
2. 적은 메모리로 효율성증대
3. 빠른 응답이 가능하게 되는 이점이 생기게 되었다.
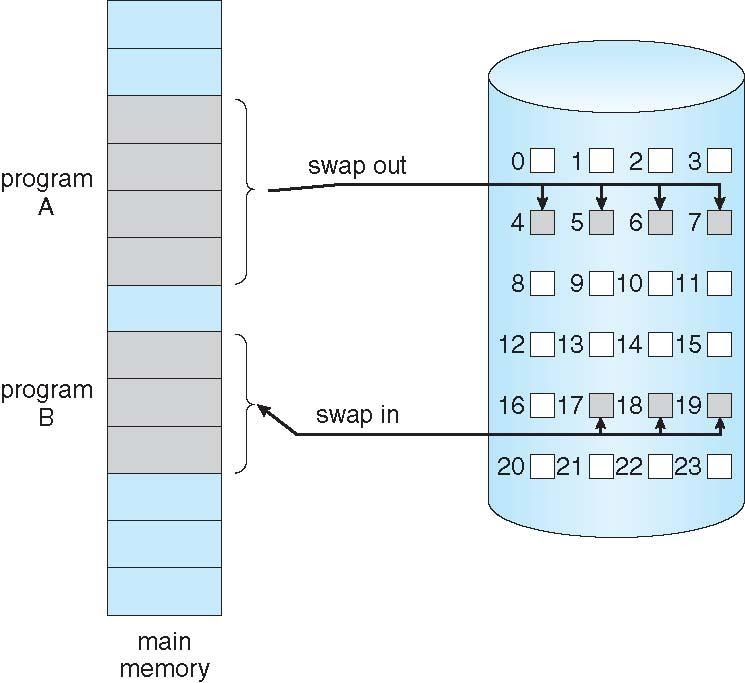
Swap
또한 페이지 시스템과 유사한 스왑기능을 왼쪽의 그림을 토대로 살펴보자면
1. 페이지가 필요시 참조하고 , 2 참조한 페이지가 잘못되었으면 중단하게 된다 .
만약 메모리에 없다면 메모리로 가져오게된다.
Lazy swapper는 페이지를 다루는 모듈로써 페이지가 필요가 없으면 페이지를 메모리로 스왑하지 않게된다.
- Swapping을 사용하게 된다면 Paper는 스왑하기전에 사용할 페이지를 추론하게된다.
이후 Pager는 그에 해당하는 페이지만 메모리로 가지고 오게된다.
페이지의 집합을 결정하고 관할하는 유닛은 MMU이고 페이징에대한 요구를 구현하기위해서 MMU입장에서는 새로운 기능이 필요하게된다.
이때 기능적 조건을 나누어보자면 페이지가 항상 메모리에 상주하며 필요한경우와 페이지가 메모리에 상주하지않으며 필요한경우로 나뉘게된다.
1.) 메모리에 페이지가 항상 상주하는 경우
NON-Demand 페이징과 차이가 없음
2) 메모리에 페이지가 상주하지 않는데 필요한경우 .
프로그램 동작과 기능은 은 변경할 필요가 없이 페이지를 감지하고 저장소에서 메모리를 로드해야한다.
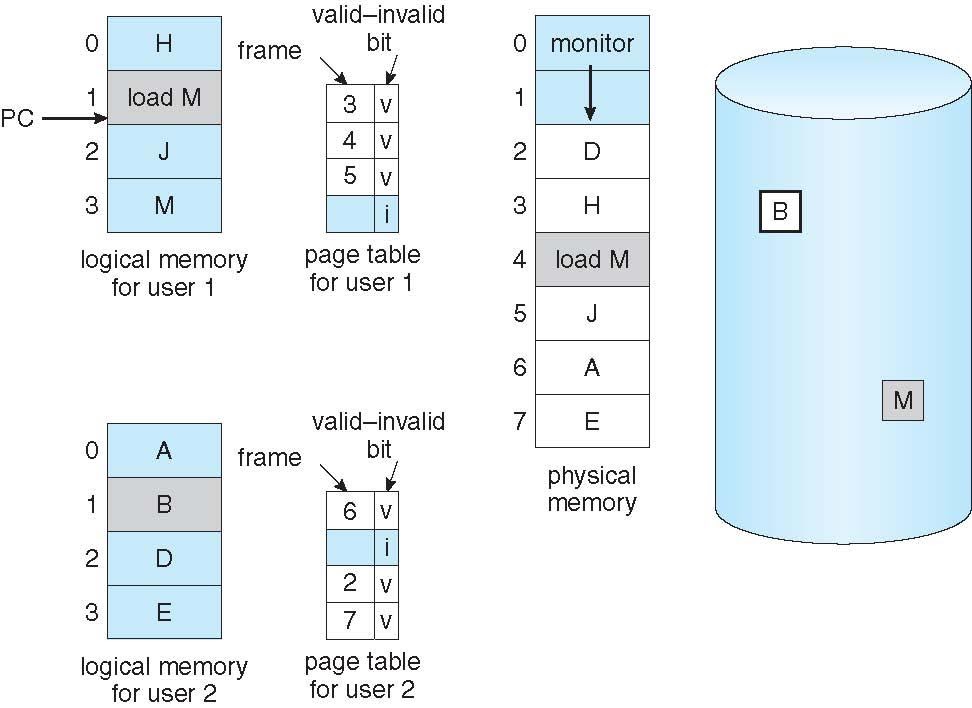
Valid - Invalid Bit
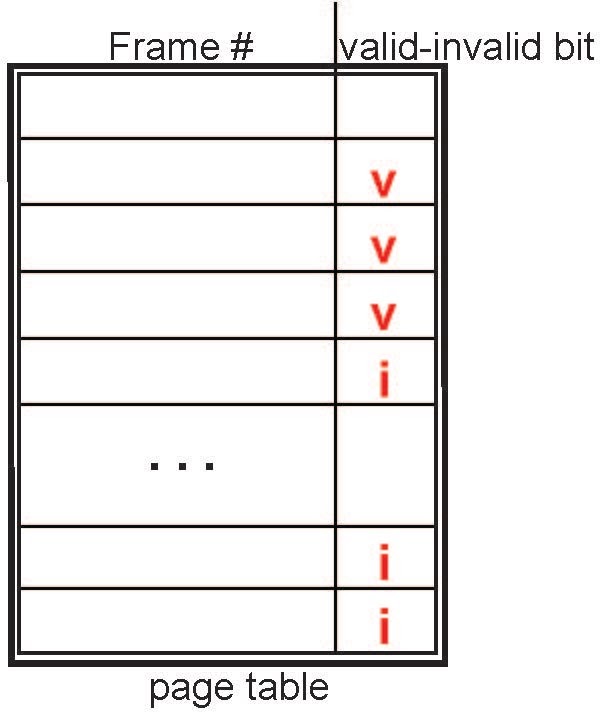
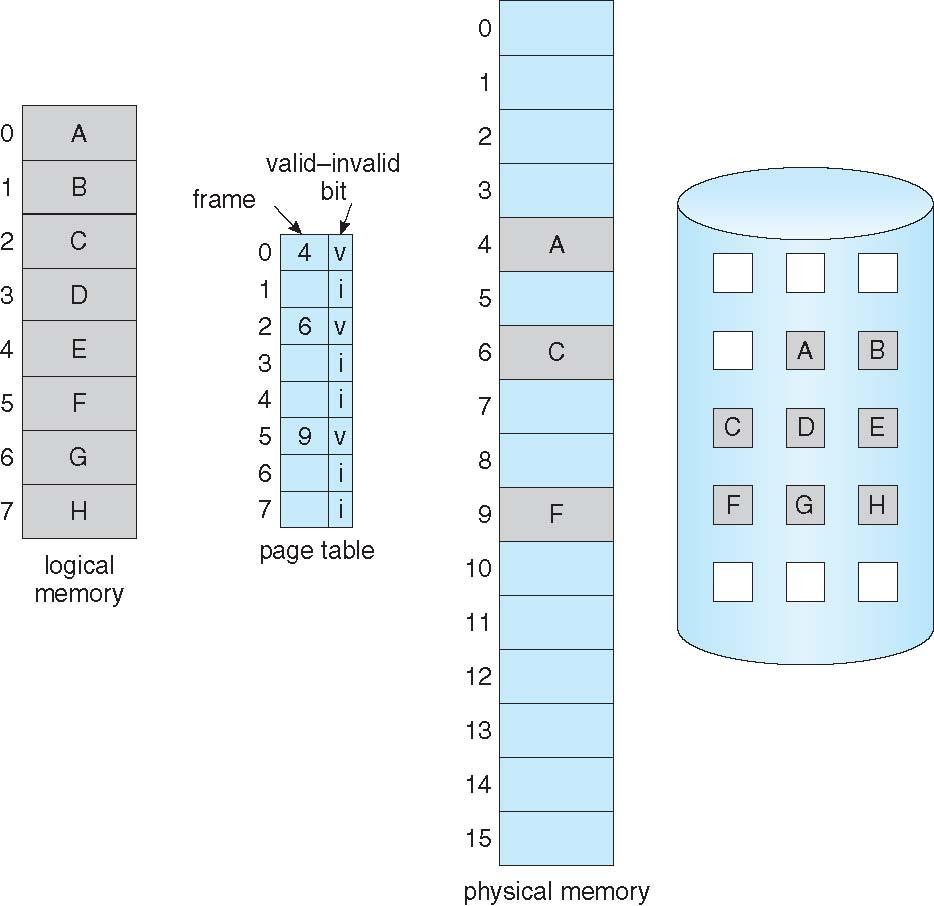
각 페이지 테이블 항복에는 Valid-invalid bit가 연결되어있으며 , V는 메모리내에서 메모리에 상주하는 I는 메모리에 없는 것을 표시한것이다.
초기에 valid-invalid bit는 모든 항목에서 i로 설정되게된다.
Page Fault
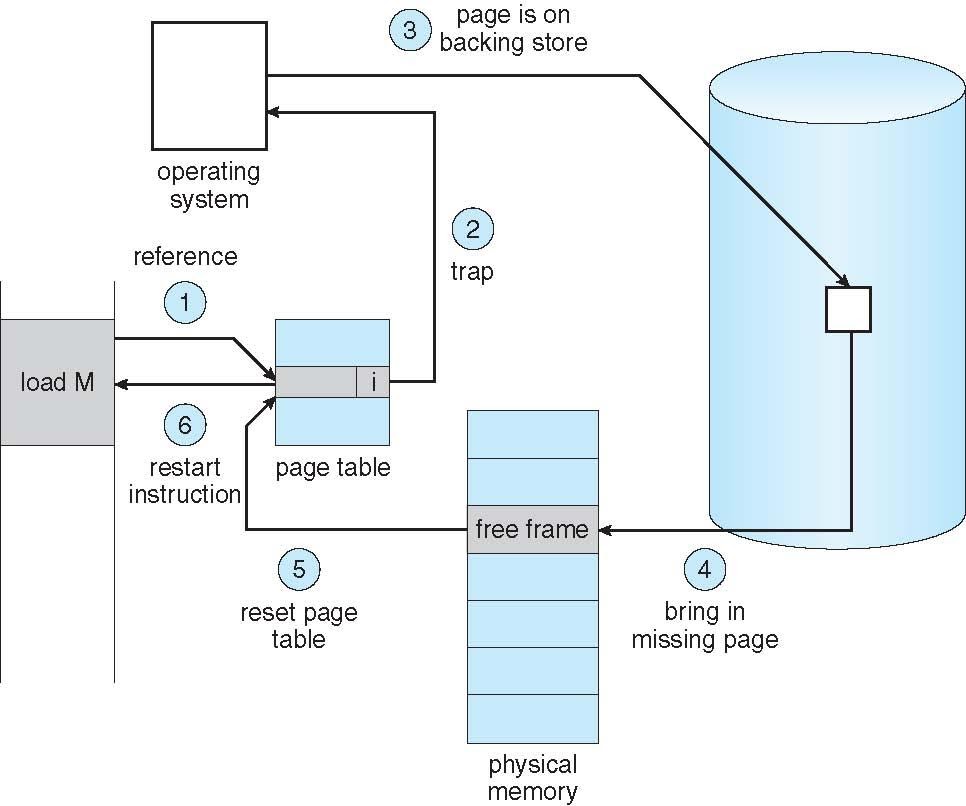
위에서 가상메모리공간과 MMU의관계사이에서 만약 첫 코드라인의 명령문이 물리적 메모리 공간을 초과하는 주소에 접근을 시도하게 된다면 Page Fault 현상이 발생하게된다. 라고하였다
Virtual address가 가르키는 page가 Physical memory에 없어서 OS에 알려주는 인터럽트
수행중인 Instruction을 변화된 상태를 되돌렸다가 Page fault처리가 끝난 후 instruction을 해야하는 것이 page Fault이다 .
자세하게 이야기해보자면 . 한 페이지의 참조가있을때 , 해당 페이지에 대한 첫 참조는 OS에의해 잡히게 되는데
Page Fault시 OS는 다른 테이블을 확인하며
1. 잘못된 페이지 참조시 작업을 중단하게되고
2. 메모리에 페이지가 없다면 Free Frame을 찾아 스케쥴된 디스크 작동을 통하여 페이지를 Free Frame으로 스왑하게된다.
3. 이후 메모리에 있는 페이지를 나타내는 valitation bit [ valid-invalid bit ] table을 리셋한후 valitation bit 를 v로 설정하게 된다 .
4. 마지막으로 페이지 폴트를 일으킨 명령라인을 다시 시작한다.
Demand Paging관점에서 Page Fault
만약 메모리에 페이지가 없는 상황에서 프로세스가 기동됐다는 가정을 고려해보자
1. OS는 메모리에 존재하지 않는 프로세스의 첫 명령에 대한 명령 포인터를 설정하게 된다
이상하지 않나? 메모리에 없는 프로세스의 주소를 셋팅 한다 ? 결론은 Page Fault 현상이 발생하게 된다 .
2. 처음 페이지에 접근시 OS는 다른 프로세스 페이지를 모두 접근하게 되는데 실제로 명령을 여러 페이지에서 액세스 할 경우가 있으며 1의 결과와 같은 상황 혹은 주소를 잘못참조하게 된다면 여러 페이지 Multiple Page fault 현상이 발생할 수 도 있다.
즉 메모리에 Fetch & Decode를 고려하여 2개의 숫자를 추가하고 . 결과를 다시 메모리에 저장하는것을 생각해보아야한다.
Demand Paging 의 성능
- 성능에는 주로 Service interrupt, Read page , Restart process 의 3가지의 절차가 영향을 끼친다
Page Fault Rate 는 0 <= p <= 1이고 p가 0이면 page fault 가 없다는 의미이고 p 가 1이면 모두 fault됐다는 의미이다.
EAT ( Effective Access Time ) = ( 1 - p ) * Memory access + p( page fault overhead + swap page out + swap page in)
Demand Paging Optimization
1. 최적화 관점에서 본다면 파일 시스템의 입출력보다 스왑 공간의 입출력이 조금더 빠르다고 볼 수있다.
왜냐하면 스왑은 larger chunks를 할당하여 파일 시스템보다 관리가 적게 필요하게 된다.
즉 프로세스 로드시 전체 프로세스 이미지를 스왑 공간에 복사 후 페이지 인 아웃을 하는게 더빠르다.
디스크의 바이너리 프로그램은 페이지 인을 요구하지만 Free Frame을 해재할때는 페이징 아웃을 하지 않고 버리기 때문이다.
또한 스왑공간은 익명의 메모리 ( 파일과 연결되지 않은 페이지( 스택과 힙) ) 는 메모리와 메모리에서 페이지 수정이 되지 않았지만 파일 시스템에 다시 쓰지 않은 페이지로 인해 스왑공간은 계속해서 사용할 필요가 있다.
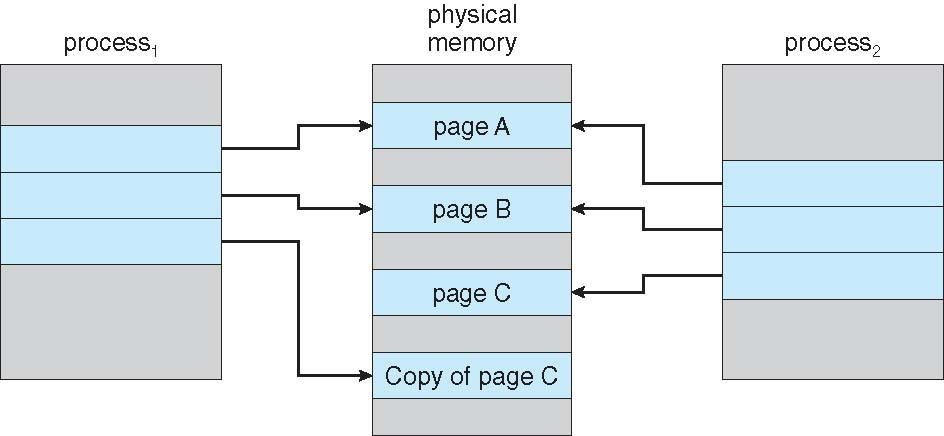
COW(Copy and Write )
cow를 사용하면 부모와 자식 프로세스가 처음에 메모리의 같은 페이지에서 공유할 수 있다.
부모와 자식 프로세스 중 하나가 공유 페이지를 수정하는 경우 페이지 복사가 이루어지고 COW는 수정된 페이지만 복사하므로 프로세스 생성면에서 효율성이 올라가게 된다.
일반적으로 Free page는 zero-fill-on-damand page의 풀에서 할당하게 되고 . 페이지 풀에는 빠른 Demand page 실행을 위해 항상 Free frame들을 가지고 있게 된다 .
만약 Free Frame이 없다면 프로세스 페이지에서 작업이 진행되고 커널, 입출력 버퍼 등에서부터 요구하게 된다.
이때 페이지 fault를 최소화 하는 방향의 Page replacement , Algorithm이 사용되게 된다.
Page Replacement
요구 페이징 시스템은 프로세스가 특정 페이지를 요구할 때 해당 페이지를 물리 메모리에 로딩한다.
메모리에 필요 페이지가 존재시 잘 진행되지만 없을경우 Page Fault문제가 발생하게된다.
여기서 하드디스크에서 페이지를 찾아 Free Frame에 로딩하게 되는데, 여기서 또다시 '페이지를 올릴 Free Frame'이 존재 하지 않을 경우 심각한 문제에 직면하게 된다.
요약하자면
1. 프로세스 실행중 Page Fault 발생
2. Page Fault 발생을 일으킨 Page의 위치를 Disk에서 Demand Paging하기위해 찾음
3. Memory의 빈 Frame 즉 Free Frame에 Page를 올려야하지만 모든 메모리가 사용중이라 빈 Frame이 없음 .
즉 Page Replacement를 포함하도록 page fault서비스 루틴을 수정함으로 메모리의 과잉 할당을 방지하고
[ 실제 메모리의 크기보다 더 큰 크기의 메모리를 프로세스나 시스템에 할당한 상황이다 ]
Dirty bit ( modify bit)를 사용하여 페이지 전송시 오버헤드를 줄여 수정된 페이지만 디스크에 기록하도록 함으로써
Page Replacement는 논리적 메모리와 물리적메모리의 분리를 완성시키게 된다.
즉 작은 물리적 메모리에 대용량의 가상메모리를 제공할 수 있게 되는 기법이다 .
하지만 이건 over allocatiing에 대한 일종의 메모리 관리기법이고 사용자가 눈치를 채지 못한다는 점에서 눈속임이라 볼수 있다.
물리적 한계가 존재하는 메모리량보다 더 큰 메모리를 사용자에게 사용할수 있다고 속이는것과 같다 .
이러한 기능 덕분에 Degree of Multiprogramming , CPU utilization, CPU Throughput의 증가하는 효과를 볼수 있다 .
over allocating을 요약하면
1. Memory의 anything한 프로세스를 종료
2. 프로세스 하나를 Swap Out ( 종료하던 프로세스의 Frame을 Free Frame으로 만들기위해 )
-> 1번의 경우 사용자의 입장에서 Paging system에 대해 알게될 가능성이 있기 때문에
2번을 선택하여 해결하게됨 .
Paging기법은 시스템의 효율성을 높이기 위해 OS차원의 성능차원과 밀접하기 때문에 사용자에게 해당 기능이 보이게 되면 안되는 문제가 있고 이에 따라 Page Replacement가 필요하게 됨 .
- Page Replacement의 기본
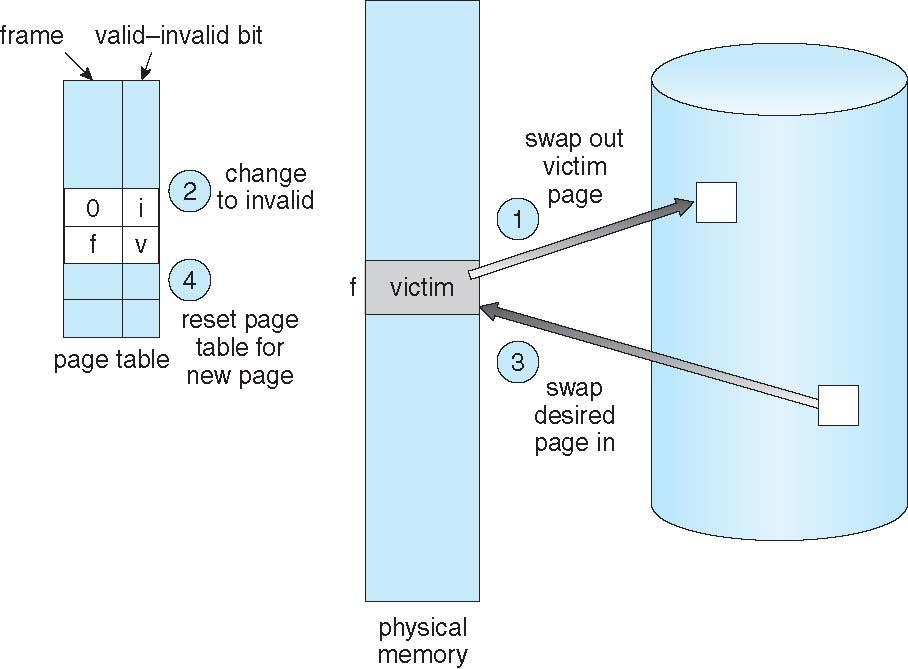
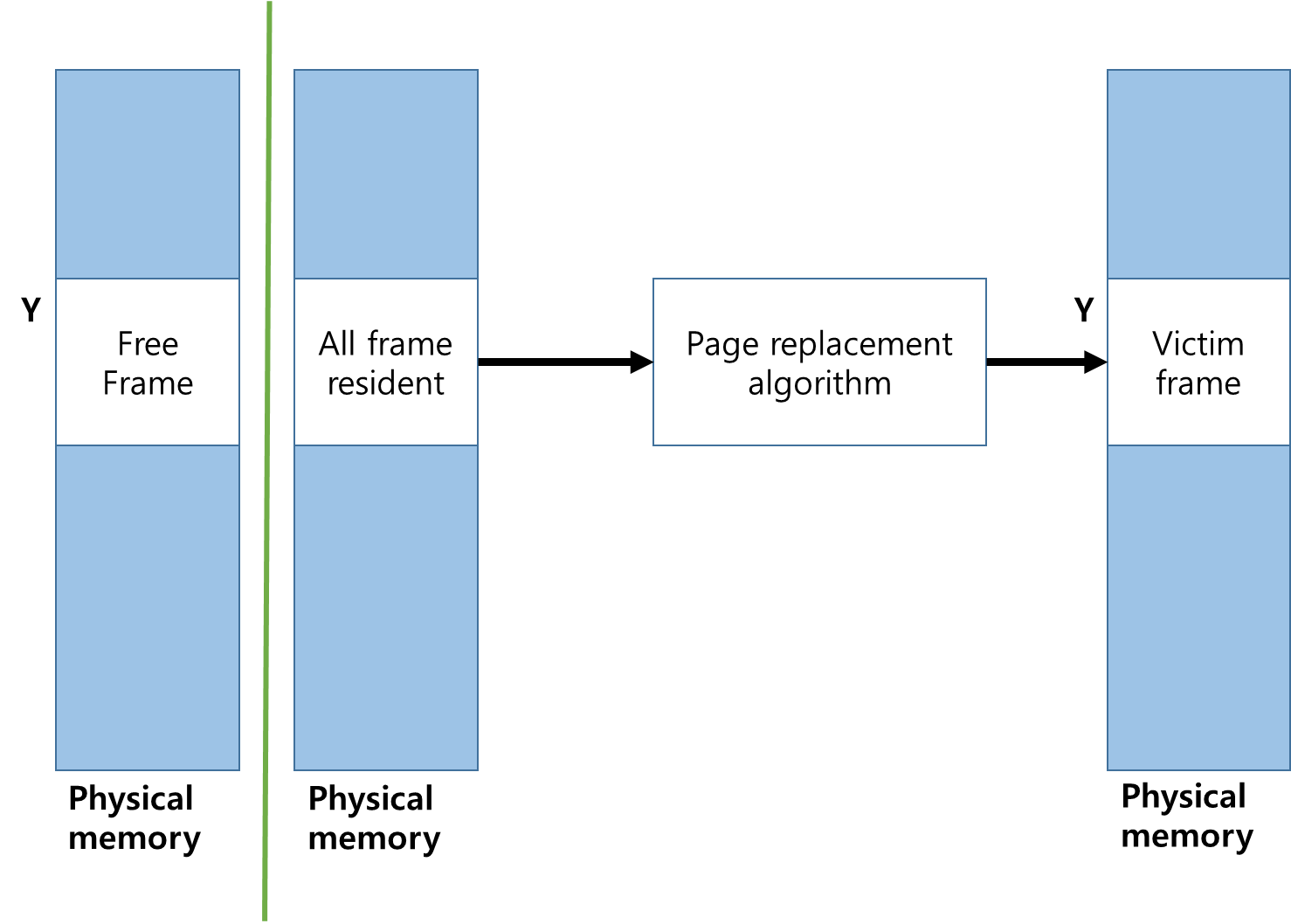
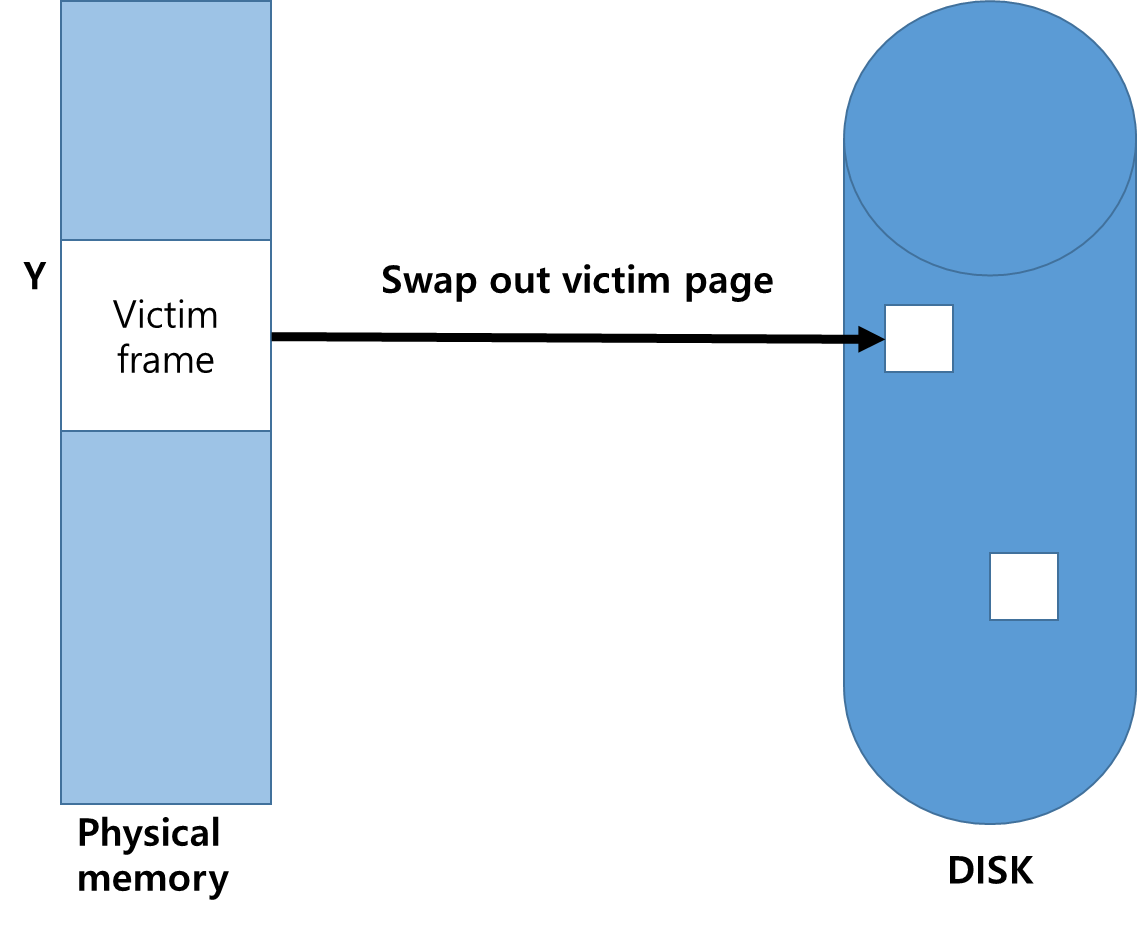
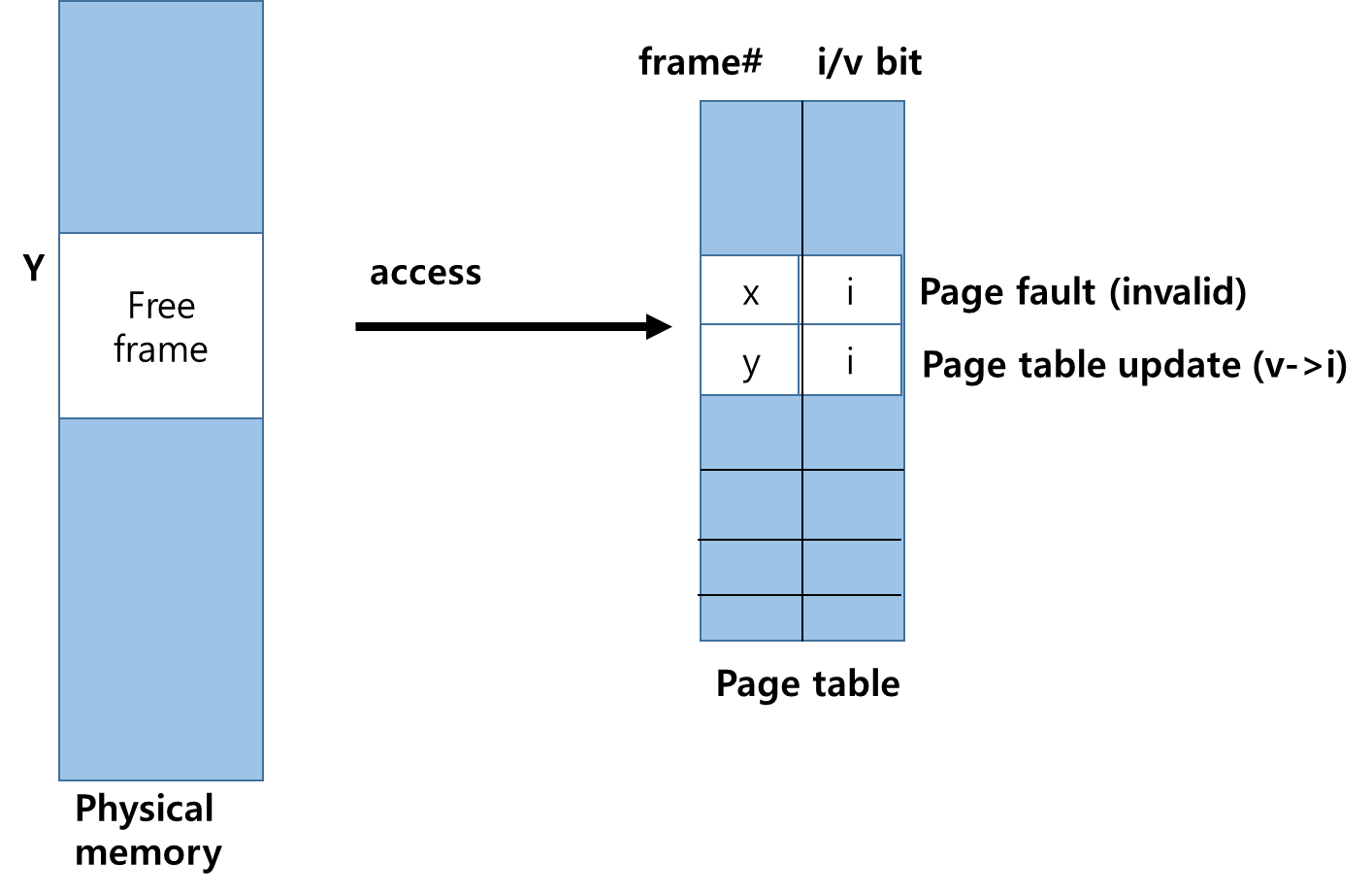
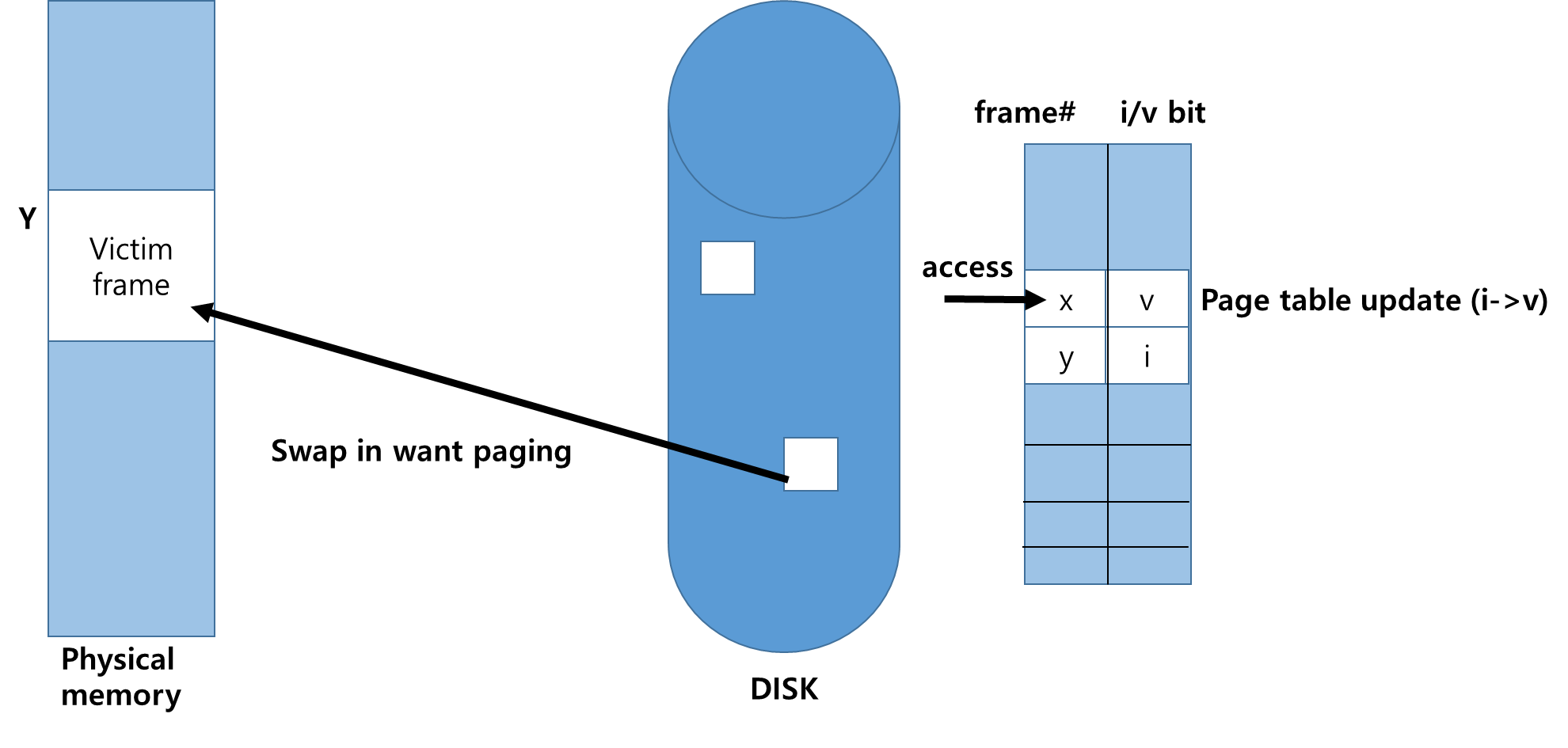
1. Memory Over-allocating 이 발생하게 되면 프로세스 하나를 Swap Out하여 Free Frame을 확보 해야한다 .
Page Replacement의 절차는 아래의 과정을 따르게된다 .
0. 프로세스는 실행 도중 Page Fault가 발생하게 되면 Page Table에 Frame에 접근하여 bit를 invaild bit로 바꾸게된다.
[ 테이블에 접근시 모든 접근이 legal한 접근이라고 가정하게 된다 ]
1. 디스크에서 원하는 페이지의 위치를 찾는다. [ Page Fault를 발생시킨 Page의 위치를 Disk에서 찾는다 ]
이후 물리 메모리에 Free Frame이 있는지 접근하여 확인하게 된다 .
만약 Free Frame이 존재한다면 해당 Frame을 사용하게 되지만
없다면 victim frame을 선정후 victim page의 내용을 Disk에 기록하며 원하는 페이지를 Free Frame으로 가져오게 되면 Page및 frame table을 업데이트하게된다.
[ 페이지 교체 알고리즘을 사용하게 되며 뿐만아니라 Frame에 잔존하는 데이터가 남아있다면 victim frame을 디스크에 쓰게된다 ]
** page repalcement의 overhead를 최소화 해야 하는 방향으로 해야함 .
위의 그림에서 보는것처럼 페이지를 교체시 입출력 연산은 overhead가 크다는 점이있어 하드웨어적 도움으로 overhead를 줄이고 변경 비트를 모든 페이지마다 둔후 어떤 페이지가 교체 대상이 된다면 bit를 체크해야한다 .
bit가 set이 된상태일때 , 이 page 내용이 disk상의 page내용과 달라졌음을 뜻하게 되며 page가 메모리로 올리온 이후 한번이라도 수정이 일어났다는 근거가 된다. 따라서 메모리를 내려갈때 디스크에 기록을 해야하는 이유가된다.
만약 변경비트가 clear라고한다면 디스크상의 페이지 내용과 메모리상의 페이지가 같다는것을 의미하게 되며 메모리를 내려갈때 디스크에 기록할 필요가 없어 진다.
Paging & Frame replace algorithm
프레임 할당 알고리즘은 각 프로세스에 제공할 프레임의 수 와 교체할 프레임을 결정하게 된다.
페이지 교체알고리즘의 목표는 첫 접근과 재접근시 가장 낮은 Page fault 비율이 목표이며
스트링을 참조하는 특정메모리영역에서 사용해보고 특정 문자열(문자열은 전체 주소가 아닌 페이지 번호) 에의한 page fault의 수를 계산하여 알고리즘을 평가하게된다.
여기서 동일한 페이지에 대해 반복 접근은 Page fault를 일으키지 않으며 사용가능한 Frame의 수가 결과에 영향을 미친다.
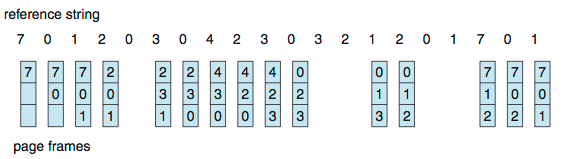
페이지 참조 문자열 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1을 기반으로 알고리즘을 소개해보겠다.
FIFO Algorithm
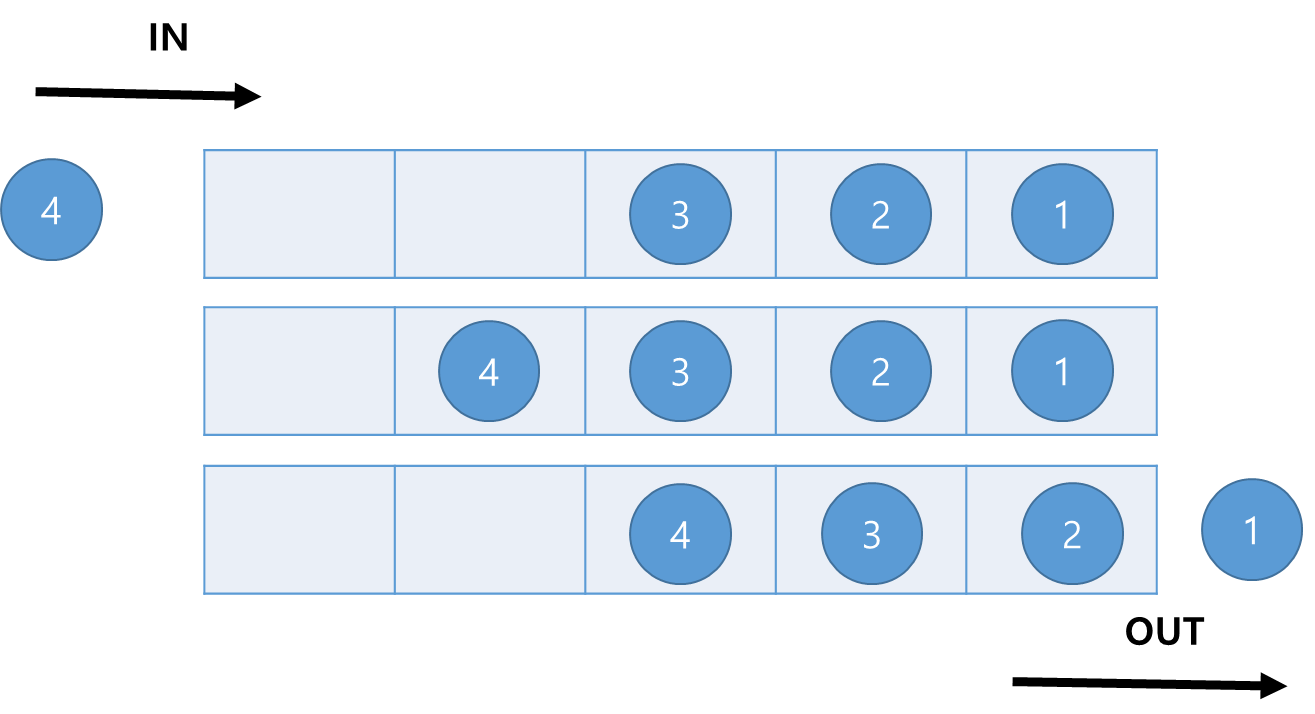
예시에 사용되는 Reference String은 위의 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1 기반이다.
FIFO(First in First Out) 알고리즘은 가장 쉬운 알고리즘이다. FIFO그대로 가장 먼저 메모리에 적재된 순서대로 가장 먼저 나가는 알고리즘으로 이해하면된다.
이것을 운영체제와 페이지 교체에서 생각해본다면 메모리에 올라온 가장 오래된 페이지( 가장 먼저 메모리에 할당된 페이지 )를 Victim으로 설정하여 교체 한다. 해당 알고리즘을 수행하기 위해서는 각 페이지에 올라온 시간정보를 페이지에 저장하고 있거나 페이지에 올라온 순서를 큐에 저장하는 방식등을 고려하여 사용할 수 있다.
위의 예에서 보면 프로세스당 한번에 3페이지가 메모리에 있을수 있는 조건이지만 7이 가장 먼저 들어온이후 7,0,1번 페이지에 대해 페이지 결함이 발생하고, 이 페이지는 순서대로 프레임에 할당된다 . 가장 오래되었기때문에 문자열 7을 2로 이후에 0을 3으로 1을 0으로 교체하는 루틴을 볼수있다.
하지만 활발하게 사용중인 페이지를 계속해서 교체하게 될경우 Page Fault가 높아지게 되고 성능이 떨어질 가능성이 존재하게 된다
FIFO ( Belady's Anomaly )
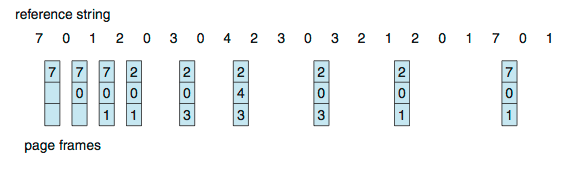
여기서 만약 reference string을 1,2,3,4,1,2,5,1,2,3,4,5를 참조해보자
프레임이 3개일때보다 프레임의 수가 4개일때 프레임수가 많지만 결함은 더크게 발견됐다.
일반적으로 더 많은 프레임을 보유시 성능이 향상된다는 생각이 있지만 일부 페이지에서 반대의 결과가 나오는 현상을
Belady's Anomaly라고한다 .
Optimal Page replace Algorithm
위으 Belady's Anomaly의 예외상황이 발견된 후 가장 적은 페이지 결함을 나타내고 Belady's Anomaly가 발생하지 않는 최적의 교체알고리즘이 연구되었을 것이다.
OPT알고리즘은 앞으로 장기간(가장 오랜시간동안) 사용하지 않을 페이지를 Victim으로 선택하여 교체하는 알고리즘이다.
여기서 구현관점에서 본다면 프로세스의 입장에서 페이지의 정보를 가지고 있어야한다 예를들면 어떤 페이지가 앞으로 사용할 페이지인지 알아야 장기간 사용하지 않을 페이지를 알아야 장기간 사용하지 않을 페이지를 교체할 수 있다는 말이된다. 이후 해당 알고리즘은 알고리즘이 얼마나 잘 수행하는지 측정하는데 사용하게 된다.
예시에 사용되는 Reference String은 위의 7,0,1,2,0,3,0,4,2,3,0,3,0,3,2,1,2,0,1,7,0,1 string 이다.
1. 해당 알고리즘은 가장 오랫동안 사용하지 않을 페이지를 미리 알고 교체하기 때문에 모든 페이지 교체 알고리즘 중 가장 페이지 교체수가 적다는 장점이있다.
2. 프로세스 스케쥴링의 SJF 알고리즘과 마찬가지로, 위에서 말했듯 문자열의 전체 내용을 미리 알고있어야 하는 전제가 필요하기 때문에 구현할 수 없다. ( 어렵다? )
LRU( Least Recently Used ) Algorithm
LRU는 가장 오래 사용하지 않는 페이지를 교체하는 알고리즘이다.
Optimal 알고리즘은 실제 구현이 불가능하기 때문에 , 최적 알고리즘의 방식과 비슷한 효과를 낼 수 있는 방법을 사용한 다.
만약 과거 참조 내용을 활용하여 가까운 미래의 참조값을 추정할 수 있다면 가장 오랜기간 사용되지 않는 페이지를 교체할 수 있다는 접근방법이다 .
즉 LRU알고리즘은 각 페이지가 마지막으로 사용한 시간을 사용하여 페이지 교체가 필요시, 지금까지 가장 오랜기간동안 사용하지 않은 페이지를 Victim으로 설정한다.
LRU알고리즘은 OPT알고리즘보다 페이지 교체 횟수가 높지만 FIFO알고리즘보다 효율적이다.
FIFO와 OPT의차이는 FIFO는 페이지가 메모리에 옮겨지는 시간을 사용하며 , OPT는 페이지가 실제로 사용된 시간을 사용하는 차이가 존재한다.
LRU 알고리즘은 많은 운영체제가 채택하는 알고리즘이며, 좋은 알고리즘이라고 평가 받고있다.
마지막 사용시간 결정방법은 하드웨어적 지원이 필요하게된다.
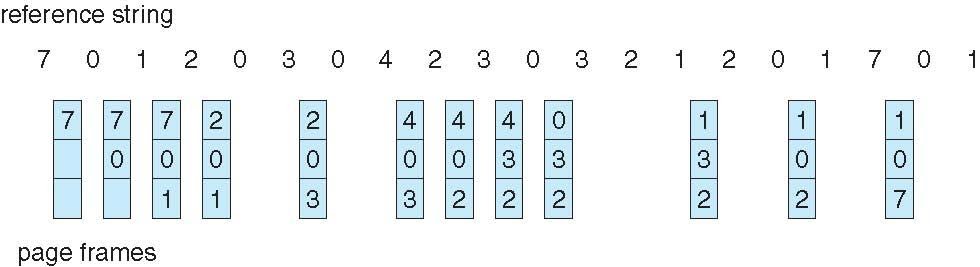
예시를 보면 그래서 처음 7, 0 , 1,에서 결함이 발생하고 , 페이지가 순서대로 할당된다.
LRU알고리즘에서 중요한 점은 페이지 접근 시점이다 .
예를들면 처음 7,0,1을 참조하게 된다면 7,0보다는 1이 최근에 참조한 페이지이다. 따라서 , 만약 이때 교체가 이루어 지게된다면 7이 밖으로 내보내진다.
- 구현 ( LRU )
1. Counter를 사용한 구현
-모든 페이지 항목에는 카운터가 존재한다. 이 항목을 통해 페이지를 참조할 때마다 시간을 페이지 테이블 항목에 가장 마지막 사용시간을 기록하게 된다. [ CPU의 Clock이나 Counter를 사용 ) .
이 방법은 항상 페이지가 마지막으로 참조된 시간을 유지해주어야 하며 변경이 됐을때 [페이지를 변경하는 경우 카운터를 확인하여 가장 작은 값을 찾아 변경하게 된다] Clock의 오버플로우 역시 고려대상이된다.
2. Stack을 사용한 구현
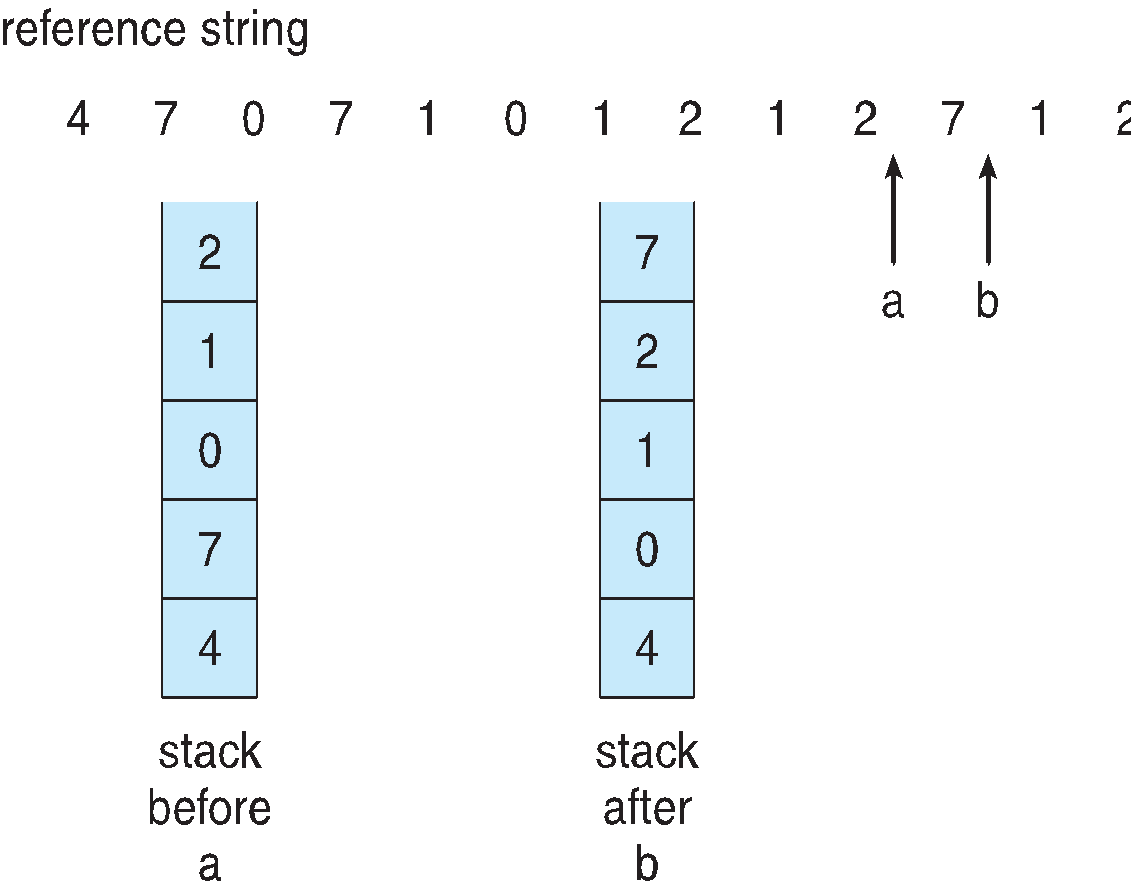
- 페이지 번호들을 이중 링크 스택 구조로 저장하여 구현하는 방법이다 .
페이지가 참조될때, 스택에서 페이지 번호를 삭제하고 다시 Push하게된다.
(페이지 번호는 스택의 (top)맨위에 존재하게 된다 ).
이방법은 즉 최근 참조 페이지는 Stack의 Top에 존재하게 되고 , 가장 오랜시간 참조되지 않은 페이지는 Bottom에 존재하게 된다.
LRU Approximation Algorithm
LRU알고리즘을 구현하기 위해선 적합한 하드웨어의 지원이 요구된다.( 특수한 하드웨어가 필요하고 Still slow함 )
하지만 하드웨어에서 지원을 받을 수 없다면 다른 페이지 교체 알고리즘을 사용해야 한다.
즉 기존 LRU와는 다르게 H/W지원 없이 Reference bit만으로 구현하는 알고리즘이다.
많은 시스템에서 이런 상황시 참조 비트(Refference bit)를 지원하고 참조 비트는 페이지 테이블 항목에 존재한다.
참조 비트는 페이지 참조시 하드웨어에 의해 설정되게된다.
참조 비트는 기동시 0으로 초기화 되어있으며, 사용자 프로세스가 실행되면 참조되는 페이지들에 대한 참조 비트는 1로 설정된다. 이 참조 비트를 통해 어떤 페이지가 프레임에 할당된 후 사용되지 않았는지 알 수는 없다.
하지만 페이지가 사용된 순서는 알 수 있으므로, LRU-Approximation 페이지 교체 알고리즘의 기반이된다.
1. 페이지가 비트를 연관시키는 초기에는 비트값은 0
2. 페이지가 참조될 때 비트가 1로 설정됨.
만약 참조비트가 0인 초기화된값이 존재한다면 임의로 교체를 진행함.
순서는 알수없음,
additional reference bit algorithm
참조 비트를 일정 시간 간격으로 기록함으로써 페이지 참조 순서에 대한 추가적인 정보를 얻을 수 있다.
Page Table내 각각의 Page에 8bit 참조 비트가 존재하고 8bit(1Byte)를 각 페이지마다 따로 저장후 , 일정 시간 간격으로 참조 비트를 기록하는 방식이다.
총 8번의 시간 간격동안 참조 비트를 기록시 ,일정 시간 간격마다 Access 되었던 페이지들의 비트들을 오른쪽으로 Shift하는 연산을 하게된다 예를들어 기록된 비트가 00110010 이라면 2,5,6번째에서 참조가 발생했다는 의미가 되고 8번 이후의 시간 간격동안 기록되는 참조 비트는 기존의 8비트 수를 Right shift하여 기록하게 된다.
따라서 가장 큰 값의 비트를 가진 페이지가 최근 Access 되었다는 것을 알수있고 참조 비트 기록을 정수로 변환시 , 가장 오랜 시간동안 참조 되지 않은 페이지는 가장 낮은 정수값을 가지게 되는것을 알수있어 해당 비트를 가진 페이지들이 Victim Page로 선택되어 같은 값들에 대해서는 FIFO 알고리즘을 이용하여 Victim을 고르게 된다 .
만약 동일 정수값을 가지는 페이지가 여러 개 존재한다면, FIFO알고리즘 등으로 하나의 페이지를 Victim으로 선택한다.
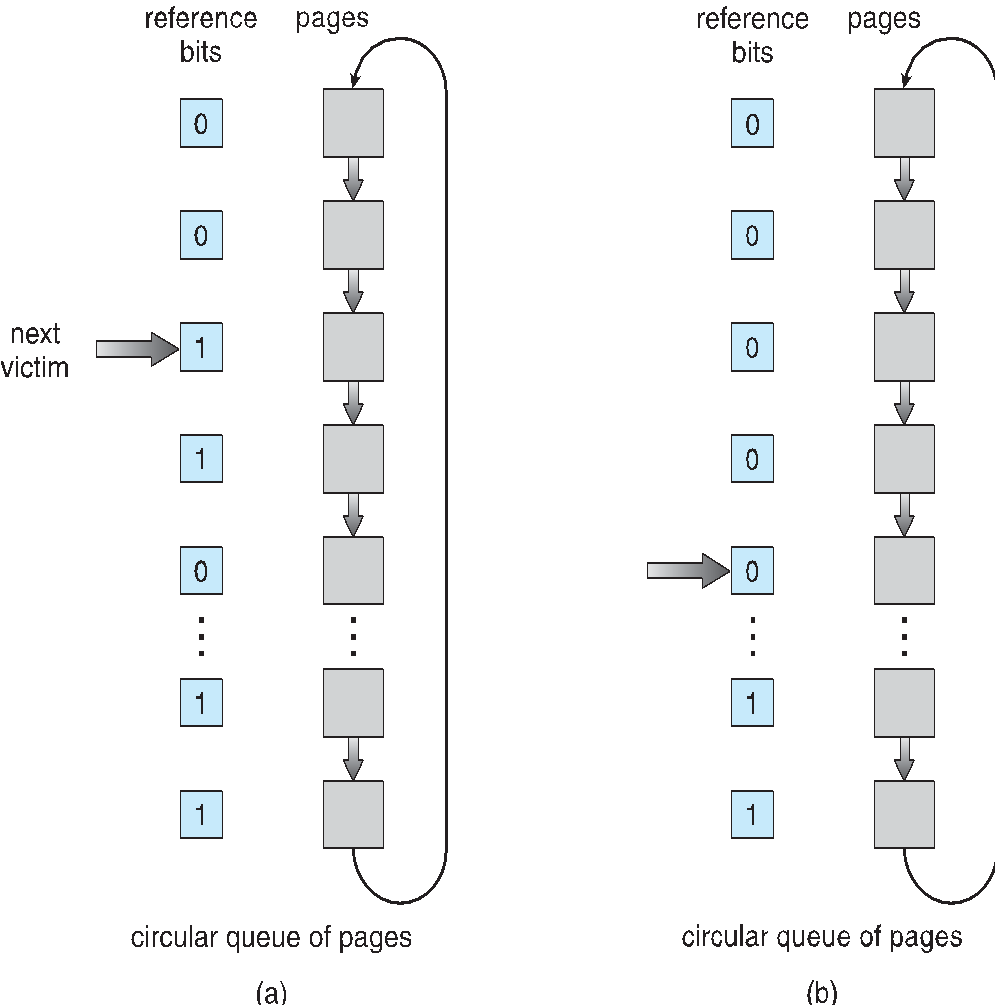
Second-Chance algorithm.
Second-Chance 알고리즘은 일반적으로 FIFO 알고리즘 기반이다.
페이지가 선택됐을때, 그 페이지를 교체하지 않고, 페이지의 참조비트를 참고하게 된다.
Page table의 각 Page에는 1 bit의 참조비트가 존재하게 되고 초기값은 0이고 Access시 1로 바뀌게된다.
FIFO알고리즘을 기반으로 하고있기때문에 참조비트가 1이라도 선택이 될 수 있다.
만약 참조비트가 0이라면 해당 페이지를 교체한다.
그러나 참조 비트가 1이라면, 최근에 Access되었다는 판단으로 해당 페이지는 교체되지 않고 한 번의 기회를 더 얻게 된다.
이 순간 해당 페이지의 참조 비트는 0으로 초기화 되며, 다른 Victim 페이지를 찾게된다.
만약 모든 Page의 Reference bit가 1이라면 결국 FIFO방식으로 작동하게 된다.
만약 FIFO 알고리즘을 통해 그 페이지를 다시 선택하였을때, 그 페이지의 참조 비트가 또 1이라면 그 페이지는 교체되지 않는다.
즉 FIFO 알고리즘을 통하여 페이지가 선택됐다면 그 페이지의 참조비트가 1인 페이지는 교체되지 않는다.
참조 비트가 0인 페이지를 찾을 때까지 페이지를 계속 순환하여 탐색하기 때문에 Circular Queue를 통해 구현되게 된다.
4. Enhanced Second - Chance Algorithm
reference bit 와 modify bit를 함께 사용하여 Second chance알고리즘을 개선하여 Victim 페이지를 찾는 알고리즘이다 .
bit구성은 Reference 와 modify bit을 쌍으로 가지고 있고 ,
(0,0) 최근에 사용되지 않았고 , 수정이 되지 않은 페이지로 교체하기 가장 적합한 페이지다.
(0,1) 최근에 사용되지 않았지만, 수정이된 페이지로 이 페이지를 사용하기 위해서는 교체하기 전에 디스크에 페이지를 써야 하기 때문에 , 교체하기에 좋은 페이지는 아니다 .
(1,0) 최근에 사용했지만 수정되지 않은 페이지로 다음 순환에서 교체할 가능성이 높은 페이지다 .
(1,1) 최근에 사용되었고 수정이 된 페이지로 다음 순환에서 교체될 수 있지만, 교체되기 위해서는 페이지를 디스크에 써야하는 페이지이다.
모든 페이지 테이블을 전부 검색해야하는 단점이 존재하긴 한다 .
Counting Algorithm - LFU(Lease Frecuently Used ) , MFU ( Most Frequently Used )
페이지 참조시 Access된 횟수를 Page Table에 각 Page에 현재까지 참조된 횟수를 저장하여 카운팅후 Victims Page를 결정하는 방법이다. 두 가지의 알고리즘 LFU와 MFU가 존재한다.
1. LFU
LFU 알고리즘은 횟수가 가장 적은 페이지를 Victim 페이지로 선택하는 것이며 Access횟수가 적다는 것은 앞으로 선택이 안될 것 이라는 판단을 하는 알고리즘이다 . 즉 가장 적은 카운팅 수의 페이지를 교체하는 알고리즘이다.
만약 교체 대상인 페이지가 여러 개 일 경우, LRU알고리즘을 따라 가장 오래 사용되지 않는 페이지로 교체하게 된다.
LFU알고리즘은 초기에 한 페이지를 집중 참조 후 다시 참조하지 않는 경우 앞으로 사용하지 않아도 초기사용시 참조 수가 높아 메모리에 계속 할당된 경우 문자게 될수 있다 .
LRU와 LFU의 차이로는
LRU는 시간적으로 사용한지 가장 오래된 페이지를 교체하는 방식이며
LFU는 횟수를 기준으로 가장 적은 페이지를 교체하는 방식이다 .
2. MFU
MFU알고리즘은 LFU와믄 반대로 . 횟수가 가장 많은 페이지를 Victim페이지로 선택하는 것이며 참조 횟수가 많다는 점은 지금까지 많이 참조 했으니 이제 사용하지 않는다는 판단을 하는 알고리즘이다. 즉 가장 많은 카운팅 수의 페이지를 교체하는 알고리즘이다. count가 가장 작은 페이지가 방금 들어왔을 것이고, 아직 사용되지 않았다는 판단에 기반을 둔다.
Page-Buffering Algorithm
Page Replacement Algorithm의 처리속도를 높이기 위해 만든 기법이다.
필요할 때 프레임을 사용할 수 있도록 다수의 Free Frame을 풀(Pool)에 넣어 항상 Free Frame을 가지고 있다가 페이지 교체가 필요할 때 Free Frame에 새로운 페이지를 읽고 , 희생할 프레임을 찾아 디스크에 기록후 Free Frame 풀에 추가하는 알고리즘이다 . 단 Fault time에는 찾을 수 없다 .
Allocation of Frames
동시에 작업이 이루어지는 다중 프로세스 환경에서 메모리자원은 제한적이다 . 즉 효과적으로 사용하기 위한방법이 필요하게된다 .
뿐만아니라 프레임수를 정하여 프로세스의 메모리 독점이나 starvation등의 이슈를 사전 방지해주어야 한다 .
그렇기 때문에 Demand Paging시 프로세스는 작업해야할 부분에 있어서 최소한의 Frame을 할당하게 된다.
최소한의 프레임을 할당하면
1. 프로세스당 할당 프레임소의 감소시 page fault발생 확률이 늘어나게 되므로 성능이 감소하는 상황이 발생한다.
만약 운영체제 시스템상 명령어 실행 완료 전 page fault가 발생하게 된다면 해당 명령어는 재실행을 필요하게된다.
여기서 Frame을 할당해주는 방법으로1. static allocation (fixed allocation )방법중 Equal allocation , proportional allocation , priority allocation등 세가지 방법을 소개하고 2. dynamic allocation 방법으로 Working set model, page fault frequency , etc등의 방법이 있다.
Static Allocation ( Fixed Allocation )
프로세스를 실행하기 전 프로세스의 사이즈만 보고 할당방법을 결정하는 방법이다.
1. Equal allocation:
모든 프로세스에게 동일한 비율의 프레임을 할당하는 방법이다.
예를들어 100Frames을 5개의 프로세스에게 할당하게 된다면 각 프로세스에게 20 frame을 할당하게 된다.
만약 # num of total frame / # num of process = num of frame allocation 으로 프레임을 할당하게 되는데
만약 102 frame / 5 process 같은 상황에서는 2개의 프레임이 남게된다
이때 남는 나머지 프레임은 buffer pool에 넣어 저장해두고 필요시 꺼내쓰도록 세팅하게된다.
2. Proportion allocation :
용량이 클수록 프레임수를 비례하게 할당하는 방식이다. 즉 프로세스의 크기에 비례하게 프레임을 할당하게 된다.
aI = Allocation for pi = si/s * m 프로세스에 할당하는 프레임의 수이다.
여기서 Si는 프로세스 pi의 사이즈.
S 는 si의 총 합 . 즉 ∑si 이다.
m은 프레임의 총 수를 나타낸다 .
m = 64, s1= 10 , s2 = 127 인 시스템이 존재한다고하면
M =64, S = 137 이므로 할당 A1 = 10 / 137 * 64 근사적 으로 4의값 , A2 = 127/137 * 62 = 57의 프레임을 할당받게 된다.
Global vs Local allocation
- Global replacement
- 일반적으로 더 많이 사용하는 방법으로 전체 프레임에서 Replacement frame을 프로세스가 고르게된다.
- 즉 메모리 상의 모든 프로세스 페이지에 대한 교체작업을 수행하게 된다.
- FIFO, OPT, LRU등 Victim을 정할때, 모든 메모리에 올려져 있는 Frame을 다 확인 후 교체를 하게된다.
- 그러나 자주 사용하는 프로세스 관점에서는 효율적이라 볼 수 있지만 . 독점이슈가 발생할 가능성이 많다.
- Local replacement
- 각 프로세스는 할당된 프레임 set에서만 고를 수 있도록 한다.
- 즉 메모리 상의 자기 자신의 프로세스 페이지에 대해서만 교체 작업을 수행하게된다.
- 다시말하면 요청이 들어온 page p1이라고한다면 메모리상의 frame중 p1 frame만 교체 대상이 된다.
- 자주 사용하는 프로세스들이 계속된 Page fault와 replace가 발생할 수 있다.
Non Uniform Memory Access ( NUMA )
멀티프로세서 시스템에서 사용되고 있는 컴퓨터 메모리 설계 방법중의 하나로 메모리에 접근하는 시간이 메모리와 프로세서간의 상대적 위치에 따라 달라지게된다.
NUMA구조에서 프로세서는 자기의 로컬메모리에 접근할 때 원격 메모리에 접근할 때보다 더 빠르다.
원격메모리는 다른 프로세서에 연결되어 있는 메모리를 말하고 로컬메모리는 자기 프로세서에 연결되어 있는 메모리를 말하게된다.
NUMA는 SMP(Shared Memory Multiprocessor ) 아키텍처에서부터 확장된 구조이다.
* SMP는 두 개 또는 그 이상의 프로세서가 한 개의 공유된 메모리를 사용하는 다중 프로세서 컴퓨터 아키텍처이다.
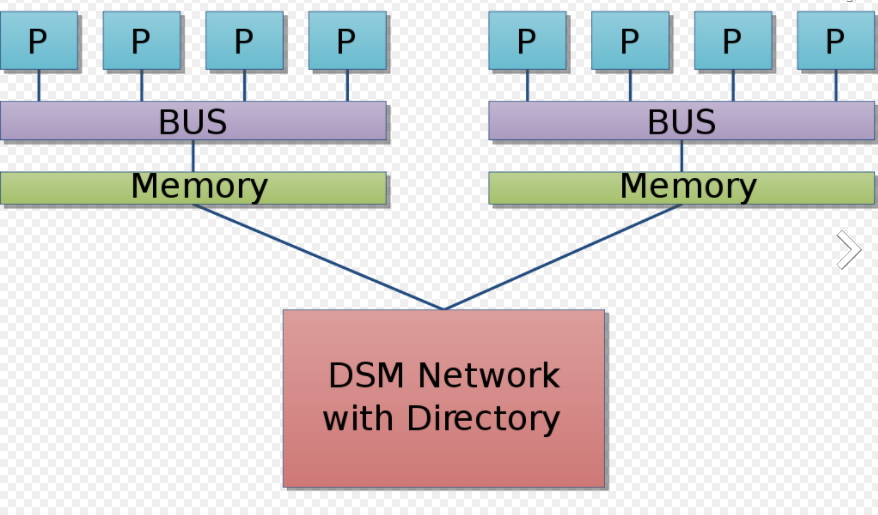
그럼 Process의 계보를 살펴보면서 NUMA에 관해 간략하게 설명해보고자 한다 .
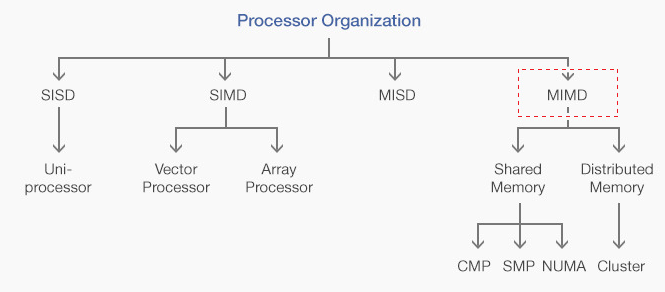
MIMD (Multiple Instruction , Multiple Data Streams )는 여러 명령어들의 여러 데이터를 동시에 처리하는 방식으로 , 멀티 프로세스를 포관하는 구조이다. 여기서 Shared memory중 SMP구조와 NUMA를 살펴보면
SMP (Symmetric Multi processor )
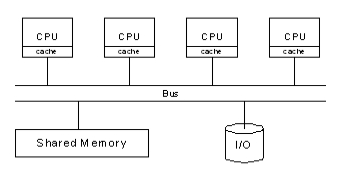
공유메모리 시스템의 가장 대표적인 형태로 , 다수의 CPU는 메모리와 I/O를 서로 공유하는 구조이다.
대칭구조를 지니기 때문에 모든 프로세스가 동일한 기능을 수행하게 된다.
하지만 한번에 한개의 프로세서만 동일 메모리에 접근이 가능하기때문에 타 프로세서들은 대기해야하는 문제가 생긴다 (성능상 느리거나 데드락이 발생할 수도...있겠다. ).
NUMA ( Non-Uniform Memory Access )
NUMA구조는 SMP의 타프로세스의 대기이슈를 해결하기 위해 제안된 모델이다.
각 CPU가 독립적인 지역 메모리 공간을 가지고있기 때문에 상대적으로 SMP보다 메모리 접근성이 용이하다.
이러한 구조적 장점으로 모든 프로세서는 로컬메모리에 동시접근이 가능하게 되었다.
즉 데드락 상황이 발생하지 않는다.
그러나 원격 메모리(프로세서 메모리)에 접근할 경우 링크를 통하여 메모리 접근으로 인해 느리다는 단점이 존재한다.
NUMA구조는 공유메모리의 관점에서 본다면 동일한 캐시메모리의 일관성유지가 어렵기때문에 NUMA시스템은 ccNUMA형태의 하드웨어적 방법으로 구현되어있다.
그렇기 때문에 메모리 관리면에서 최적의 방식으로 CPU에가장 가까운 메모리를 할당해주는 방식으로 정리할 수 있다.
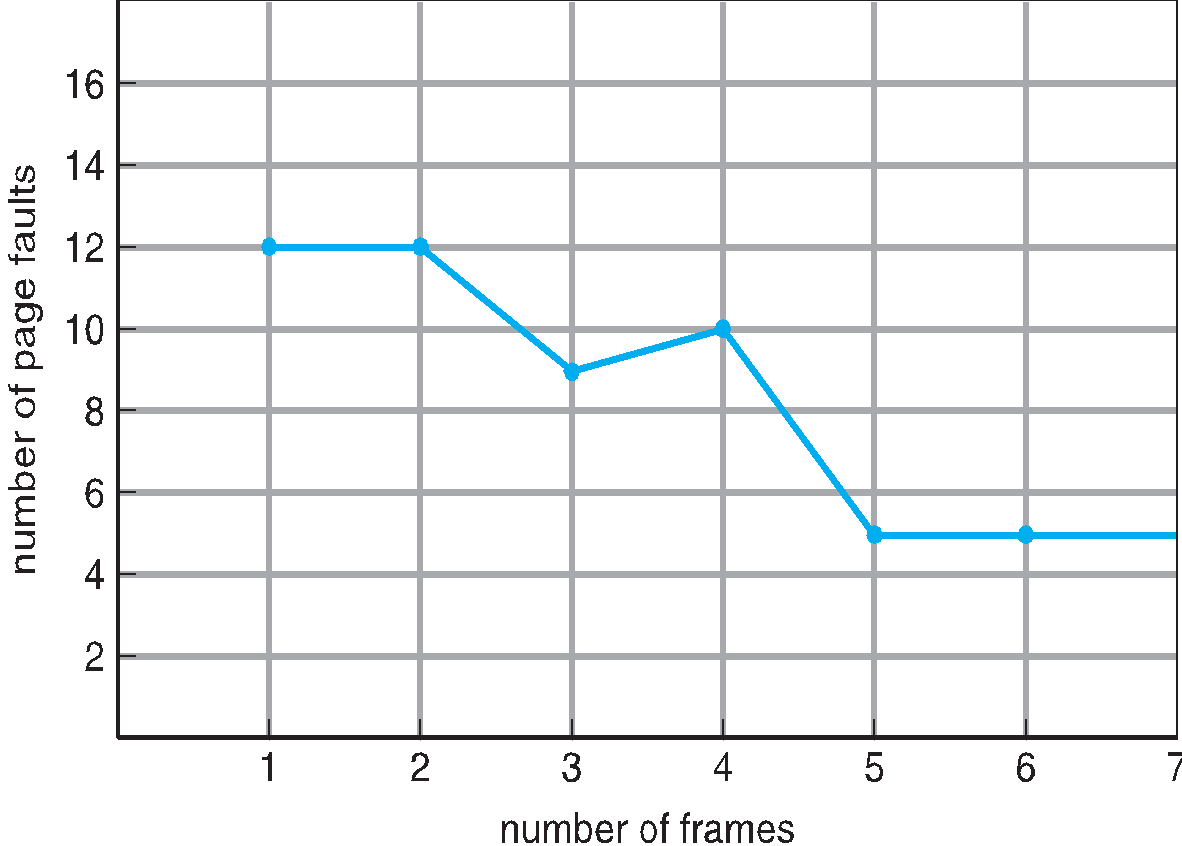
Thrashing
만약 프로세스에 Page가 충분하지 않게되면 Page를 가져오는 과정에서 Page-fault현상이 아주 많이 일어난다.
주로 프로세스가 Swap in out으로 작업이 많아지게 되는 경우 주로 발생하는 문제로.
일반적으로 메모리에 올라가는 프로세스 수가 증가할수록 cpu의 사용률은 올라가게된다. 여기서 허용할 수 있는 메모리가 초과되는경우 Page fault가 발생하게 된다. 이러한 현상은 CPU성능을 낮은성능으로 이어지게 만든다.
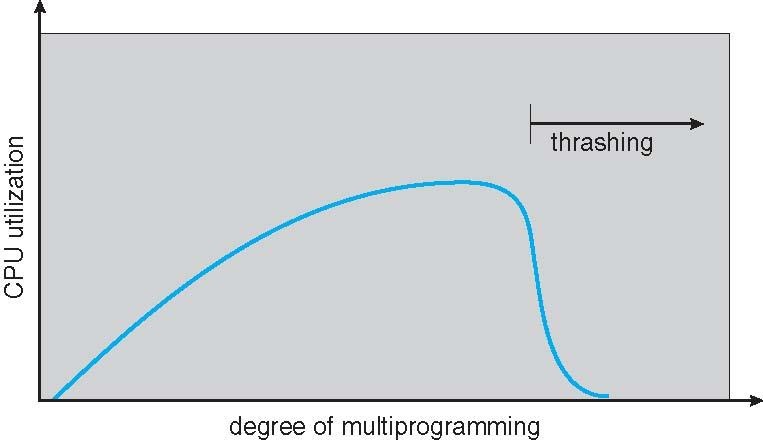
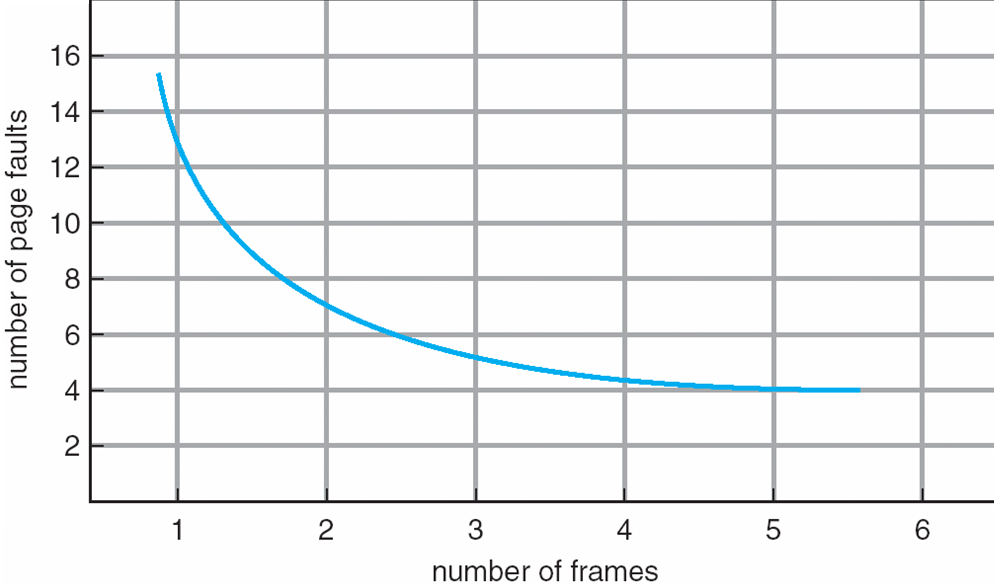
이러한 현상에 대한 프로세스당 CPU이용률을 그래프로 나타내면 위와같은 그래프가 나타나게되며
프로세스가 증가할 수록 메인 메모리의 Free frame의 수는 줄고 프레임이 가득차는 경우에도 프로세스가 증가할때
메모리와 backing store사이 page in/out작업이 발생하게 되며 프로세스 의 수예따라 비례하게 작업량이 증가하게된다.
그런데 Page in/out 은 디스크 I/O를 사용하지 않으므로 작업이 많아질수록 cpu는 아무것도 하지 않는 상태가 된다.
즉 프로세스 개수 증가 -> cpu 이용률 증가
. 일정 범위를 넘어서는경우 CPU이용률 감소
. 빈번한 page in/out으로 인해
. Thrashing i/o 시간 증가 .
Thrashing 문제 해결방안 (Demand Paging 기법)
1. Global replacement 보다는 local replacement
[ Demand paging 기법은 Locality 기반의 모델이기에 반복적 참조가 가능하다 . 즉 자기의 할당된 프레임 셋에서 골라야하기때문이다 ] 여기서 locality total size > total memory size 시 thrashing 이발생하게 된다.
2. 프로세스당 적절한 수의 메모리(프레임) 할당
2. dynamic allocation
실제 실행을 해보고 결정 하는 방법이다.
. Working-Set Model
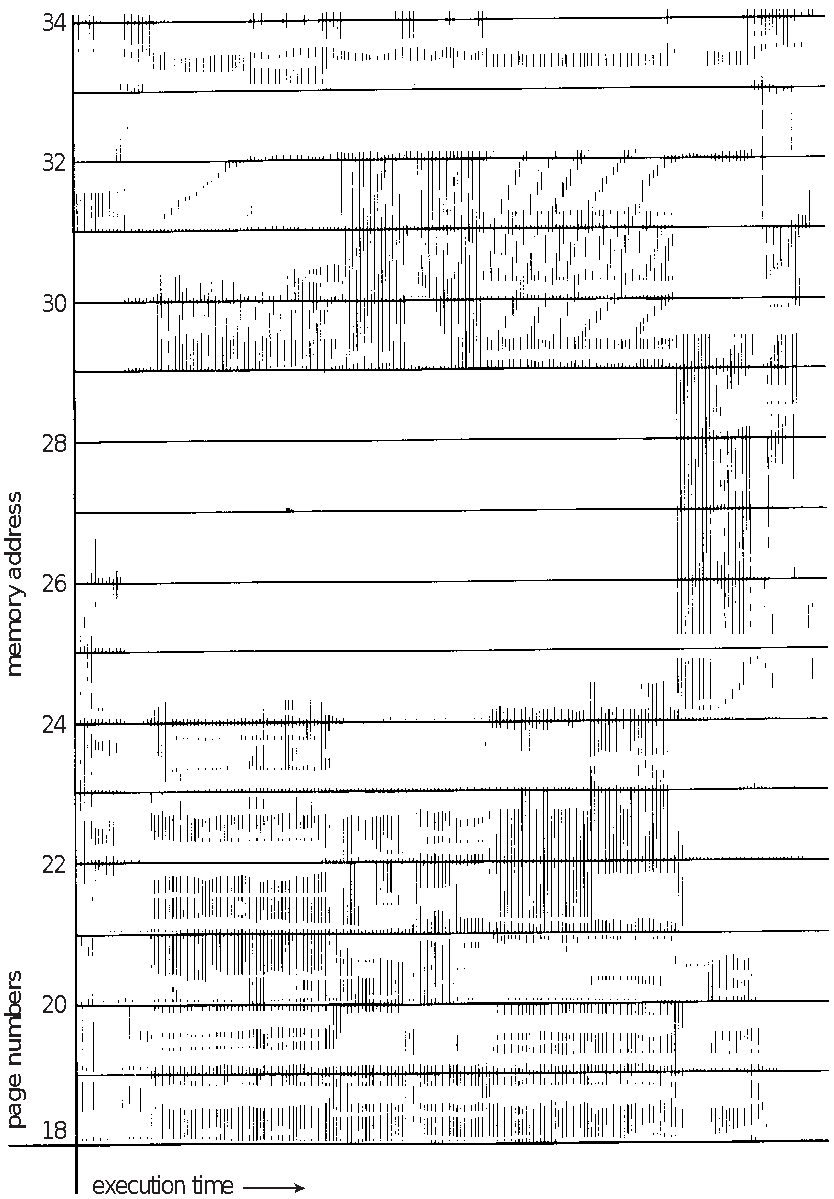
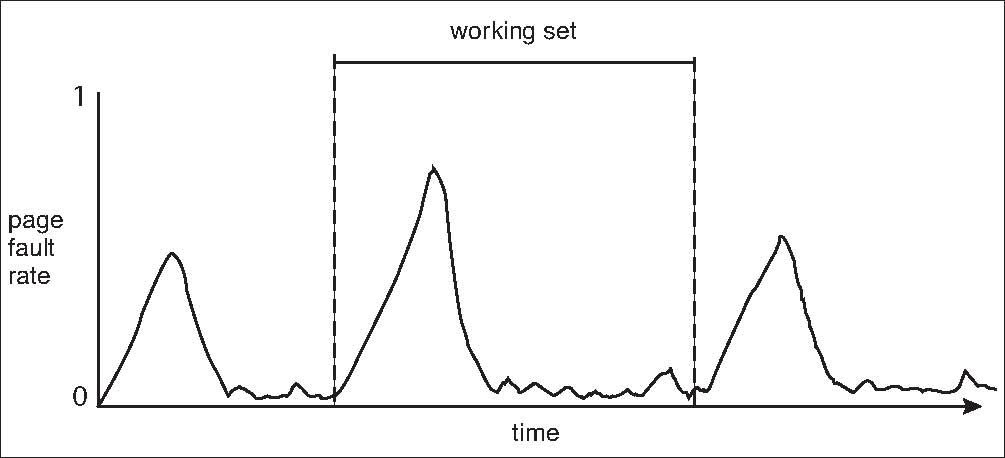
위그림은 프로세스가 실행 중 어떤 페이지를 사용하는지 실험한 결과 Locality 성질(어떤 프로세스를 사용하는지 표시한 그림으로 특정 시간대에 따라 일정 범위의 페이지를 참조하는것, 이러한 성질은 캐시메모리에서 역시 비슷하게 볼 수 있다 ) 이 성립하는것을 발견하게 되었고 . 특정 시간 대에 참고하는 부분은 일부분이라는것을 알게 되었다.
즉 특정 시간에 따라 사용하는 페이지의 개수만큼 프레임을 할당하면 관리에 편의성이 늘어난다
하지만 여기서 locailty를 조사는 프로세스를 미리 수행해보아야 할수 있는 정보이기 때문에 프로세스 수행 마다 변동하는 불확실성으로 인해 locailty를 사용하는것은 비현식적이므로 working set을 이용하게 된다.
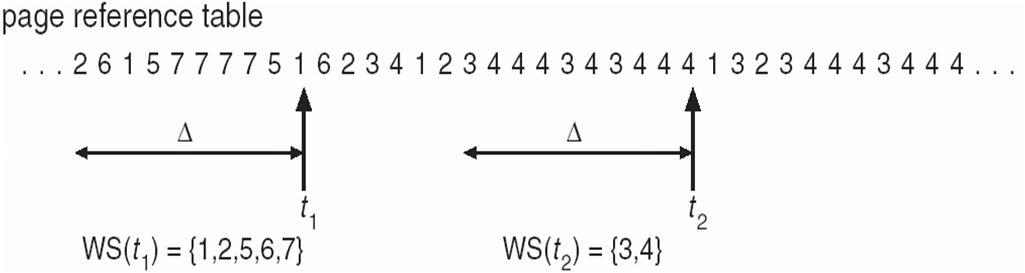
working set window = △ 이다. : 현 시점을 기준으로 얼마를 과거로 볼지에 대한 시간 사이즈이다.
locality : 페이지들이 모여있는것
working set : 과거 일정 시간대에 사용된 페이지
( 참조하는 고정된 페이지의 숫자 )
WSS ( Working set of Process P ) = 가장 최근 △ 시간 동안 참조 페이지의 전체 수
만약 △ 가 너무 작으면 전체 locality가 포함되지 않는경우.
만약 △ 가 너무 크면 여러 locality를 다 포함하게되는경우다 .
만약 △ 가 무한대로 간다면 전체 프로그램을 포함하게 된다.
D = ∑WSS , 전체 요구되는 프레임 .
만약 D > m 인상황이면 Trashing상황이 발생한다 .
정책상 만약 D> m 이게된다면 프로세스 중하나를 Swap out하거나 중단시키게 된다.
Locality 만큼 프레임을 할당하게 된다면 좋지만 미래의 locality를 알수없기 때문에 과거에 참조했던 페이지,
즉 thrashing이 발생 안 하도록 예의주시하는데 이를 위해 쓰는 모델이라고 볼 수 있다.
Working set을 추적해서 최적으로 만드는 것이 OS의 역할이다.
만약 정확성을 높이려면 reference bits개수를 늘리면 된다.
그렇게하여 △의 수를 기반으로 working set만큼 할당을 해주면 thrashing이 발생하지 않으며 메모리 낭비도 적어 효율적으로 관리할 수 있게 된다.
PFF (Page Fault Frequency )
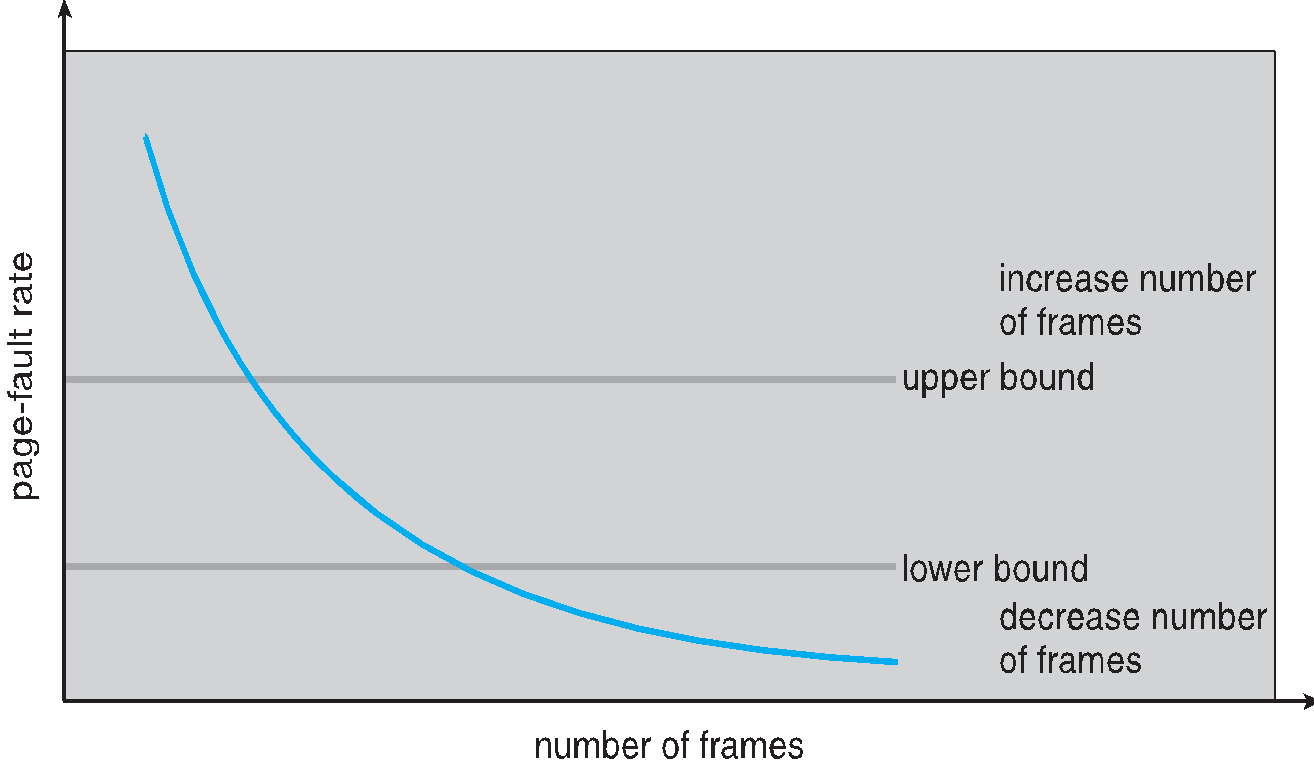
Page -fault의 비율과 Frames의 수는 반비례 관계를 가지게 된다 . 할당 프레임 수가 적을수록 Page fault 비율은 높아질수 밖에 없다. (메모리 관점에서 보면 이해된다 ) .!!!!
-위의 그래프에서 Upper bound와 lower bound를 설정하게 되는데 .
- 상한선 초과 프로세스에 더 많은 프레임 할당
- 하한선 이하 프로세스의 프레임은 회수하여 프레임 개수를 줄여주게 된다.
PFF가 낮으면 프로세스는 Frames을 잃게된다.
다른 프로세스에게 주려면 Global replacement 시스템에서만 가능하게되고
PFF가 높으면 프로세스를 더할당하게 된다 .
즉 프로세스가 처음 실행될 땐 demand paging에 의해 page fault가 게속 발생하며, physical memory로 다 불러온 후에는 page fault가 점점 줄어들게 된다.
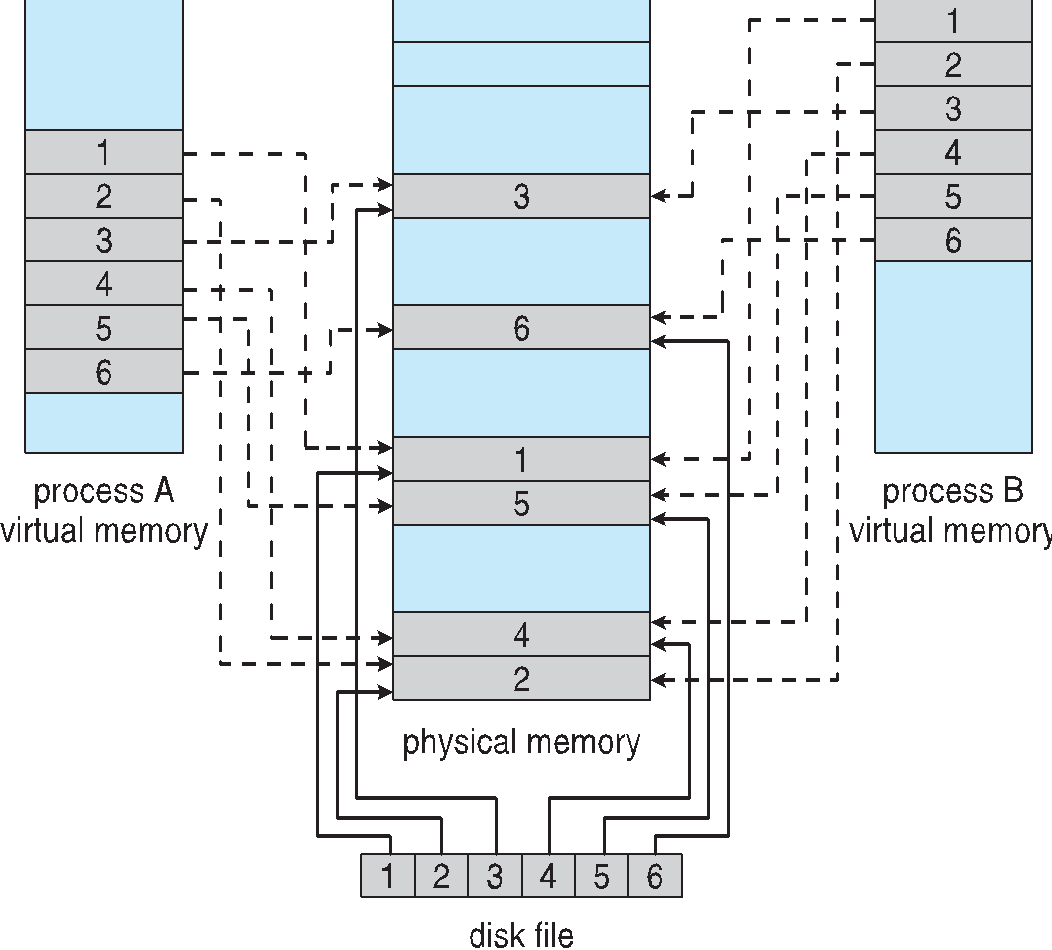
Memory Mapped Files
메모리 맵 파일의 기능은 가상 메모리처럼 프로세스 주소 공간을 예약하고 예약 영역에 물리 저장소를 커밋하는 기능을 제공하게 된다.
즉 프로세스의 가상 주소 공간중 일부를 관련 파일에 할애하는 것을 말하게 된다.
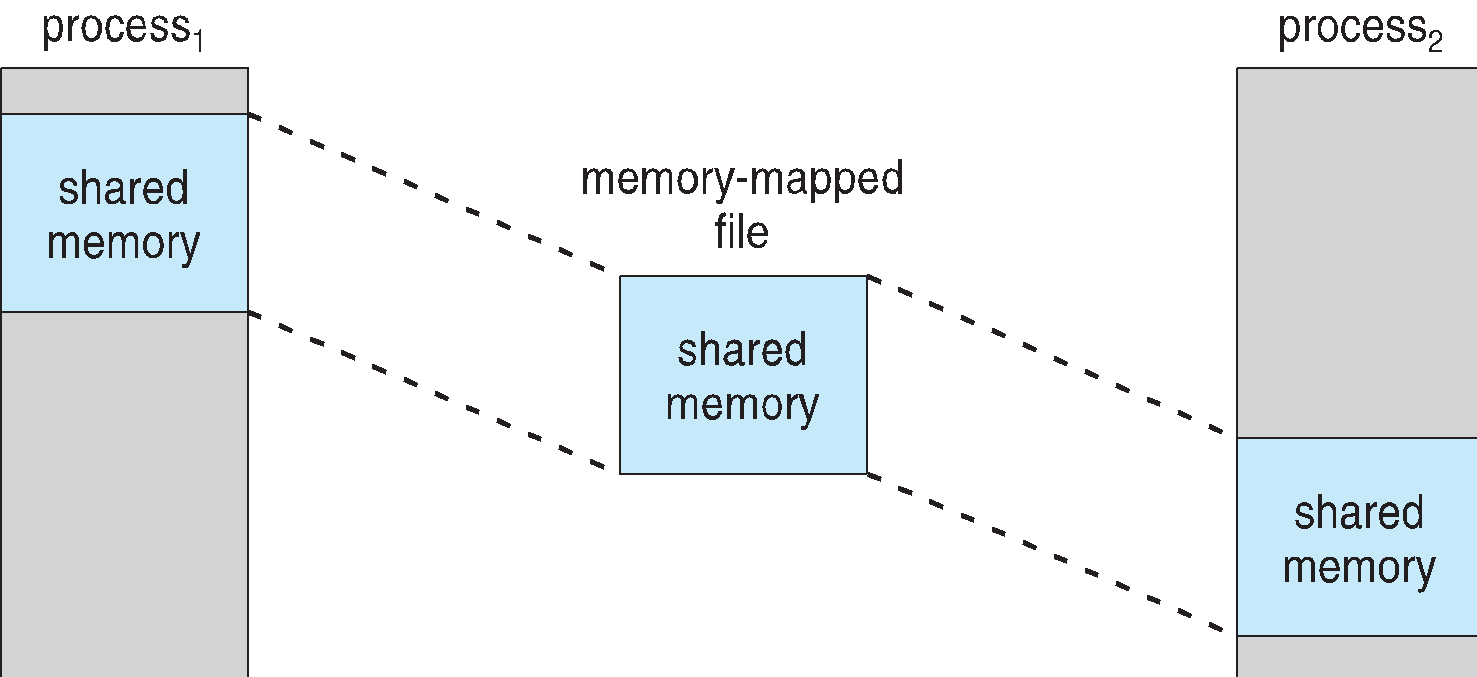
1. 파일은 처음 Demand paging을 사용하여 읽게된다.
2. 파일의 페이지 크기를 물리적 페이지의 파일 시스템으로부터 읽어들이며 파일에 대해 읽고 쓰는것은 메모리를 엑세스하며 처리하게 된다. 즉 read()/ write() 함수와 같은 시스템 호출이 아닌 메모리를 통하여 I/O를 구동후 파일에 접근하여 성능을 높인방식이다.
3. 또한 다중 프로세스 시스템에서 동일한 파일을 매핑하여 메모리의 페이지를 공유할 수 도있다.
* 디스크에 저장하는 시기는 주기적으로 저장하게되며 CLOSE() 시점에 디스크에 저장하게 된다.
Kernel Memory allocating
커널 메모리는 보통 사용자 모드 프로세스와 달리 별개의 메모리 풀에서 할당하게 된다.
커널은 다양한 자료구조를 사용하게 된다.
Buddy System

물리적으로 인접한 페이지로 고정된 크기의 세그먼트에서 메모리를 할당하게 된다.
2^n 할당자를 사용하여 메모리에 할당하게 되며 , 2^n 으로 req- res 하게 된다 .
즉 256KB는 물리적으로 연속적인 페이지로 쪼개진 조각을 Buddy라고 정의한다.
장점: 나중에 할당 후 phy mem 반납시 용이하다. 256kB를 원상 복구할때 연속적 모으기를 통해 용이
단점: 외부단편화 발생 가능.
Slab Allocating
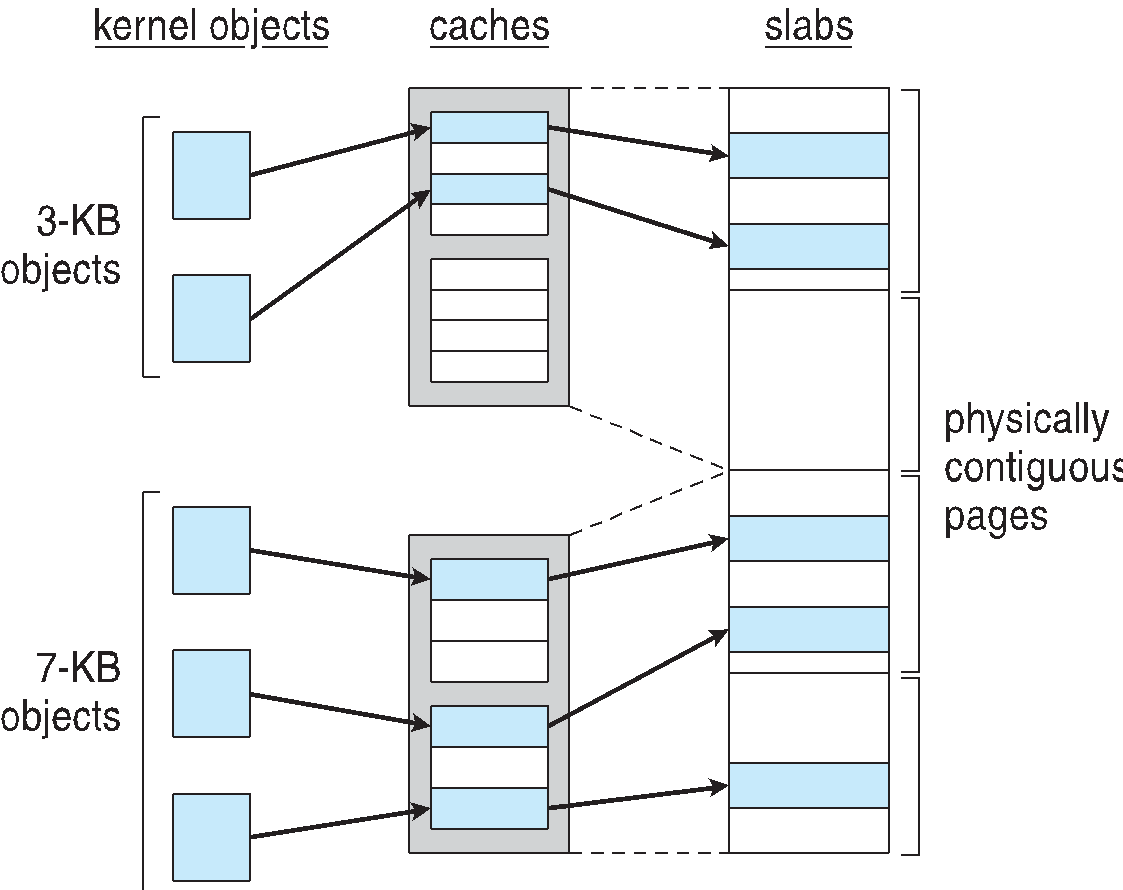
슬랩은 하나 또는 그이상의 연속된 페이지로 구성되게 되는데 캐쉬는 하나혹은 그이상의 슬랩으로 구성되게된다.
각 개체로 채워진 캐시는 데이터 구조의 인스턴스화가 되고 .
캐시가 생성되면 비어있는 것으로 표시댄 개체가 채워지게 된다 .
구조가 저장된다면 사용한것으로 개체를 표시하고. 슬랩이 사용된 객체로 가득 차면 빈 슬랩에서 다음 객체가 할당되게 된다.
빈 슬랩이 없다면 새 슬랩을 할당하게 되는데
단편화가 없으며 빠르게 요청을 처리하는 장점이 있다.
linux에서 슬랩의 상태는 Full (모두 사용), Empty( 슬랩사용안함), Partial(슬랩을 일부사용)하는것으로 Full이지만 slab을 더써야한다면 추가적 slab을 더 할당하게 된다 .