[TREND] Imputation1.
1. 결측이란? 값이 없는것 경우를 의미한다. 즉 결측값 ( missing value)이 존재할 때, 결측값을 버리고 관측값 즉 센싱한 데이터를 분석하게 된다면 [ listwise deletion ] 데이터의 편향이 발생하기 때문에 누락데이터에 관하여 추정 대체 데이터를 대입하여 분석을 하게된다 . 이를 imputation이라고 정의한다.
[ ※ Note : imputation은 missing value이고 prediction은 unknown value 이므로 정의자체가 다르다 혼동하지 말자 ]
imputation의 종류로는 변수 전체를 대체하는 unit imputation과 관측 일부를 대체하는 item imputation이 있고
방법론적으로 single imputation 및 multiple imputation으로 나눌수있다.
시계열 데이터 데이터 분석시 데이터 결측과 관련하여 데이터의 퀄리티 문제는 딥러닝 모델의 성능에서 높은 연관성이 존재한다.
예를들자면 데이터를 생성하기위해 센서로부터 데이터를 받아온다고 가정하면 데이터의 오차범위안에 신뢰할만한 데이터인가에 대한 문제부터 해당 데이터를 분석하여 딥러닝 모델에 학습하였을때 결과값이 기존의 값에서 예측범위 안에 있는가에 대한 문제는 결과값을 기반으로 판단해야 하는 다양한상황에 있어 중요한 지표로 작용하기 때문이다.
시계열 데이터의 결측과 관련한 많은 연구를 토대로 결측에 대한 5가지 분류방법으로 나누어 설명할수 있다.
. 통계 기반 ( Statistical )
. 행렬 기반 ( Matrix )
. 회귀 분석 기반 ( Regression )
. 딥러닝 기반 ( Deep-Learning (RNN & GAN ) )
이중 딥러닝 결측 방법은 현세계에서 사용하기에 많은 계산적 어려움이 존재하고 . 현세계에서 적용하기 위한 고성능 결측 방법에 대해 소개하고자한다 .
1. Type of imputation Data
1.1 MCAR ( Missing Completely At Random )
: 전체에 걸쳐 무작위하게 누락된 경우로 변수의 종류와 값에 상관없이 비슷한 분포로 누락된 데이터를 의미한다. 이러한 경우 통계적으로 누락 패턴을 파악하여 볼수 있지만 누락 패턴을 파악한다고 해도 분석에 큰 영향을 주지 않으며 MCAR인경우가 거의 없다.
1.2 MAR ( Missing At Random )
특정 변수에 대하여 데이터가 누락되는 경우이며 , 결측값의 경우 자료 내의 다른 변수와 관련이 있지만 해당 변수의 값과는 관련이 없다.
1.3 MNAR (Missing Not At Random ) = NMAR
누락되는 부분이 무작위로 누락되는것 보단 누락된 변수의 값이 누락된 이유와 관련이 있는것.
센서의 고장 혹은 네트워크 통신 문제 등으로 누락되는 경우가 많으며 이러한 상황을 MNAR이라 한다.
=> 1.1과 1.2의경우 결측된 데이터를 제거하여 데이터를 분석하는것이 좋은 반면
1.3의 경우 데이터 제거후 분석 진행시 데이터 모델이 편항적으로 학습될 수 있기 때문에 일반화된 모델을 설계하는것에 어려움이 존재한다.
이러한경우 제거가 아닌 데이터 보간 및 처리방법의 방법론이 중요해진다 .
2. Trend of imputation Data processing
MNAR 방법은 결측 데이터 제거시 편향 모델 학습으로 인하여 일반화 모델 도출이 어려운 이슈가 존재하였고
이에따라 5가지 분류에 의한 데이터 처리 방법이 연구되고 있다.
2.1 Statistical based method
가장 기초적인 방법.
결측치의 앞뒤 값에 대한 평균, 중앙값 등 기초 통계값을 채워 넣는 단순 대입방법.
-> 시간 소요가 적지만 일편적인 방법이라 표준 오차가 과소 추정되는 단점이 존재함 .
해결방법
1. Hot-deck
2. Nearest -Neighbor
-> 해결방법으로 1,2방법이 등 제안됐지만, 대게 추정량의 표준 오차계산 자체가 어려운 경우가 많은 단점이 존재하였음 .
-> 단일 신로 결측치 처리기법보다 발전된 형태의 다변량 변수에 적용가능한 MI에 관한 연구가 진행되었고 MICE방법이 자주 사용된다.
MI ( Multiple Imputaion ) method
MICE ( Mulitiple Imputation Using Chained Equations )
- conditional spec
각 복원 모델에 따라 대치를 진행하는 실용적인 방법으로 x1 첫변수는 다른 모든 변수 x2.~xn에 대해 회귀함.
x1의 결측값은 사후 예측 분포에서 시뮬레이션된 값으로 대체함 .
즉 다음 변수는 x2, x2를 제외한 x3~xn에 대해 회귀 , 결측값은 사후 분포에서 추출된 값으로 대체 되는 것으로 결측값의 개수만큼 연쇄적인 특징을 가지게된다.
2.2 Matrix based method
MF( Matrix Factorication )
행렬을 분해 및 재구성하여 데이터 간 상관관계를 도출 하여 결측값을 대치하는 방법.
원본데이터에서 특징을 추출을 진행할 때 데이터의 행렬을 2개의 저차원 행렬로 분해하고 이후 원 행렬을 재구성하는 시도를 하며 누락된 값을 대치하는 형태로 이루어짐.
TRMF ( Temperal Regularized Matrix Factorization )
데이터 기반 시간 학습 및 예측하는 시간 정규 행렬 분해 프레임 워크.
PSMF (Probabilistic Sequential Matrix Factorization )
관측된 시계열 데이터를 행렬로 변환후 행렬 추정을 이용하여 결측치 추정, 및 예측하는 방법.
모델에 구애받지 않고 행렬 추정을 통하여 결측값을 대체함.
고차원 시계열로 구성된 시변량 및 비정상성 데이터를 분해하기 위한 방법으로 순차 근사추정 결과를 통하여 데이터 행렬을 분해하고 마코비안 종속특성을 활용하여 시간 종속성에 대한 속성을 저차원 특징 공간으로 인코딩하는 기법이다.
추가적으로 칼만 필터 기법을 활용하여 효율적으로 구성되었다.
즉 미분 가능한 비선형 picewise한 공간모델을 보정하고 추정하는 결측 처리 기법이다.
2.3 Regression based method
과거 데이터를 통하여 모델을 학습 및 예측하는 기법.
가장 기본적으로 선형회귀분석이 있으며 , 해당 기법은 빠르고 간단하지만 전체적 시계열 특성과 시계열 데이터의 추세를 반영하지 못하고 순간적인 시간 Tn에 대하여 바로 전과거와 바로 이후 미래만 바라보고 판단하기 때문에 데이터의 트렌드를 고려 하지못하는 단점이 존재한다.
AR( Auto Regressive )/ ARIMA ( AutoRegressive Integrated Moving Average ) / LATC( Low-Rank AutoRegressive Tensor Completion )
선형회귀모형의 단점을 해결하기 위해 제안된 AR 모델이다. AR모델을 기반으로 MA, ARIMA모델로 변형되었다.
ARIMA ( AutoRegressive Integrated Moving Average )
AR모델중에 가장 대표적으로 과거 데이터와 데이터의 추세를 반영하여 나타낼 수 있는 모형이다.
LATC
LATC모델은 최근 소개된 모델이다. 다변량 시계열 데이터를 3차원 텐서형태로 변환후 AR모델을 적용하는 것으로
텐서 형태로 변환시 , 시간, 계절성, 다변량 변수, 즉 3가지 기준으로 고려할 수 있게 되었다.
AR모델과 달리 데이터의 변환 및 다변량 처리기법을 통하여 결측값을 처리한다.
2.4 RNN based method - 순환신경망 기반 결측치 처리방식
시간의 흐름을 가지는 데이터의 시간관꼐를 도출하기 위해 고안된 알고리즘으로 시계열 예측등에 자주 사용된다 , 또한 결측치 처리 상황에도 사용되곤한다.
M-RNN - ( Multi-Directional Recurrent Neural Network )
기존에는 데이터 처리시 데이터 스트림의 보간 혹은 패턴의 특성에 관하여 가정을 통해 추정하였다.
M-RNN의 논문의경우 데이터 스트림 내에서 보간과 스트림 대치하는 방법을 접목하여 제안한다.
통계적 보간법, MICE, RNN 기법과 비교해서 향상된 기능을 보여준다.
GRU-D
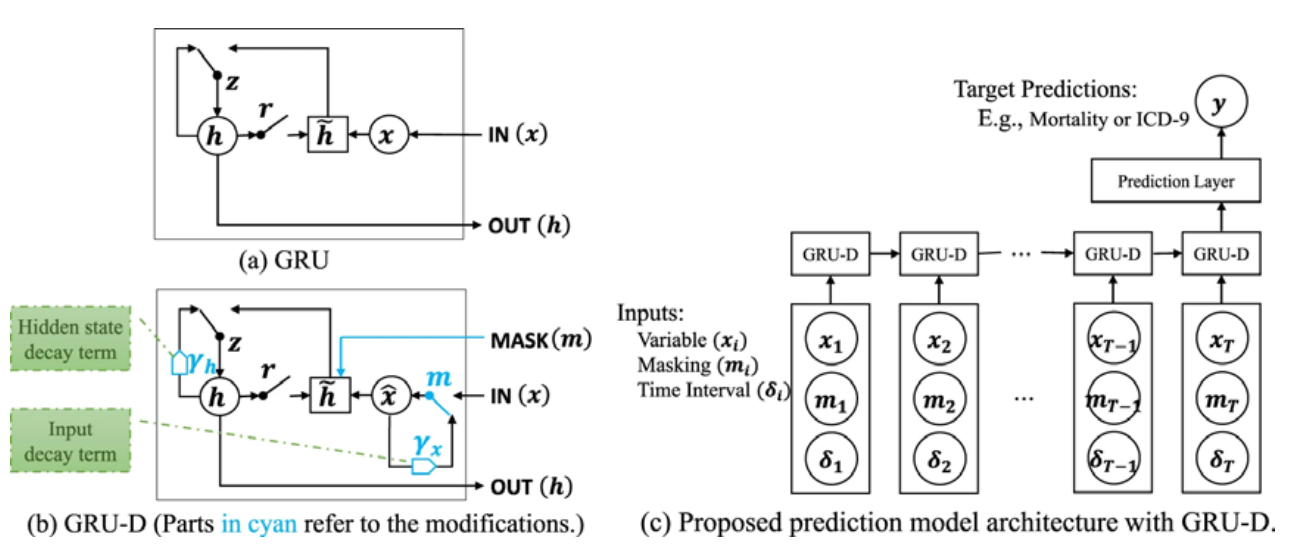
RNN기반 결측 처리를 위해 개발된 모델, GRU(Gated Recurrent Unit)을 기반으로 설계.
기존 GRU모델 기반에 결측 여부에 대한 마스킹 정보와 결측된 시간 간격을 고려하여 GRU모델에 감쇠율을 추가한 모델이다. 여기서 감쇠율은 다른 실제 값들이 시간 간격 정보에 따른 결측치에 대한 영향 정도에 따라 모델링을 통해 결정되는 구조이다.
즉 시계열의 장기적인 시간 종속성 을 파악할 뿐만 아니라 누락된 패턴을 고려하여 더 나은 결측치에 대한 예측을 진행할 수 있다
BRITS(Bidirectional Recurrent Imputation for Time Series)
결측값 대치에 대해 반복 신경망을 기반 제안된 모델 , 특정 데이터의 분포에 대한 가정 없이 결측값을 대치하기 위해
동적 시스템을 양방향 RNN으로 조정. 해당 방법은 여러 상관 결측데이터를 처리가 가능하고 , 비선형 역학을 기본으로 하는 시계열로 일반화가 가능. 데이터 기반의 대치를 제공하여 누락 데이터가 있는 상황에서 역시 적용 가능.
SSIMM(Sequence-to-Sequence Imputation Model)
무선 센서 네트워크 상황에서 누락된 데이터를 복구하기 위해 새롭게 제안된 모델.
S2S 딥러닝 아키텍쳐를 사용하여 과거 미래의 정보를 모두 활용할 수 있도록 LSTM 모델을 활용함.
슬라이딩 윈도우 알고리즘을 활용하요 데이터양에 비해 많은 수의 훈련 샘플을 생성하기 때문에 적은 데이터 셋으로도 사용 가능한 알고리즘.
여 MICE, ARIMA, Seasonal ARIMA 등의 대치 방법과 비교하여 더 우수한 성능
ODE_RNN ( Ordinary Differential Equation _RNN )/ Latent ODE
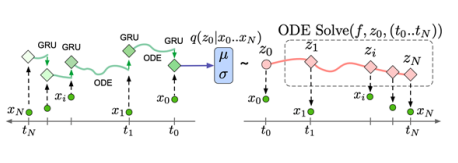
간격 이 균일하지 않은 시계열 데이터에 대해 RNN계열 모델의 적용이 어려운 이유로 고안된 모델
상미분 방정식(ODE)에 의해 RNN의 은닉 계수의 관계를 도출하여 학습하는 모델이다.
이후 Latent ODE모델로 VAE(Variational AutoEncoder)를 기반하여 ODE-RNN을 인코더 ODE를 디코더 구조로 활용하여 처리하는 방법으로 불규칙적 샘플링 데이터 역시 ODE-RNN & Latent ODE를 적용 가능하고 RNN보다 성능이 좋다.
CDSA(Cross-Dimensional Self-Attention)
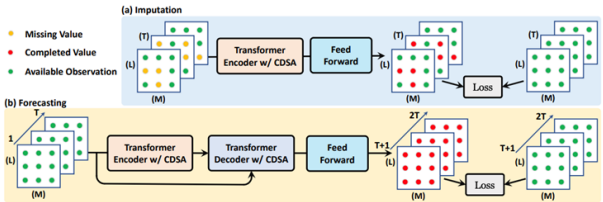
다변량 지리적 위치가 지정된 시계열 데이터 처리의 경우 적합한 모델 .
데이터에 대해 Self Attention 아키텍쳐를 기반으로 낮은 계산 복잡성을 유지하며 시간, 위치 및 센서 측정을 포함한 여러 차원으로 Attention을 캡쳐하여 순차적으로 처리하는 모델 .
위치 정보가 결합된 시계열 데이터의 경우 더 효과적인 결측값 대치 혹은 예측성능을 보인다.
2.5 GAN based method
GAN알고리즘은 입력 데이터의 확률분포를 기반으로 학습하여 데이터를 생성하는 것이 목적이다 .
- 생성자 G와 구분자 D .
G는 실제 데이터와 유사한 데이터를 만들 수 있도록 학습을 하는것 이고 .
D는 실제 데이터 및 G에의한 가짜데이터를 구분하는 역할을하도록 설계된다.
이때 G와 D가 서로 대립하며 성능을 개선하는 방식이 GAN의 원리이다.
GAIN(Generative Adversarial Imputation Networks)
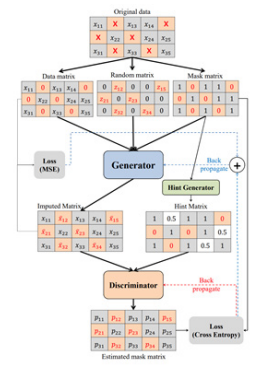
생성자는 실제 데이터의 일부를 관찰하고 이에 기반하여 결측 데이터를 대치.
구분자는 대치 데이터와 실제 데이터의 정확성을 판별한다.
이때 구분자에 벡터 형식으로 몇가지 원시 샘플 데이터의 누락에 대한 정보를 제공후 해당 정보를 기반으로 생성자는 실제 데이터분포에 따라 데이터를 생성하는 방법을 학습하는 알고리즘이다.
GRUI-GAN

RNN계열의 GRU-D구조를 변형후 GAN구조에 결합한 기술로 GRU-D의 구조에 감쇠를 제거한 GRU-I 구조를 사용하여 생성자와 구분자를 구성하게 된다. GAN구조와 GRU-I 구조를 결합함으로 대립하여 정확성을 높이는 방식의 알고리즘이다 .
단점으로 학습시간이 많이 소요되며 데이터에 노이즈가 포함되어 입력시 정확도 안정성문제로 비실용적인 문제가 있다.
E2GAN
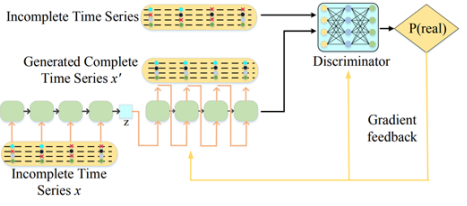
E2E 개념을 도입한 것으로 GRUI-GAN모델은 임의의 노이즈 벡터를 사용하는 반면
해당 모델은 생성기로 GRUI 기반의 Auto Encoder구조를 사용하였지만 개념적 개선이 아닌 마스크, 시간지연, 감쇠율 등을 이용하여 진행되어 오토 인코더 구조의 추가가 가장큰 기여라고 본다.
NAOMI(Non-Autoregressive Multiresolution Sequence Imputation)
ㅇ양방향 RNN계열 알고리즘인 BRITS알고리즘과 유사한 방식으로
과거 미래의 데이터 모두 활용한 비자기 회귀 모델.
결측치 대치 작업시 미래와 과거 모두를 이용하여 양방향 모델을 훈련한다.
즉 X1,X2,X3,X4,X5 가 존재한다면 X3는 X1과 X5를 이용하여 X2는 X1과 X3를 이용하여 X4는 X3와 X5를 이용하여 예측을 진행한다 .
마지막으로 GAN알고리즘의 대립하며 학습을 진행하여 모델을 향상시킨디.
Bi-GAN((Bi-directional GAN))
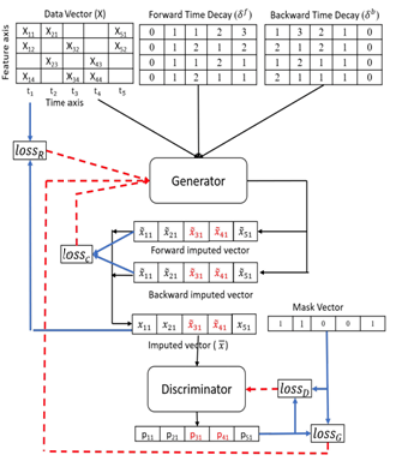
생성적 적대 신경망을 양방향으로 반복적으로 진행하는 알고리즘으로 단방향보다 정확성이 높다.
Forward , Backword방향의 Time decay를 고려하기 때문에 다양한 길이의 시계열 결측 상황에 대하여 예측 장업이 유연하게 가능하다는 장점이 존재한다.
- 실시간으로 처리되기에는 문제가 존재