공룡책 - 운영체제 정리3.2
본 게시물은 Abraham Silberschatz의 Operating System Concepts 공룡책을 참고하며
개인적으로 공부 및 정리한 자료입니다.
3.1 부분의 프로세스 ,스레드와 관련된 이야기를 참고하시길 바랍니다.
공룡책 - 운영체제 정리3
본 게시물은 Abraham Silberschatz의 Operating System Concepts 공룡책을 참고하며 개인적으로 공부 및 정리한 자료입니다. Process Thread Process Sysnchronization CPU Scheduling Process 프로그램 : 디스크..
hofe-rnd.tistory.com
IPC
Sysnchronization
Scheduling
IPC ( Inter Process Communication )
시스템 프로세스는 독립적이거나 상호적임
- independent process : 타 프로세스에 영향을 미치지 않음.
- cooperating process : 타 프로세스에 영향을 미침 .
상호관계가 있는 프로세스는 데이터 공유를 해야하는 상황과 다른 프로세스에 영향을 주고받음.
- 정보공유 , 컴퓨팅 속도 향상 , 모듈성 , 편의성 , => 상호관계가 있는 프로세스(다중프로세스)끼리 간 IPC의 필요.
Cooperating process ;
1. Producer process와 Consumer process 가함께 존재한다
생산 프로세스는 주로 정보를 생산하는 역할을 함.
소비 프로세스는 생산프로세스의 정보를 사용한다 .
프로세스 간 정보를 주고 받을때 버퍼의 분류
Unbounded buffer vs bounded buffer
- 버퍼 크기에 제한을 두지 않음 고정된 버퍼 크기가 있다고 가정함
IPC TYPE

아래에는 공유메모리로 consumer producer의 간략한 프로세스를 하나 구성해보았다 .
1. Shared Memory
- 프로세스간 통신을 하기위한 공유메모리 영역은 OS영역이 아닌 사용자 프로세스의 제어하에 있다.
여기서 중요한점은 공유메모리에 사용자가 접근시, 두 스레드 혹은 프로세스가 동기화 할수 있는 방법을 제공해야한다.
- 통신하는 방법으로는
1. Message System - 공유 변수에 제한되지않고 통신해야한다 .
2. IPC메세지는 send message , receive message 에 대한 작업이 있어야한다.
* 메세지의 크기는 정적 또는 동적이다.
/*미완성 코드2 */ /*chap3 코드 가져옴 */
/*-> Shared data */
// consumer
#include<stdio.h>
#include<sys/types.h>
#include<signal.h>
#include<unistd.h>
#include<stdlib.h>
#include<pthread.h>
/*
******************************
****** variable *************
*/
#defube BUFFER_SIZ 100
enum process_state
{
STOP = 0.
NEW = 1,
RUN = 2,
WAIT = 3,
READY = 4,
EXIT = 5,
ABRNOMAL= 6,
MAX = 7
};
enum _return_value
{
N_SUCCESS =1;
N_FAILURE =-1;
}
typedef struct _pro_control_block
{
pid_t pid;
pthread_t pthread[2];
int thd_id;
int p_state;
}PCB;
typedef struct _sharedmem
{
/*
* shm data variable
*/
}SHM;
/*
********************************
****process fucntion block******
********************************
*/
int init_pcb();
void signal_hdr(int);
int thread_function();
void *p_function(void *data)
int main_th();
/*
********************************
****global variable block*******
********************************
*/
PCB *pcb = NULL;
int main()
{
/*shm bounder buffer section */
SHM shm_buff[BUFF_SIZE];
int in =0 ;
int out =0;
char p1[] = "th1";
char p2[] = "Th2";
char p3[] = "th3";
/*
* 1. make pcb
*/
init_pcb();
signal_hdr();
thread_f(pcb);
main_th();
}
int init_pcb()
{
pcb = (PCB*)malloc(sizeof(PCB));
memset((void*)pcb , 0x00 , sizeof(PCB));
pcb->p_state = NEW;
return N_SUCCESS;
}
int signal_hdr()
{
signal(SIGHUP, SIG_IGN);
signal(SIGPIPE, SIG_IGN);
}
int thread_f(PCB*pcb)
{
pcb->thd_id = pthread_create(&(pcb->pthread[0]), NULL, producer, (void *)p1);
if(pcb->thd_id < 0)
{
perror("pthread create error");
exit();
}
pcb->thd_id = pthread_create(&(pcb->pthread[1]), NULL, consumer, (void *)p1);
if(pcb->thd_id < 0)
{
perror("pthread create error");
exit();
}
p_function((void *)p3);
pthread_join(pthread[0], (void **)&(pcb->p_state));
pthread_join(pthread[1], (void **)&(pcb->p_state));
}
void *p_function(void *data)
{
pid_t pid;
pthread_t tid;
pid = getpid();
tid = pthread_self();
char * thread_name= (char *)data;
while(i<3)
{
printf("thread name: %d , tid :%x. pid %u\n", thread_name, (unsigned int)tid, (unsigned int)pid);
i++;
sleep(1);
}
}
void *producer(void *data)
{
PCB *pcb;
SHM nex_produced;
while(true)
{
while(((in+1) % BUFF_SIZE == out)
/*do anything */
buffer[in] = next_produced;
in = (in+1)%BUFF_SZIE;
}
}
void *consumer(void *data)
{
PCB* pcb;
SHM next_consumed;
while(true)
{
/*do anything */
next_consumed = buffer[out];
out = (out +1 ) % BUFF_SIZE;
}
}
int main_th()
{
while(true)
{
sleep(1);
}
}2. Message Passing
프로세스 P & Q의 통신시
1. 통신 링크가 있어야함.
2. SEND /RECEIVE 메시지 교환
3. 링크 구현시 고려사항
How are links established?
Can a link be associated with more than two processes?
How many links can there be between every pair of communicating processes?
What is the capacity of a link?
Is the size of a message that the link can accommodate fixed or variable?
Is a link unidirectional or bi-directional?
1. Physical : 1. Shared memory , 2. Hardware bus, Network,
2. Logical : 1. Direct or Indirect ,2 Synchronous or asnchronous, 3 Automatic or explicit buffering
- 통신
Direct InDirect
1. Direct
: 프로세스는 서로의 이름을 명시적으로 지정해야함 .
/ Sender ( P메시지 ) / Receiver (Q메시지 )
: 통신링크 성질
1. 링크는 자동으로 설정됨.
2. 링큰느 한쌍의 통신 프로세스와 연결됨
3. 각 쌍 사이에 정확하게 하나의 링크가 존재함
4. 링크는 단방향이거나 양방향임
2. Indirect
1.포트로부터 송수신함 .
2.각 포트는 고유 id를 가지고있음
3. 프로세스는 오직 포트를 공유할때 통신이가능함
: 성질
1. 프로세스가 포트를 공유할때만 링크 설정.
2. 링크는 많은 프로세스랑 연결될수있음.
3. 프로세스 쌍은 몇몇 통신링크를 공유할수 있음
4.링크는 단방향이가 양방향임
=> 운영방법
1. 포트 생성
2. 포트를 통해 송수신
3. 포트 삭제
-> 기초방법
1. sender -> send msg to A
2. recver -> recv from A
3. Port sharing
3.1 p1 , p2 , p3 shared port A
3.2 P1 send and recv p2, p3
-> 링크는 대게 두개의 프로세스를 연결해야함
-> 오직 한개의 프로세스가 recv로 작용해야함
-> 임의로 recv를 선택하도록 허용하고 send에게 알려야함
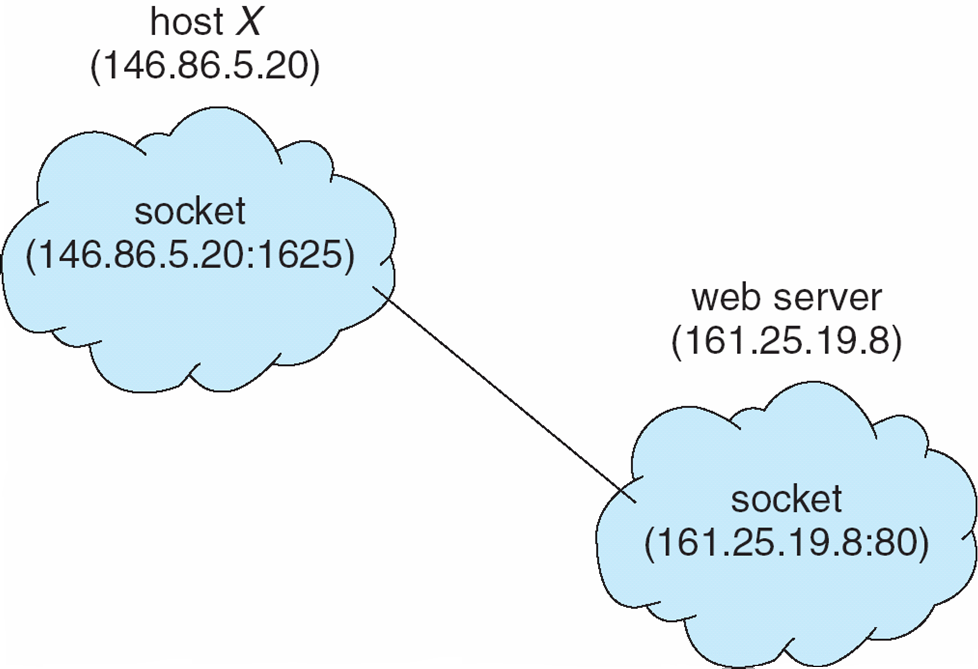
Client - Server communication
Socket - endpoint communication이다 . ( OSI 7 0 L4 LAYER TCP/UDP )
1. IP주소 및 포트연결 -> 메시지 패킷의 시작부분(헤더)에 포함되는 번호
2. 한 쌍의 소켓 간에 통신이 구성됨
TCP 기반 SOKET 작성절차
1.
Socekt() -> bind () -> listen() -> accept() -> read/write -> finished ? -Y-?CLOSE
-no -> accept()
1. socket(). 소캣 생성.
socket(PF_INET, SOCKET_STREAM, 0);
서버도 클라이언트와 통신을 하기 위해 소켓을 생성
**
setsockopt
int setsockopt(SOCKET socket, int level, int optname, const void* optval, int optlen);
socket : 소켓의번호
level : 옵션의 종류. 보통 SOL_SOCKET과 IPPROTO_TCP 중 하나 사용.
val 자료형 설명
SO_REUSEADDR BOOL 이미 사용한 주소를 재사용.
SO_RCV_BUF int 수신용 버퍼의 크기 지정
SO_SND_BUF int 송신용 버퍼의 크기 지정
SO_RECVTIMEO timeval 수신시 Blocking 제한 시간 설정.
SO_SNDTIMEO timeval 송신시 blocking 제한 시간 설정.
SO_KEEPALIVE BOOL TCP 통신에서만 유효, 일정 시간마다 연결 유지 상태체크.
SO_LINGER struct LINGER 소켓을닫을때 남은 데이터의 처리 규칙 지정.
SO_DONTLINGER BOOL 소켓을 닫을때 남은 데이터를 보내기 위해서 블럭되지 않도록함.
SO_DONTROUTE BOOL 라우팅하지 않고 직접인터페이스로 전송
SO_BROADCAST BOOL 브로드 캐스트 사용가능 여부 체크.
TCP_NODELAY BOOL(int) 소켓에 네이글 알고리즘(Nagle Algorithm)을 사용할지 여부를 지정. RUE인 경우 알고리즘을 사용하지 않음. 알고리즘을 사용하지 않을 경우 실제 전송까지의 지연 시간이 줄어듬.
SO_REUEADDR
-> bind error : Address already in use
-> 보통 소켓을 사용하는 프로그램은 강제 종료되었지만, 커널단에서 해당 소켓을 바인딩해서 사용하고 있기 때문에 발생하는 에러
TCP_NODELAY
IPPROTO_TCP 레벨의 옵션 /TCP 소켓에서만 사용
값이 1 또는 TRUE인 경우 네이글 알고리즘을 사용하지 않습니다. 값이 2 또는 FALSE인 경우 네이글 알고리즘을 사용
SO_LINGER
struct linger{
int l_onoff; linger 옵션의 On/Off 여부
int l_linger; 기다리는 시간
}
위의 두 개의 변수 값에 따라 3 가지의 close 방식이 존재
l_onoff == 0 : 소켓의 기본 설정 l_linger에 관계없이 버퍼에 있는 모든 데이터를 전송. close()는 바로 리턴을 하지만 백그라운드에서 이러한 작업이 이루어짐.
l_onoff > 0, l_linger == 0 : close()는 바로 리턴하며, 버퍼에 있는 데이터는 버림. TCP 연결 상태에서는 상대편 호스트에게 리셋을 위한 RST 패킷 전송. hard 혹은 abortive 종료라고 부름.
l_onoff > 0, l_linger > 0 : 버퍼에 남아있는 모든 데이터를 보내며, 그 동안 close()는 블럭되어 대기함.
optname : 설정을 위한 소켓옵션의 번호.
optval : 설정값이 저장된 주솟값.
optlen : optval 버퍼의 크기.
**
2. bind()
‒ socket()으로 생성된 소켓의 소켓번호는 응용 프로그램만 알고 있음
컴퓨터 외부와 통신하기 위해 소켓번호와 소켓주소를 연결
bind()가 필요한 이유
→ 임의의 클라이언트가 서버 프로그램의 특정 소켓으로 접속을 하려면 서버는 자신의 소켓번호와
클라이언트가 알고 있는 자신의 주소 및 포트번호를 미리 연결해 두어야함.
‒ bind() 사용 문법
int bind(int s, struct sockaddr *addr, int len);
→ int s : 소켓 번호
→ struct sockaddr *addr : 서버 자신의 소켓주소 구조체 포인터
→ int len : *addr 구조체의 크기
bind()는 성공시 0, 실패시 -1 을 리턴
3. listen()
int listen(int s, int backlog);
int s : 소켓번호
int backlog : 연결을 기다리는 클라이언트의 최대 수
클라이언트가 listern() 을 호출해 둔 서버 소켓을 목적지로 connect() 를 호출
→ 3-way 핸드쉐이크 연결설정의 시작
시스템이 핸드쉐이크를 마친 후에는 서버 애플리케이션이 설정된 연결을 받아들이는 과정
→ accept()가 사용됨
accept()는 한번에 하나의 연결만 가져감
→ 여러 연결요청이 동시에 오면 시스템은 설정된 연결들을 큐에 넣고 대기함 accept
→ backlog 인자는 대기시킬 수 있는 연결의 최대 수
■ listen은 소켓을 단지 수동 대기모드로 바꾸어 주는 것
‒ 성공시 0 ,실패시 -1 을 리턴
4.accept()
서버가 listen()의 호출 이후 클라이언트와 설정된 연결을 실제로 받기위해 사용.
사용문법.
int accept(int s, struct sockaddr *addr, int *addrlen);
int s : socket num
sturuct sockaddr *addr : 연결 요청을한 클라이언트의 소켓주소 구조체
int *addrlent : *addr 구조체 크기 포인터.
수행 성공시 클라이언트와의 통신에 사용할 새로운 소켓이 생성됨 실패시에는 -1 이 리턴
서버는 클라이언트와 통신하기 위해 새로 만들어진 소켓번호를 사용
연결된 클라이언트의 소켓주소 구조체와 소켓주소 구조체의 길이의 포인터를 리턴
→ addr 과 addrlen 인자로 리턴함
→ 서버는 소켓주소 내용으로 연결된 클라이언트의 주소를 알 수 있음
1. Client - Server model.
정의
; 서비스를 제공하는 장비 -> 서버
서비스를 이용하는 장비 -> 클라이언트
********************************************
(response)
클라이언트 <- 서버
->
(request)
*********************************************
client - server model.
1. 클라이언트는 서비스를 이용하기 위한 요청(request) 을 서버로 보낸다.
2. 서버는 서비스 제공을 위해 response를 클라이언트에게 보낸다.
3. 1. 서버를 먼저 설계.
1-1 Authentication. ( 최초 request에 대하여 response를 통해 연결 인증절차)
1-2 Security ( 서버의 정보보호 )
1-3 concurrency -동시 서비스 제공 기능.
1-4 stability 안정적 실행 가능.
2. 클라이언트는 서버가 제공하는 서비스를 이용하도록 설계.
**********************************************
1. 2-tier 모델 . -> Client -> Server (요청 메세지 전송) , Server-> Client (응답 메세지 전송 )
1. 병목 현상이 생기기 쉽다.
-트래픽 집중 현상, 처리 용량 부족 현상발생.
2. fat client.
- 단점 보안을 위한 네트워크 서비스를 제공하기 위한 기능의 일부 클라이언트 축에 구현
- 서버의 처리 부담을 줄이는 장점. / 업그레이드나 버전관ㄹ 등이 불편.
2. 3-tier
3. n-tier
4. P2P
**********************************************
서버 구현
1. 연결형-비연결형
2. Stateful - stateless
3. lterative - Consurrent.
**********************************************
. Socket programming.
Socket - TCP 혹은 UDP의 TRANSPORT 계측을 이용 하는 API .
Socket num - 새로운 소켓을 개설시 대표하는 int type의 number.
1. file descriptor
2. socket descriptor
-> socket num.
-> 소캣을 개설하여 얻은 파일 디스크립터.
3. 응용 프로그램 - 소켓, TCP/IP
->1 파일 디스크립터 0 (표준입력), 1(표준 출력), 2(표준 에러)
-> 3번이후 사용자 프로그램 파일 -> OPEN 디스크립터 배정
-> 소켓번호는 순서대로 배정하게됨.
PORT NUM -호스트내의 통신 접속점을 구분하기 위해 사용
1. 16 BIT 구성.
2. 1~65535 사이의 값을 가짐.
3. TCP/ UDP 같은 포트넘을 사용가능.
4. 같은 종류의 서비스를 동시 제공시에 같은 포트넘 사용.
-소켓 사용방법.
1. 소캣 디자인.
1. 통신시 사용하는 프로토콜 (TCP / UDP 선택)
2. 자신의 IP주소
3. 자신의 PORT NUM
4. 상대방의 IP주소
5. 상대방의 PORT NUM.
2. 프로그래밍.
1. SOCKET ( )
int socket(int protocolFamily, int type, int protocol);
1. int protocolFamily (domain)
-> TCP/IP 프로토콜을 사용하기 위해 프로토콜 체계를 지정,
PF_INET, PF_INET(IPv6_, PF_UNIX(유닉스방식), PF_NS(XEROX 네트워크 시스템)
PF_PACKET(리눅스 패킷 캡쳐).
2. type
->서비스 타입
->TCP : SOCK_STREAM, / UDP : SOCK_DGRAM,/ RAW : SOCK_RAW (TCP, UDP 계층 거치지않고 바로 IP 계층 이용하는 프로그램)
3. protocol
-> 소켓에서 사용할 프로토콜
TCP : IPPROTO_TCP,/ UDP ; IPPROTO_UDP /
Type에서 미리 정해진 경우 0을 사용.
예제 -1
1 #include <stdio.h>
2 #include <stdlib.h>
3 #include <sys/types.h>
4 #include <sys/stat.h>
5 #include <sys/socket.h>
6 #include <fcntl.h>
7 #include <unistd.h>
8
9 int main()
10 {
11 int fd1,fd2,sd1,sd2;
12 printf("getdtablesize() = %d₩n",getdtablesize());
13
14 fd1 = open("/etc/passwd",O_RDONLY,0);
15 printf("/etc/passwd's file descriptor = %d₩n",fd1);
16
17 sd1= socket(PF_INET, SOCK_STREAM,0);
18 printf("stream socket descriptor = %d₩n",sd1);
19
20 sd2= socket(PF_INET, SOCK_DGRAM, 0);
21 printf("datagram socket descriptor = %d₩n",sd2);
22
23 fd2= open("/etc/hosts",O_RDONLY,0);
24 printf("/etc/hosts's file descriptor = %d₩n",fd2);
25
26 close(fd2);
27 close(fd1);
28 close(sd2);
29 close(sd1);
30
31 return 0;
32 }
- #include <sys/types.h>
‒ 소켓 시스템 콜에 필요한 상수 선언
- #include <sys/stat.h>
‒ 파일의 상태에 대한 데이터 선언
- #include <sys/socket.h>
‒ 소켓 시스템 콜 선언
- #include <fcntl.h>
‒ open flag 에 필요한 선언
- fd1 = open("/etc/passwd", O_RDONLY, 0);
‒ /etc/passwd (O_RDONLY) 파일을 읽기모드 로 열기
- sd1= socket(PF_INET, SOCK_STREAM, 0);
‒ 스트림형 소켓 열기
- sd2= socket(PF_INET, SOCK_DGRAM, 0);
‒ 데이터그램형 소켓 열기
- fd2= open("/etc/hosts",O_RDONLY,0);
‒ /etc/hosts (O_RDONLY) 파일을 읽기모드 로 열기
- gettablesize() = 1024
1. 파일 디스크립터의 최대값 64~ 1024
2. gettablesize() 는 프로세스에서 개설 가능한 최대 소켓 수를 알려준다.
**■ 파일 디스크립터가 부터 배정되는 이유 3
‒ 0, 1, 2번은 이미 표준 입 출력 및 표준 에러 출력으로 사용됨
**************************************************
- 소켓 구조체 .
소켓 주소는 클라이언트 혹은 서버의 구체적인 주소를 표현하기 위해 필요하다.
주소체계(address family), IP 주소, 포트번호로 구성.
struct sockaddr
{
u_short sa_family;
char sa_data[14];
};
1. 구성
2바이트 address family
-> u_short는 unsigned short로 types.h 헤더 파일에 정의됨.
14바이트의 주소(IP주소 + 포트번호)
2. IP주소와 포트번호를 구분하여 쓰거나 읽기가 불편함.
- sockaddr_in 구조체를 대신 사용.
인터넷 전용 소켓주소
struct in_addr{
u_long s_addr;
};
struct sockaddr_in{
short sin_family;
u_short sin_port;
struct in_addr sin_addr;
char sin_zero[8];
};
1. 인터넷 전용 소켓주소 (sockaddr_in)
1.주소체계 sin_family
- AF_INET (인터넷 주소 체계)
-> socket()으로 소켓을 개설시 프로토콜을 PF_INET으로 지정한 소켓에 대한 주소 체계.
-AF_UNIX (유닉스 파일 주소 체계)
-> 값은 2로 셋팅 되어 있음.
- AF_NS (XEROX 주소 체계)
-> 값은 2로 셋팅 되어 있음.
2. sin_port
16 bit port num
3. struct in_addr 구조체
-32 bit ip address 저장할 구조체
4. sin_zero[8]
-전체 크기를 16바이트로 맞추기 위한 dummy
-sockaddr 구조체와 호환성을 위해 사용함.
**********************************************************
소켓 사용절차
1. 전제조건
1. 클라이언트- 서버 통신 모델에서 항상 서버 프로그램이 먼저 수행되어야한다.
서버 socket -> bind () -> listen() -> accept () -> send() / recv() ->
클라이언트 socket -> connet() -> recv() / send ()->close()
2. 서버는 socket을 호출하여 통신에 사용할 소켓 개설
1. 리턴된 소켓번호 , 소켓주소를 bind() 호출후 연결
2. bind()
소켓번호는 응용 프로그램 내에서만 알고 있는 통신 창구 번호
소켓주소는 네트워크 시스템만 아는 주소
bind()는 이들을 묶어야 응용 프로세스와 네트워크 시스템간의 데이터 전달이 가능함
3.listen()
서버는 listen을 호출하여 수동 대기모드로 들어감.
-‒ 클라이언트로부터 오는 연결 요청을 처리 가능해짐
서버는 함수를 호출하여 클라이언트와 연결설정
클라이언트와 연결이 성공하면 가 새로운 소켓을 하나 리턴 -> 해당 소켓을 통하여 데이터 송수신.
///////////////////////////////
3. 클라이언트
socket()을 호출하여 소켓을 구성후 서버와 연결을위해 connet호출.
-접속할 상대방 서버의 소켓주소 구조체를 만들어 함수의 인자로 줌
-클라이언트는 서버와 달리 를 호출하지 않음 bind()
→ 자신의 주소나 포트번호를 특정한 값으로 지정해 둘 필요가 없음 IP
→ 특정 포트번호를 사용할 땐 를 호출함 bind()
→ bind()를 사용하면 클라이언트 프로그램의 안정성이 떨어짐
////////////////////////
Tcp 기반 프로그램
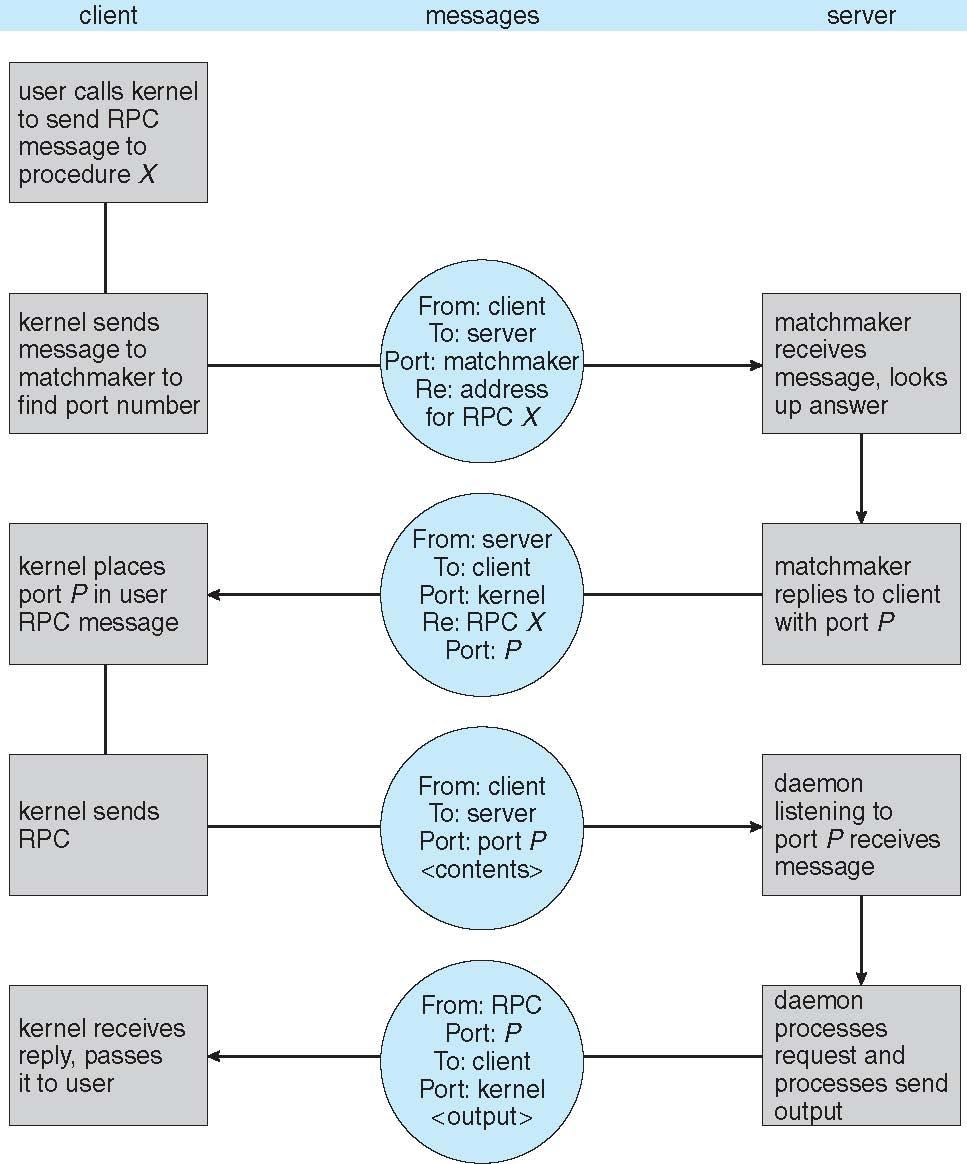
Remote Procedure Call
- 네트워크로 연결된 시스템의 프로세스간 프로시져 호출을 추상화함.
- 서비스 차별화를 위해 포트 사용 .
STUBS
클라이언트 측 스텁은 서버를 찾고 매개변수를 marshall함
서버측 스텁은 메세지를 수신하고 marshall된 매개변수의 압출을 푼후 서버에서 절차를 수행
윈도우 os의 스터브코드는 MLDL(Microsoft Interface Definition Language)로 작성된 사양에서 컴파일
다양한 아키텍쳐 설명을위하여 XDL(External Data Representation)형식을 통해 처리되는 데이터표현함
- 빅엔디안, 리틀엔디안
- 원격 통신시 로콜 통신보다 더많은 실패 시나리오가 존재함 .
메시지는 정확하게 한번 전송함
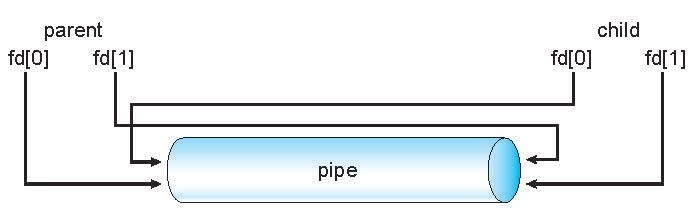
pipe
두 프로세스가 통신할 수 있도록 하는 통로
1. 통신의 단방향 양방향 고려해야함
2. 양방향인경우 HALF or full duplex인지 고려해야함 .
3. 통신 프로세스간 ( 부모 자식)과같은 관계를 고려해야함 .
4. 네트워크를 통해 파이프를 사용할수 있는지 없는지 고려해야함
1 Ordinary pipes
- 생성한 프로세스 외 외부에서 접근 할수 없는 파이프라인
- 일반적으로 상위 프로세스는 파이프를 생성하고 파이프를 사용하여 하위 프로세스와 통신함.
- 생산자 소비자 방식으로 통신이가능함
- 생산자는 한쪽 끝(파이프의 끝에 쓰기)에 write
- 소비자는 다른 한쪽끝에서 읽음
즉 단방향 통신 이며 상위 하위 프로세스의 관계가 있어야함
2. Named pipes
- 부모 자식 관계 없이 접근가능
- 양방향 통신임 ,
- 여러 프로세스가 통신을 위해 명명된 파이프를 사용할 수 있음 .
Sysnchronization
- 프로세스는 동시에 실행할 수 있음
- 언제든지 프로세스는 중단될 수 있고 부분적으로 실행가능
- 공유 데이터에 대한 동시 접근으로 데이터 불일치가 발생할수도있음. *** 쓰고 읽고의 동기화시 시간차발생문제
- 데이터 일관성을 유지하고자하면 Cooperating process의 균형을 보장하는 방식이 필요
Message passing 은 block , non-block이 될수 있음 .
Block이 대게 Synchronous라고 생각하고 non-block은 asyncrous라고 생각하자.
1. Blocking
<1.1> block send - sender가 메세지를 받을떄까지 sender는 차단하는 방법 .
<1.2> block receive - receiver가 메세지를 다쓸때까지 recv 차단
2. Non-blocking
<2.1> send - sender는 메세지를 계속 보냄 .
<2.2> receive - receiver는 허용가능한 메세지, NUll메시지, 다양한 조합이 가능한 메세지를 계속받음 .
**Buffering
메세지 큐가 링크에 접근하는 세가지 방법
- Zero Capacity - 링크 큐에 메세지가 없음. / sender는 receiver 대기랳야함 .
- Bounded capacity - n개의 적절한 길이의 메세지 / 링크가 가득차면 sender는 대기해야함
- Unbounded capcity - 무한한 길이의 메시지 -> sender는 기다릴 필요가 없어짐 .
#LPC(adavanced local procedure call )
전제조건
1. 모든 버퍼는 가득 차있음
2. 가득 찬 버퍼의 수룰 추적하는 카운터를 가지고있음.
3. 처음 카운터는 0임
4. 새로운 버퍼 생성후 생산자에 의해 증가하고 소비자가 버퍼카운트를 감소시킴
/*for producer */
while (true)
{
/* produce an item in next produced */
while (counter == BUFFER_SIZE) ;
/* do nothing */
buffer[in] = next_produced;
in = (in + 1) % BUFFER_SIZE;
counter++;
}
/* for consumer */
while (true) {
while (counter == 0)
; /* do nothing */
next_consumed = buffer[out];
out = (out + 1) % BUFFER_SIZE;
counter--;
/* consume the item in next consumed */
}Race Condition
두개 이상의 cocurrent한 프로세스 혹은 스레드들이 하나의 자원에 접근하기 위해 경쟁하는 상태
// counter++ producer
reg1 = cnt;
reg1 = reg1+1;
cnt = reg1;
// cnt-- consumer
reg2 = cnt;
reg2 = reg2 -1;
cnt = reg2;
//consider the execution interileaving with 'cnt = 5'
S0: producer execute register1 = counter {register1 = 5}
S1: producer execute register1 = register1 + 1 {register1 = 6}
S2: consumer execute register2 = counter {register2 = 5}
S3: consumer execute register2 = register2 – 1 {register2 = 4}
S4: producer execute counter = register1 {counter = 6 }
S5: consumer execute counter = register2 {counter = 4}Sol condition
- Mutual Exclusion (상호 배제 )
: 어떤 프로세스가 임계 영역을 수행중이면 다른 모든 프로세스는 그 영역에 들어갈수 없다.
- Progress(진행 )
: 임계 영역에 들어간 프로세스가 있지 않은 상태에서 임계 영역에 들어가려는 프로세스가 있다면 들어가야함.
임계영역에 있는 프로세스 외에는 다른 프로세스가 임계 영역에 진입하는 것을 방해하면 안된다.
- Bounded Waiting (한정 대기 )
starvation상태를 방지하기 위해 프로세스가 임계 영역에 들어가려고 요청한 후
다른 프로세스들이 임계 영역에 들어가는 횟수에 한계가 있어야 한다
임계 영역에 한 번 들어갔다 나온 프로세스는 다음에 들어갈 떄 제한을 준다.
Critical Section
- 자원에 아무나 접근하지 못하게 보호해야하는 영역 .
N process 시스템 고려시
- 각 프로세스에는 코드의 critical section segment 가 존재함 .
프로세스가 공통 변수를 변경후 테이블을 업데이트하고 파일을 쓰고있을 수도 있음 .
한 프로세스가 임계 구역에 존재할 때 다른 프로세스는 임계 구역에 없을 수도 있음 .
Critical section problem 이것을 해결하기 위한 프로토콜을 설계하는거라고 볼수있음 .
critical section에 진입하기위해 권한을 요청 및 종료시 종료섹션으로 따라가고 나서 나머지 세션을 따라가야함 ( ??? )
일반적인 프로세스 구조
do{
entry section
critical section
exit section
remainder section
}
while(true);
======================
do{
while(true ==j );
critical section
thre =j;
remainder section
} while(true);
Sol condition
- Mutual Exclusion (상호 배제 )
: 어떤 프로세스가 임계 영역을 수행중이면 다른 모든 프로세스는 그 영역에 들어갈수 없다.
- Progress(진행 )
: 임계 영역에 들어간 프로세스가 있지 않은 상태에서 임계 영역에 들어가려는 프로세스가 있다면 들어가야함.
임계영역에 있는 프로세스 외에는 다른 프로세스가 임계 영역에 진입하는 것을 방해하면 안된다.
- Bounded Waiting (한정 대기 )
starvation상태를 방지하기 위해 프로세스가 임계 영역에 들어가려고 요청한 후
다른 프로세스들이 임계 영역에 들어가는 횟수에 한계가 있어야 한다
임계 영역에 한 번 들어갔다 나온 프로세스는 다음에 들어갈 떄 제한을 준다.
- OS에서 critical section 핸들링 방법
1. 선점 비선점 방식에따라 접근할수 있음 .
1,1 선점 - 커널 모드에서 실행시 프로세스 선점을 허용하여 핸들링
1.2 비선점- 커널모드를 종료하거나 차단할때까지 또는 CPU를 제공할때까지 실행함 .
( 커널모드에서는 Race condition으로부터 자유로워짐 )
Peterson's Sol
두 프로세스의 동기화 문제를 해결하는 방법중에 하나.
동기화 프로세스란 ? 크리티컬 섹션의 존재로 데이터의 무결성을 침해할때 발생하는 문제를 말함.
1. 상호배제, 2.진행, 3. 유한한 대기시간 으로 문제를 해결함 .
상호 배제를 위한 병렬 프로그래밍 알고리즘으로 공유메모리를 활용하여 여러 프로세스가 하나의 자원을 함께 사용할 때 문제가 발생하지 않도록 해주는 솔루션이다 .
1. 두개의 프로세스간 상호배제 솔루션
가정
1. 로드되며 저장되는 명령어는 중단되지 않는다.
2. 변수 턴은 임계구역에 들어갈 차례를 나타낸다
3. 플래그 배열은 프로세스가 임계영역에 들어갈 준비가 되었는지 표현할때 사용한다.
4. FLAG[I] = TRUE는 프로세서 Pi가 준비되었음을 의미한다 .
의사코드
bool flag[2] // 불린 배열(Boolean array)
int turn // 정수형 변수flag[0] = false // false은 임계 구역 사용을 원하지 않음을 뜻함.
flag[1] = true
turn = 0 // 0 은 0번 프로세스를 가리킴, 1은 1번 프로세스를 가리킴P0: flag[0] = true // 임계 구역 사용을 원함
turn = 1 // 1번 프로세스에게 차례가 감
while( flag[1] && turn == 1 )
{
// flag[1] 이 turn[1] 을 가지고 있으므로
//현재 사용중임
// 임계 구역이 사용 가능한지 계속 확인
}// 임계 구역
...
// 임계 구역의 끝
flag[0] = falseP1: flag[1] = true
turn = 0
while( flag[0] && turn == 0 )
{
// 임계 구역이 사용 가능한지 계속 확인
}// 임계 구역
...
// 임계 구역의 끝 flag[1] = falsePOSIX 스레드를 활용하여 C언어로 구현한 예제
/*
* ANSI C89 source, KNF style implementation of Peterson's Algorithm.
*
* Copyright (c) 2005, Matthew Mondor
* Released in the public domain (may be licensed under the GFDL).
*
* Please fix any bugs as needed, preserving the KNF style and this comment,
* unless considered inconvenient in which case you can do whatever you want
* with the code.
*/
#include <assert.h>
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
struct pa_desc {
volatile int *f0, *f1;
int last;
};
void pa_init(void);
void pa_desc_init(struct pa_desc *, int);
void pa_desc_lock(struct pa_desc *);
void pa_desc_unlock(struct pa_desc *);
void *thread0_main(void *);
void *thread1_main(void *);
void threadx_critical(void);
int main(int, char **);
static volatile int pa_f0, pa_f1, pa_last;
/* 공유 */
#define BUCKETS 100
int gi, g[BUCKETS];
/*
* pa 시스템을 초기화 한다.
* pa 설명자를 초기화하기 전에, 프로세스에 의해 한번 호출된다.
*/
void
pa_init(void)
{
pa_f0 = pa_f1 = pa_last = 0;
}
/*
* 스레드가 사용할 pa 설명자를 초기화한다.
* 한 스레드는 id 0, 다른 스레드는 id 1을 사용한다.
*/
void
pa_desc_init(struct pa_desc *d, int id)
{
assert(id == 0 || id == 1);
if (id == 0) {
d->f0 = &pa_f0;
d->f1 = &pa_f1;
d->last = 1;
} else if (id == 1) {
d->f0 = &pa_f1;
d->f1 = &pa_f0;
d->last = 0;
}
}
void
pa_desc_lock(struct pa_desc *d)
{
for (*d->f0 = 1, pa_last = d->last;
*d->f1 == 1 && pa_last == d->last; ) ;
}
void
pa_desc_unlock(struct pa_desc *d)
{
*d->f0 = 0;
}
/*
* 첫 번째 동시 스레드의 주요 반복구
*/
/* ARGSUSED */
void *
thread0_main(void *args)
{
struct pa_desc d;
pa_desc_init(&d, 0);
for (;;) {
pa_desc_lock(&d);
threadx_critical();
pa_desc_unlock(&d);
}
/* 도달하지 않음 */
return NULL;
}
/*
* 두 번째 동시 스레드의 주요 반복구
*/
/* ARGSUSED */
void *
thread1_main(void *args)
{
struct pa_desc d;
pa_desc_init(&d, 1);
for (;;) {
pa_desc_lock(&d);
threadx_critical();
pa_desc_unlock(&d);
}
/* 도달하지 않음 */
return NULL;
}
/*
* 두 스레드를 잠금(locking)없이 수행할 때
* 병행성 처리를 정상적으로 하도록 하는 임계 함수
*/
void
threadx_critical(void)
{
int i;
/* 이중 병행성 처리를 하는 부분 */
for (i = 0; i < BUCKETS; i++)
g[i] = gi++;
for (i = 0; i < BUCKETS; i++)
(void) printf("g[%d] = %d\n", i, g[i]);
}
/*
* 이 테스트 프로그램은 피터스 알고리즘을 사용하여, 잠금(locking) 기능 없이도
* 이중 병행 작업을 수행할 수 있다. 즉, 별도의 안전장치없이 동시에 수행할 경우
* 발생하는 공유 메모리 문제를 방지할 수 있다.
*/
/* ARGSUSED */
int
main(int argc, char **argv)
{
pthread_t tid1, tid2;
pthread_attr_t tattr;
gi = 0;
pa_init();
pthread_attr_init(&tattr);
pthread_attr_setdetachstate(&tattr, 0);
/* 주: 실제 응용 프로그램은 오류 검사를 수행해야 함 */
pthread_create(&tid1, &tattr, thread0_main, NULL);
pthread_create(&tid2, &tattr, thread1_main, NULL);
pthread_join(tid1, NULL);
pthread_join(tid2, NULL);
/* 도달하지 않음 */
return EXIT_SUCCESS;
}1. 상호배제가 유지됨
2. 진행 요구조건이 만족됨
3. 제한 대기 사항이 충족함.
-Hard Ware SynChronization
- 1. 많은 시스템들은 하드웨어 레벨에서 임계영역 코드 구현을 지원해줌.
- 2. 대부분의 모든 솔루션은 locking에 기반하여 솔루션을 제공함 -> lock을 통하여 임계 영역을 보호하게됨 .
- 3. 단일한 프로세서들은 인터럽트를 비활성화 할수 있음 .
- 현재 운용중인 코드는 preemption 없이 실행할수 있음.
- 일반적인 케이스로 다중 프로세스 시스템에서는 비효율적임.( OS는 광범위한 확장이 가능하지 않음 )
- 최근 하드웨어는 특수한 하드웨어 명령을 제공함
- 1. atomoic = non-interruptible
- 2. 테스트 메모리 또는 설정값 또는 두 메모리의 내용교환 등이 이에속함
1. solution -
-
do{ acquire lock // - critical section - release lock // - remainder section - } while( true ) - test and set 구조 & solution
boolean test_and_set (boolean *target )
{
boolean rv = *target;
*target = true;
retrun rv;
}
// Shared Boolean variable lock, init to false
// sol
do {
while( test_and_set(&lock) )
// do nothing
//critical section
lock = false;
//remainder section
}
while(treu )
// compare and swqp instruction
int compare_and_swap(int *value , int expected, int new_value)
{
int tmp = *value;
if( *value == expected )
*value = new_value;
return tmp;
}
// exec atomically
// return the origin val of pass param "value"
// Set the variable "value" the value of the pass param " new__value"
// ony if value == expected .
// this is, the swap takes place only under this conditions.
//solution unsing compare_and_swap
//1. shared integer lock init to 0
do {
while(compare_and_swap(&lock, 0, 1) != 0)
//do nothing
// critical section
lock = 0 ;
// remainder section
}while(true)
3. Bounded-waiting Mutual Exclusion with test_and_set
do{
waiting[i] = treu;
key= treu;
while( waiting[i] && key)
key =test_and_set(&lock);
waiting[i] = false;
// critical section
j = (i+1) %n ;
while( (j != i ) && !waiting[j])
j = (j+1) % n;
if( j == i )
lock = false;
else
waiting[j] = false;
//remainder section
}
while(true);Locking
// Mutex Lock & semaphore
& Dead Lock
1. Mutex Locks = spinlock
- critical section에 접근할수 없도록 잠구는 역할을 함
- 1. critical section을 보호하기 위해 acquire()로 lock을 한다음 release()함 .
- lock의 허용 가능 불가능은 boolean 변수로 지시하게된다 .
- 2. acquire & release는 쪼개서 관리해야한다 .
- 3. 뮤텍스 락은 대기시간이 매우 길다는 단점이 있다
acquire & release instruction
boolean acquire() {
while( !available )
// busy wait
available = false;
return available;
}
boolean release() {
available = true;
}
int main()
{
acquire() // lock
//critical section
release() // lock
// remainder section
}while( true )
2. Semaphore
뮤텍스락보다 더 정교한 동기화 방법
s ; semaphore ; integer variable.
wait() == p() , signal() == v() 두개로 접근할수있다.
Semaphore Counting = 정수 값의 범위는 제한이 없을 수 있음
Binary Semaphore = 정수 값의 범위는 0과 1사이 일수 있음 . ( 뮤텍스 락과 동일 )
condition
1. 두 프로세스가 동일한 세마포어에서 동시에 Wait, singnal을 실행할 수 없음을 보장해야함 .
// S is semaphore
// define wait() & signal()
wait(s) {
while( s<= 0)
// busy wait
s--;
}
signal(s)
{
s++;
}
// consider P1 & P2 , require S1 to happen before S2
// create semaphore synch init to 0
P1:
s1;
signal(synch);
P2:
wait(synch);
s2;
// so can implement a counting semaphore S as binary semaphore
no Busy wating base Implementation Semaphore
1. 각각의 세마포어는 대기 큐와 연결되어 있음.
2. 대기 큐는 value & 리스트에 저장된 다음 주소값을 가진 pointer를 저장하고있음.
3. block & wakeup 동작으로 구현됨
3.1 block - 대기큐에 작업을 호출하는 프로세스 를 적절하게 배치
3.2 wakeup - 대기 큐에 있는 프로세스 중 하나를 제거하고 준비큐에 넣는 동작
// waiting queue items
typedef struct {
int val;
struct proc *list;
} sema;
//wait
wait(sema *s)
{
s->val--;
if( s->val <0 )
{
add this proc to s->list;
block();
}
}
//signal
signal(sema *s)
{
s->val++;
if( s->val <=0 )
{
remove a proc P from s-list;
wakeup();
}
}
&dead lock - 2개이상의 프로세스가 대기 중인 프로세스 중 하나만으로 인해 발생 할 수 있는 이벤트를 무기한 대기하고 있는 상황
&starvation - 무기한 블록상태
: 프로세스가 일시 중단된 세마포어 큐에서 프로세스를 제거할 수 없는 상황
Priority Inversion - 우선 순위가 낮은 프로세스가 높은 우선 순위 프로세스에 필요한 잠금을 보유할때 나타나는 스케쥴링 문제.
-> 우선순위 상속 프로콜을 통하여 해결함
DEAD LOCKS
시스템은 리소스로 구성되며
리소스 타입은 R1,R2,R3로 정의하겠다. 또한 각 리소스에는 WI인스턴스가 존재한다.
R1 ,R2 , R3는 레지스터로 CPU사이클, 메모리 공간, i/o디바이스 장치정보를 가질수도있다.
프로세스에서 리소스를 활용하는 방법으로는 REQUEST, USE , RELEASE 루틴을 걸쳐 사용하게된다.
** 데드락이 발생하는 조건은 4가지가 존재한다
1. 상호배제 (Mutual exclusion ) : 한번에 하나의 프로세스에서만 리소스를 사용할 수 있다.
2. 보류및 대기 ( hold and wait) : 최소 하나의 자원을 보유하고 있는 프로세스가 다른프로세스가 보유한 자원을 획득하기 위해서는 대기해야한다.
3. 선점 없음 ( No preemption ) : 자원의 입장에서 프로세스가 작업을 완료한 이후 프로세스가 선점한 자원을 해제해야한다.
4. 순환대기 ( Circular wait ) : 프로세스 셋이 존재하며 프로세스는 자자원을 사용하고 있는 프로세스가 있다면 해당 프로세스가 자원을 다쓰고 해제하기 까지 대기해야한다.
- 데드락은 시스템 콜 , 락 등에의해 발생할 가능성이 크다 .
Vertices V & Edge E 의 셋이 있을때
V 셋은 P( 시스템상의 모든 프로세스를 포함 한 셋) 와 R( 시스템상 모든 리소스타입의 집합) 셋으로 나눌수있으있으며
Request edge 이면 directed edge Pi->Rj이고
assignment edge라면 directed dege Rj->Pi이다.
Process Graph
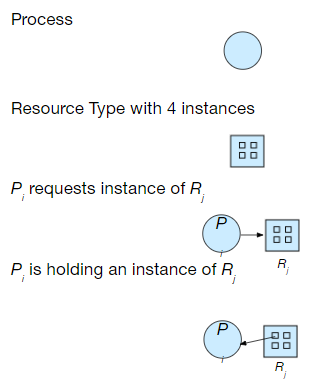
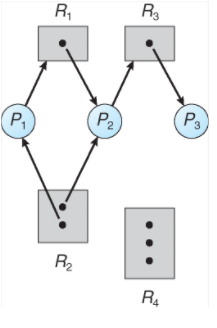
P1
프로세스가 R2 인스턴스 리소스 1개를 를 할당
프로세스는 R1 리소스에서 인스턴스 1개를 할당 요청을 보내며 (대기)중 -> P2가 해제해야 할당되는 구조
P2
프로세스가 R1, R2 리소스의 인스턴스 1개를 할당.
( R2관점에서는 더이상 할당할수있는 인스턴스가 존재하지 않으므로 타 프로세스가 할당요청을 보내면 해당 요청을 보낸 프로세스는 대기해야함 )
프로세스는 R3리소스 할당 요청함 ( 인스턴스가 1개이기때문에 대기상태 )
P3 S1 왼쪽
프로세스는 R3리소스를 할당하여 사용중 ( 해제시 P2 는 R3를 할당 받음 )
P3 S2 오른쪾
프로세스는 R3 리소스를 할당받은 상황이며 R2리소스에 요청을 보낸후 대기상황
-> S2의 상황인경우 P1, P2 P3 대기상태인 무한대기의 상황이 발생할 가능성이 있기때문에 데드락상황이 발생할수도 있음.
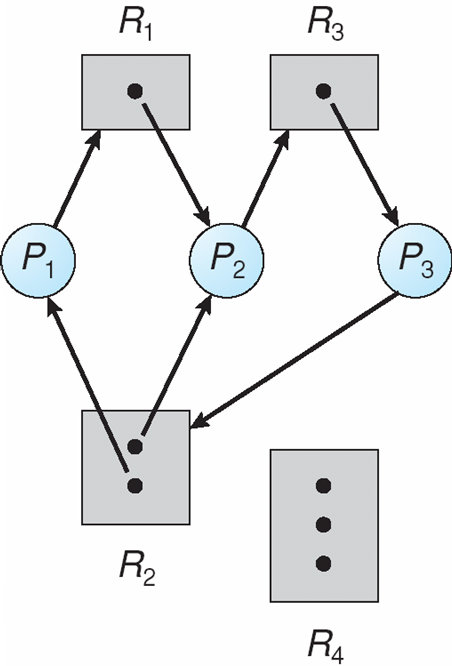
P1
프로세스는 R2리소스를 할당받고 R1에게 리소스 요청 ( 대기 )
P2
프로세스는 R1리소스를 할당받은 상황 (NO WAIT )
P3
프로세스는 R1리소스 할당 및 R2에게 요청을 보낸상황 ( 대기)
P4
R2리소스에 할당을 받은상황 ( NO WAIT)
즉P2 P4가 리소스 해제시 대기상황은 풀리며 데드락상황은 발생하지 않는다.
즉 그래프에 사이클이 없는 경우는 데드락이 없는경우이고
사이클이 존재한다면 1. 리소스 유형당 하나의 인스턴스만 존재시 데드락 상황 2. 여러 인스턴스 존재시 데드락 가능성이 있는상황으로 정리할수 있겠다 .
데드락 핸들링 방법
1. 데드락 상태를 선 방지할수 있으며 2. 데드락 상태를 피할수 있게 핸들링하는것이 목적이다 .
- 상호배제
공유 할수 없는 리소스에 대해 보유해야한다.
- 보류 및 대기
프로세스가 리소스를 요청시 다른 리소스를 보유하지 않도록 보장해야한다.
프로세스가 실행 하기 전 모든 리소스를 요청하고 할당받도록 하거나, 할당된 프로세스가 없는 경우에만 프로세스가 리소스를 요청하도록 허용해야한다.
- No preemption
일부 자원을 보유하고 있는 프로세스가 즉시 할당할 수 없는 다른 자원을 요청하면 현재 보유하고 있는 모든 자원을 해제 하고 선점된 리소스는 프로세스가 대기 중인 리소스 목록에 추가한다.
프로세스는 이전 리소스와 요청 중인 새 리소스를 다시 얻을 수 있는 경우에만 다시 시작한다.
순환대기
- 모든 리소스 유형의 전체 순서를 부과하고 각 프로세스가 증가하는 열거 순서로 리소스를 요청하도록 한다.
데드락 회피
가장 쉬운방법은 각 프로세스가 필요하는 유형의 리소스 최대 수를 지정해주는것이다.
데드락 회피 알고리즘은 자원 할당상태를 동적으로 검사하기 때문에 순환 대기 조건이 절대 있을 수 없음을 확인한다. 즉 리소스 할당 상태는 사용가능한 리소스와 할당된 리소스의 수, 프로세스의 최대 요구사항으로 정의한다.
데드락2 safe state
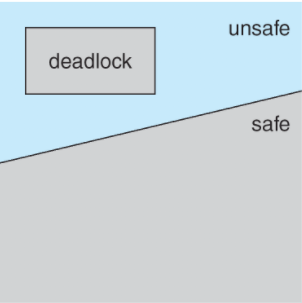
프로세스가 사용가능한 리소스를 요청시 시스템은 즉시 할당하는것이 시스템을 안정한 상태로 유지하는것인가를 결정해야한다.
시스템안의 각 프로세스 PI에대한 모든 프로세스의 시퀀스 <P1,....PN>이 존재한다면 , 시스템은 각 프로세스에 대해 pi가 요청할 수 있는 자원이 현재 사용가능한 자원 + 보유자원 으로 충족할 수 있는 조건이고 존재하는경우 안전한 상태에 있다고 할수 있다 .
즉 프로세스의 요구를 즉시 사용할수 없는 경우 프로세스는 타 프로세스가 완료될때까지 대기해야한다.
타프로세스의 작업이 완료되면 프로세스는 필요한 리소스를 얻고 실행후 할당된 리소스를 해제하여 종료할수 있다.
프로세스가 종료된다면 다른 프로세스가 필요한 리소스를 얻어 사용할수 있다.
즉 시스템이 안전한 상태일 경우 데드락상황이 아니다.
하지만 안전하지않을때 데드락 가능성이 제시되고 회피하게된다면 시스템이 안전하지 않은 상황을 겪지 않도록 보장한다.
알고리즘 종류로는
단일 인스턴스 리소스타입인경우 할당 요청 그래프를 이용하고
멀티 인스턴스 리소스타입인경우 은행알고리즘을 사용한다 .
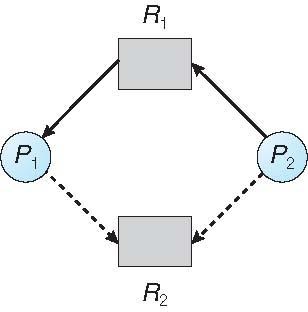
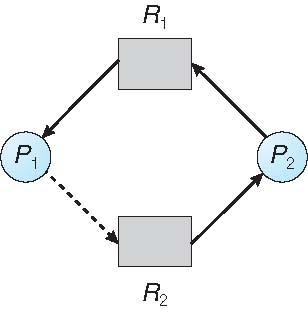
- 점선은 프로세스가 리소스를 요청 할 수있음을 나타내고 Claim edge이다.
- request edge는 claim edge에서 리소스요청 시 request edge로 변환
- assignment edge는 request edge에서 자원이 프로세스에 할당될때 변환
claim edge : 할당후 프로세스에 의하여 해제시 다시 할당에지에서 claim edge로 변환
자원은 시스템에서 priori를 요구한다.
프로세스가 리소스를 요청한다고 가정한다면 요청에지를 할당에지로 변환해도 자원 할당그래프에 주기가 형성되지 않은경우에 요청이 승인될수 있다.
-은행 알고리즘
다중 인스턴스
각 프로세스는 최대 claim 선점을 사용해야함
프로세스가 자원에 요청할때 대기해야됨
프로세스가 모든 리소스를 얻을때 유한한 시간안에 반환해야함
은행 알고리즘 데이터구조
n ; 프로세스 수
m ; 리소스 수
Available: Vector of length m. If available [j] = k, there are k instances of resource type Rj available
Max: n x m matrix. If Max [i,j] = k, then process Pi may request at most k instances of resource type Rj
Allocation: n x m matrix. If Allocation[i,j] = k then Pi is currently allocated k instances of Rj
Need: n x m matrix. If Need[i,j] = k, then Pi may need k more instances of Rj to complete its task
Need [i,j] = Max[i,j] – Allocation [i,j]
- 안정성 알고리즘
Work , Finish 는 벡터 길이 M N

-프로세스 Pi에 대한 리소스 요청 알고리즘

데드락 감지
1. 시스템으로 데드락 상황 허용
2. 감지 알고리즘
3. 복구 계획 구조
각 리소스타입이 단일 인스턴스인경우
대기 그래프로 그림
- 노드는 프로세스
- Pi -> Pj 는 Pi는 Pj를 대기하고있음.
- 그래프에서 주기 검색 알고리즘을 주기적으로 호출후 주기가 생긴다면 데드락 상태가 존재한다.
- 그래프에서 주기를 감지하는 알고리즘은 n^2개의 연산이 필요하고 n은 그래프의 vertices의 수이다.
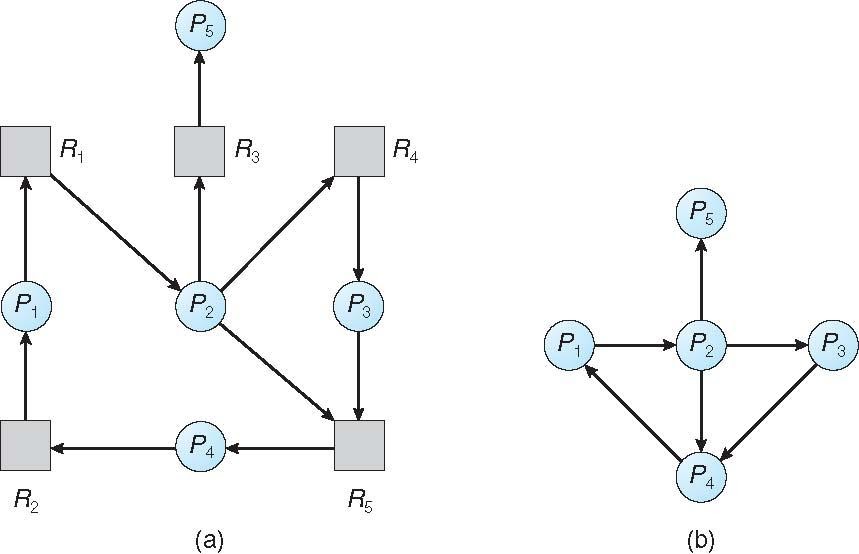
리소스 유형에 따른 여러 인스턴스
- Available: A vector of length m indicates the number of available resources of each type
- Allocation: An n x m matrix defines the number of resources of each type currently allocated to each process
- Request: An n x m matrix indicates the current request of each process. If Request [i][j] = k, then process Pi is requesting k more instances of resource type Rj.
디텍션 알고리즘

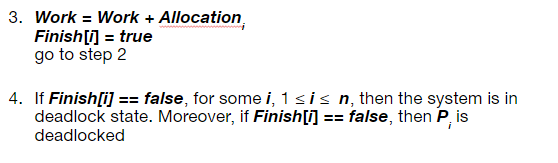
알고리즘은 시스템이 교착 상태인지 여부를 감지하기 위해 O(m x n^2) 작업의 순서가 필요하다.
Bounded Buffer Problem
1. N개의 버퍼 각각은 한개의 요소를 담을수 있음.
2. 세마포어 뮤텍스 (락 ) 초기화값은 1
세마포어 풀( 꽉찬상황) 초기화값은 0
세마포어 empty 초기화 값은 n이다.
// producer
do{
// produce an item in next produeced
wait(empty)
wait(mutex)
// add next produced to the buffer
signal(mutex)
signal(Full)
}
while(treu)
//consumer
do{
wait(full);
wait(mutex);
//remove an item from buffer to next_consumed
}while(true)
Reader-Writer Problem
데이터 셋은 현 프로세스들 중에 하나를 공유함.
1. Readers - 오직 데이터를 읽기만함 : 데이터를 업데이트 하는 동작은 하지않음.
2. Writers - 읽고 쓸수 있음.
문제 . Reader가 많은 상황에서 동시간대에 파일을 읽는 상황에서. 오직 한개인 Writer가 동일 시간에 공유데이터를 점유하여 접근함.
Reader 와 Writer를 고려하여 어떻게 변형해야하는가 . 조건으로 모두 우선순위가 동일한 조건이다.
공유하는 데이터는 데이터 셋 , 세마포어 RW-뮤텍스 1 , mutex 1, readcnt 0이다.
- sol
1. 작성자가 공유 객체를 사용할 권한이 없다면 READER가 계속 대기 하지않는다.
2. 작성자가 준비된다면 최대한 빨리 쓰기를 수행한다.
둘다 STARVATION이 있어 더 많은 VARIATIONS를 이끌수 있다.
커널에 READ -WRITE LOCK을 제공하여 해결할수 있음.
//writer
do{
wait(rw_mutex)
// writing is perform
signal(rw_mutex);
}while(treu);
//reader
do{
wait(mutex)
read_cnt++;
if(read_cnt ==1 )
wait(rw_mutex);
signal(mutex)
//read performed
wait(mutex)
read_cnt--;
if(read_cnt==0)
signal(rw_mutex);
signal(mutex);
}while(treu);
Dining-Philosophers
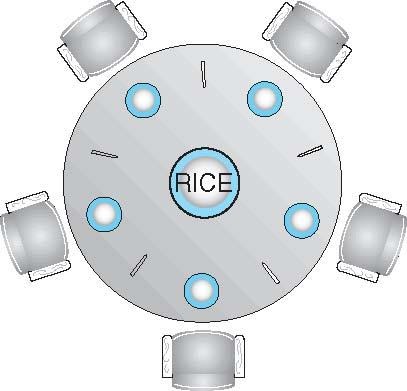
Philosophers spend their lives alternating thinking and eating
Don’t interact with their neighbors, occasionally try to pick up 2 chopsticks (one at a time) to eat from bowl
Need both to eat, then release both when done
In the case of 5 philosophers
Shared data
Bowl of rice (data set)
Semaphore chopstick [5] initialized to 1
데드락 핸들링
1. 최대 4명의 철학자가 테이블에 동시에 앉을 때
철학자가 포크를 둘 다 사용할 수 있는 경우에만 포크를 줍도록 허용
( 임계영역 안에서 포크를 줍도록 수행 하고 .
홀수번째 철학자
먼저 왼쪽 젓가락
다음 오른쪽 젓가락
짝수 철학자는 오른쪽 젓가락
먼저 집은 다음 왼쪽 젓가락 집도록)
do {
wait (chopstick[i] );
wait (chopStick[ (i + 1) % 5] );
// eat
signal (chopstick[i] );
signal (chopstick[ (i + 1) % 5] );
// think
} while (TRUE);Monitors
Scheduling
Process Scheduling
- 프로세스는 다양한 QUEUE사이에서 마이그레이션을 진행함.
- CPU 사용을 최대화, 시간 공유를 위해 프로세스를 빠르게 전환해야한다.
- 프로세스의 스케쥴링 큐 유지
- Job queue - 시스템의 모든 프로세스 집합
- Ready queue - 메인 메모리에 존재하고 실행 대기중인 프로세스 집합
- Device Queue - I/O 장치를 대기하는 프로세스 집합
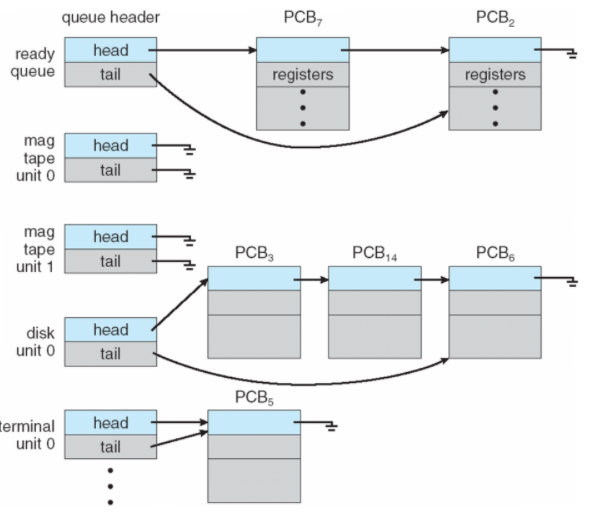

Schedulers
CPU Scheduling
: 멀티 프로그래밍으로 얻을 수 있는 최대 CPU 활용방법
- Short-term scheduler ( CPU scheduler )
- 다음에 실행할 프로세스를 Ready queue에서 선택후 CPU 할당.
- 빠른속도의 성능이 요구됨 ,자주 호출되는 특징이 있음
- Dispatcher모듈을 활용하여 프로세스의 CPU제어.
- Switching context
- switching to user mode
- 프로그램을 재시작하기 위해 사용자 프로그램을 적절한 위치로 이동하는 기능
- -Dispatch latency : 프로세스를 중지하고 다른 실행을 시작하는데 걸리는 시간
- Short-Term에서 Queue 명령 및 case
- <1> State 전환 case1. ( Running -> Waitting state )
- <2> State 전환 case2. ( Running -> Ready state )
- <3> State 전환 case3. ( Waitting -> Ready state )
- <4> 프로세스 종료
- 1 & 4 는 nonpreemptive , 2 ,3 은 preemptive
- 다른 모든 schedulling 은 preemptive
- <1> shared data 접근 고려해야함
- <2> kernel mode에서 preemptive 고려해야함
- <3> OS가 활동중 발생하는 인터럽트 고려해야함
- Long-term scheduler ( job scheduler )
- ready queue로 가져와야 하는 프로세스를 선택함.
- Multi Programing 제어 함.
- ready queue로 가져와야 하는 프로세스를 선택함.
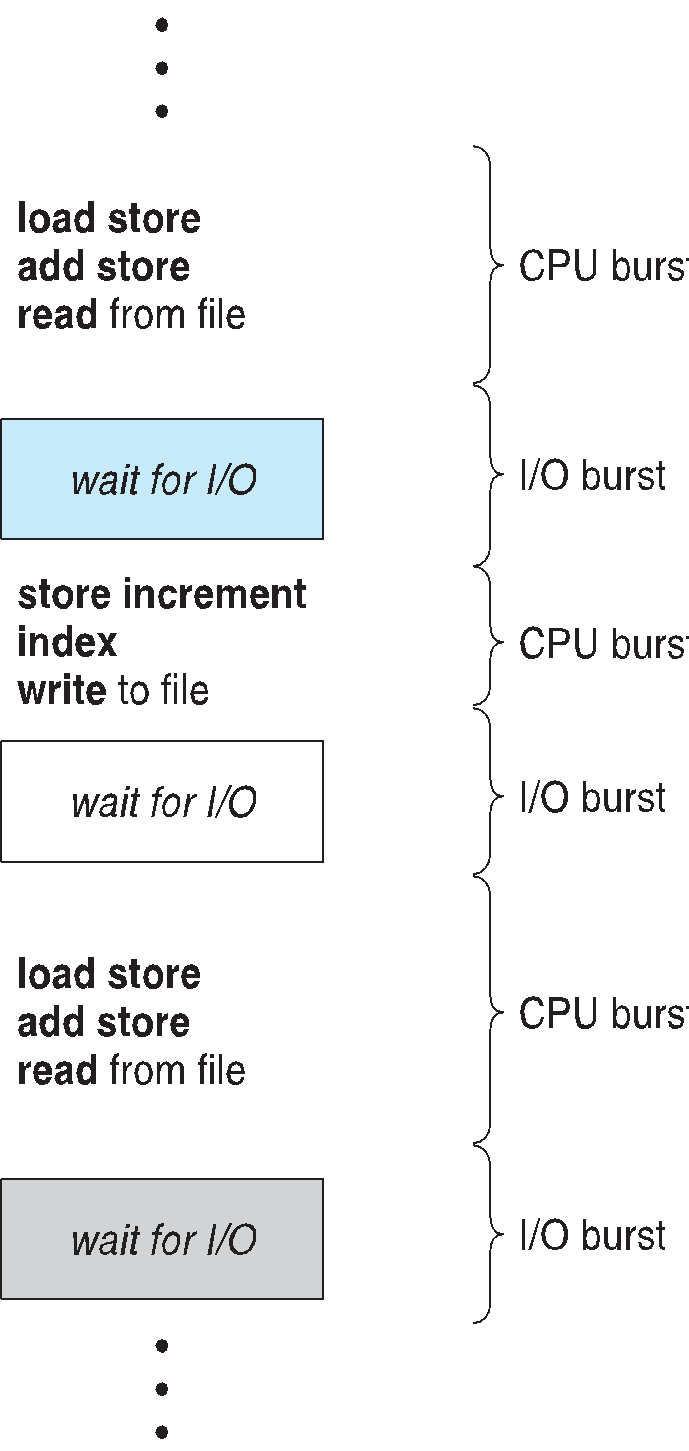
- CPU - I/O Burst
- I/O-Bound Process : 매우 짧은 CPU Burst , 계산보다 I/O 처리에 더 많이 시간을 소비함
- CPU Bound Process : 매우 긴 CPU Burest, 계산에 더많은 시간을 할당함 .
- CPU / I/O Burst
- 프로세[스 실행 CPU 실행 - I/O 대기 주기로 구성됨
- CPU burst는 I/O burst 를 따라감
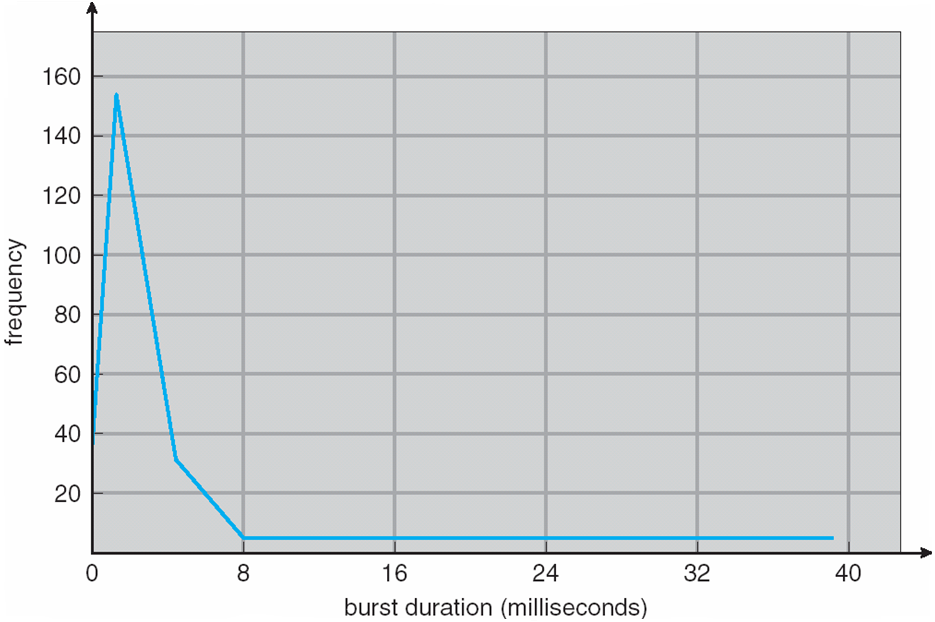
- CPU burst 분포가 주요 연구방향인듯함..
스케쥴링 기준
1. CPU 사용률 : CPU를 최대한 바쁘게 유지
2. 처리량 : 시간 단위당 실행을 완료하는 프로세스 수
3. 처리 시간 : 특정 프로세스를 실행시 걸리는 시간
4. 대기 시간 : 프로세스가 준비 대기열에서 대기한 시간
5. 응답시간 : 출력이 아닌 요청시 첫 응답이 생성될 떄까지의 소요시간
Scheduling Algorithm 최적화 기준
최대 CPU 사용률 , 최대 처리량 , 최소 처리 시간 , 최고 대기 시간, 최소 응답 시간
Scheduling Algorithm
FCFS ( First-Come, First-Served )


프로세스의 도착순서는 P1, P2 ,P3순으로 도착한다고 가정하면
대기시간과 평균 대기시간은
P1 =0 , P2 = 24 , P3= 27이고
평균은 각 프로세스의 대기시간의 합을 프로세스의수로 나눈값이된다 즉 17
ConVoy effect 는 짧은 프로세스를 앞으로 두고 긴 프로세스를 뒤에 배치하는 효과이다
해당 효과를 적용하여
P2,P3,P1의 순으로 프로세스가 도착한다고 가정한다면 간트차트는 아래와 같으며

각 프로세스의 대기시간은 P1 = 6, P2= 0 P3=3이된다.
즉 프로세스의 평균 대기시간은 3이다.
하지만 Convoy effect를 적용하기 위해서는 하나의 CPU-Bound와 i/o bound 프로세스를 고려해주어야 한다 .
SJF( Sohrtest - Job -First )
각 프로세스의 다음 CPU burst의 길이와 함께 결합하여 사용.
해당 길이를 사용하여 가장 짧은 시간의 프로세스로 스케쥴링에 사용함.
최적화 방법
주어진 프로세스 셋의 최소 평균 대기 시간을 얻어서 최적화한다.
cpu길이를 예측하는것이 어렵다.


평균 대기시간 ( 0+3+9+16 ) /4 = 7
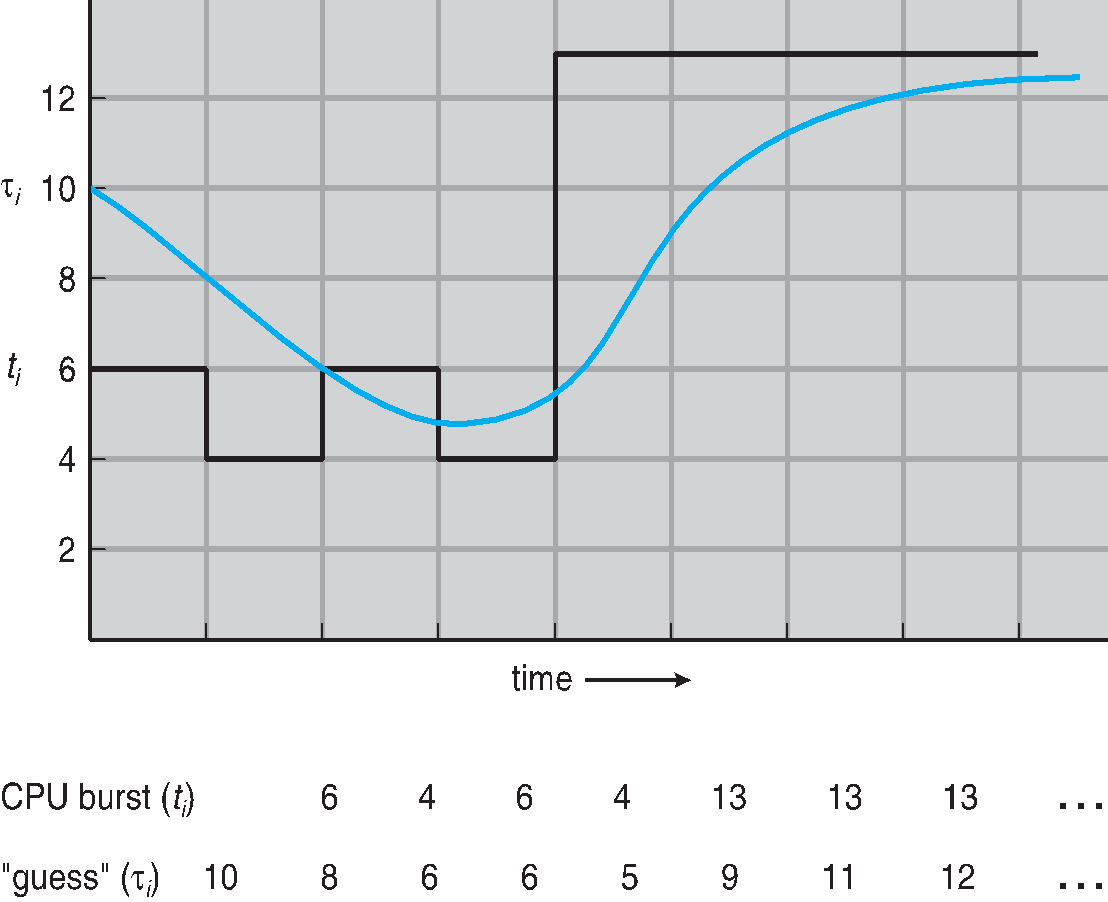
다음 CPU Burst 길이 추정하기
1. 오직 길이만 추정할수 있음 . ( 이전의 길이와 유사해야 추정가능함 )
2. 예측된 cpu burst가 가장 짧은 프로세스를 선택
3. 지수 평균을 사용 및 이전 CPU버스트 길이를 사용하여 결정 .

공통적으로 alpha 계수는 1/2로 세팅함.
Preemtive 버전은 Shortest-remaining-time-first로 부름. ( SRTF 는 더 공부 해보아야 겠다 )


프로세스 도착시간 실행시간
P1 0 8
P2 1 4
P3 2 9
P4 3 5
평균 대기 시간
[(10-1)+(1-1)+(17-2)+5-3)]/4 = 26/4 = 6.5
Priority
1. Priority num은 각 프로세스와 매핑한다.
2. CPU는 Priority가 높은 프로세스에 할당 ( 가장 작은 정수 -> 가장 높은 우선순권을 가지는 형식)
3. Preemptive 와 NonPreemptive 방식이 있다.
위의 SJF 방식은 우선순위를 CPU Burst 예측시간의 inverse한 우선순위 선점 방식이다.
-Starvation 문제 [ 우선순위가 낮으면 프로세스 실행이 무한연기되는 단점이 존재한다 ]
해결책은 aging 기법으로 시간이 지남에 따라 프로세스 우선순위를 높이는 방법이다.
프로세스 Burst Time Priority
P1 10 3
P2 1 1
P3 2 4
P4 1 5
P5 5 2

평균 대기시간 - 8.2
RR
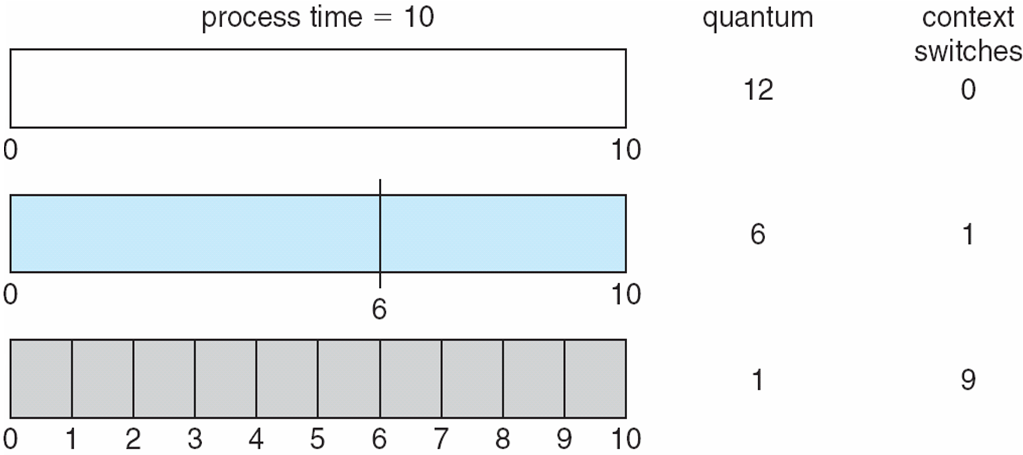
각각의 프로세스는 아주 작은 시간구간에 대한 cpu 시간 quantum q를 얻게된다.
이후 해당 q시간이 지나면 프로세스 선점이 진행되고 ready queue의 끝에 추가가 진행된다.
만약 대기열에 n개의 프로세스가 존재하며 q이면 프로세스는 한번에 q시간단위의 chunk로 CPU시간의 1/N을 획득한다. (N-1)q시간 단위 이상 대기하는 프로세스가 존재하지 않는다면
타이머는 다음 프로세스를 예약하기 위해 모든 q를 중단하게된다.
q large = FIFO
q small = q는 매우 커야한다 . context switch관점에서 오버해드 문제로 .
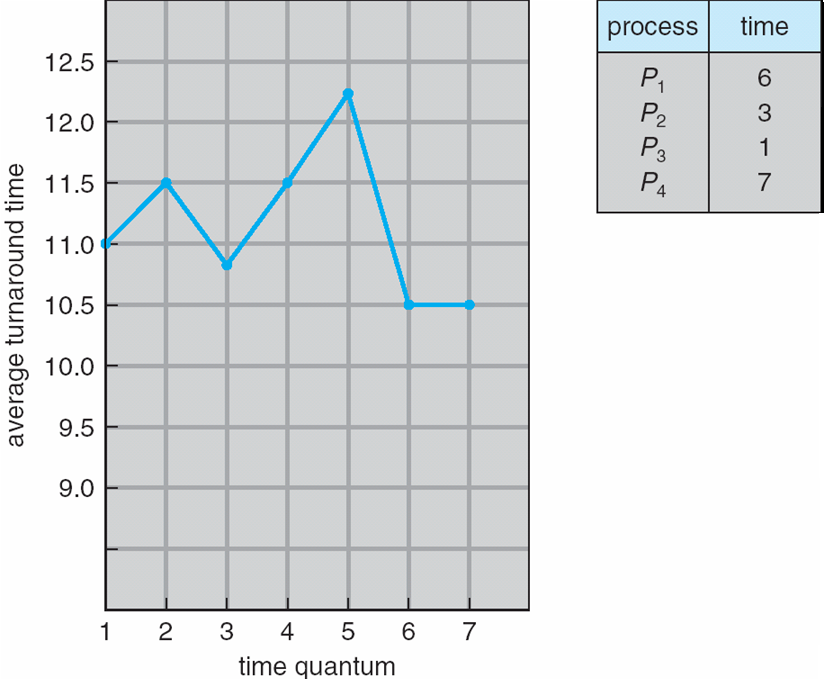
Process Burst Time
P1 24
P2 3
P3 3

평균적으로 sjf보다 응답이 빠르다 .
Time Quantum and Context Switch Time
80% of CPU bursts should be shorter than q
MultiLevel Queue & Multi Feed back Queue
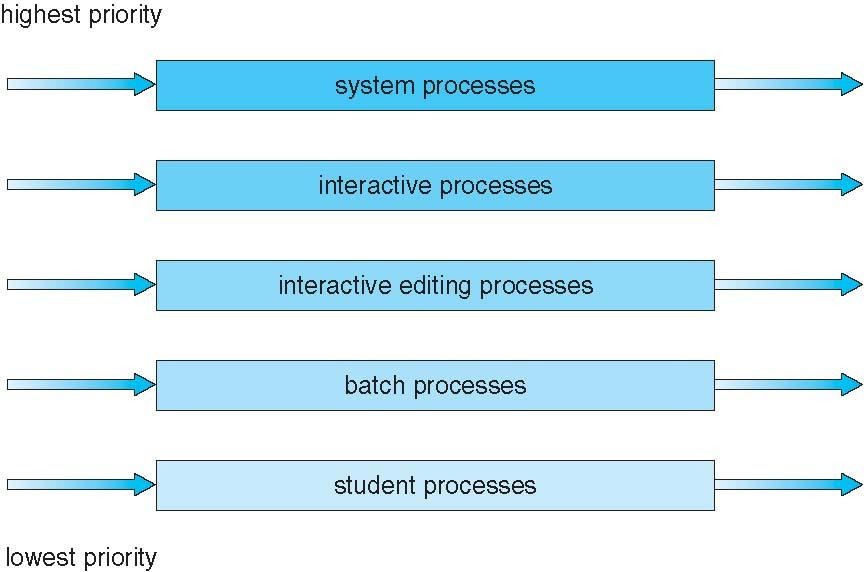
MultiLevel Queue
1. Ready queue 는 Foreground , background로 분리
2. 프로세스는 주어진 큐를 사용하여 작업을 처리함.
3. Foreground - RR / Background - FCFS
4. 스케쥴링은 큐사이에서 수행되어야함
Fixed priority 스케쥴링 ( Foreground에서 모두제공후 background에서 ) - Starvation 가능성 존재
5. Time slice - 각 큐는 프로세스 간 스케쥴링을 할수있는 특정 CPU 시간을 얻어야함
EX) 80% Foreground RR / 20% background FCFS
Multi Feed back Queue
1. 프로세스는 다양한 Queue를 이동할수 있음.
Multi Feed back Queue -aging- 구현 루틴
1. #queue
2. queue의 스케쥴링 알고리즘
3. 프로세스 업데이트 시 방법 결정
4. 프로세스 다운시 방법 결정
5. 프로세스 서비스 필요시 프로세스에 들어갈 큐 결정 방법 결정
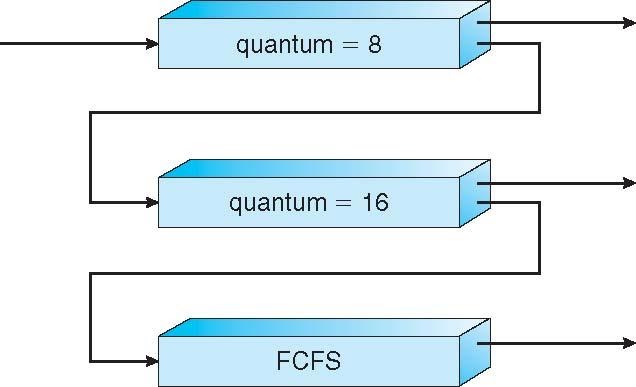
예제
1. Q 는 세개
1.1 Q0 , Q1, Q2 존재
1.2 Q0 = RR & q time 8 , Q1 - RR time quantum 16, Q2 - FCFS
1.3 스케쥴링방법
Q0로 새로운 작업이 들어감 -> CPU 확보시 8ms를 획득함 -> Q1에서 다시 16ms 추가로 획득 -> 안료되지 않으면 Q2로 이동
.
Thread Scheduling
사용자 수준 스레드와 커널 수준 스레드 구별
스레드 지원시 프로세스가 아닌 스레드로 스케쥴링함
n:1 , n:n 모델 스레드 라이브러리는 사용자 수준 스레드가 LWP에서 실행되도록 스케쥴링
PCS(Process Contention Scope) : 프로세스 스케쥴링 경쟁시
SCS ( SYSTEM CONTENTION SCOPE) 시스템의 모든 스레드간의 경쟁
API를 사용하면 스레드 생성중 PCS 및 SCS를 지정할 수 있음.
PTHREAD_SCOPE_PROCESS는 PCS 스케줄링을 사용하여 스레드를 스케줄링
PTHREAD_SCOPE_SYSTEM은 SCS 스케줄링을 사용하여 스레드를 스케줄링
- Linux 및 Mac OS X는 PTHREAD_SCOPE_SYSTEM만 허용
#include <pthread.h>
#include <stdio.h>
#define NUM_THREADS 5
int main(int argc, char *argv[]) {
int i, scope;
pthread_t tid[NUM THREADS];
pthread_attr_t attr;
/* get the default attributes */
pthread_attr_init(&attr);
/* first inquire on the current scope */
if (pthread_attr_getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope\n");
else {
if (scope == PTHREAD_SCOPE_PROCESS)
printf("PTHREAD_SCOPE_PROCESS");
else if (scope == PTHREAD_SCOPE_SYSTEM)
printf("PTHREAD_SCOPE_SYSTEM");
else
fprintf(stderr, "Illegal scope value.\n");
}
/* set the scheduling algorithm to PCS or SCS */
pthread_attr_setscope(&attr, PTHREAD_SCOPE_SYSTEM);
/* create the threads */
for (i = 0; i < NUM_THREADS; i++)
pthread_create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM_THREADS; i++)
pthread_join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread_exit(0);
}
Process Scheduling
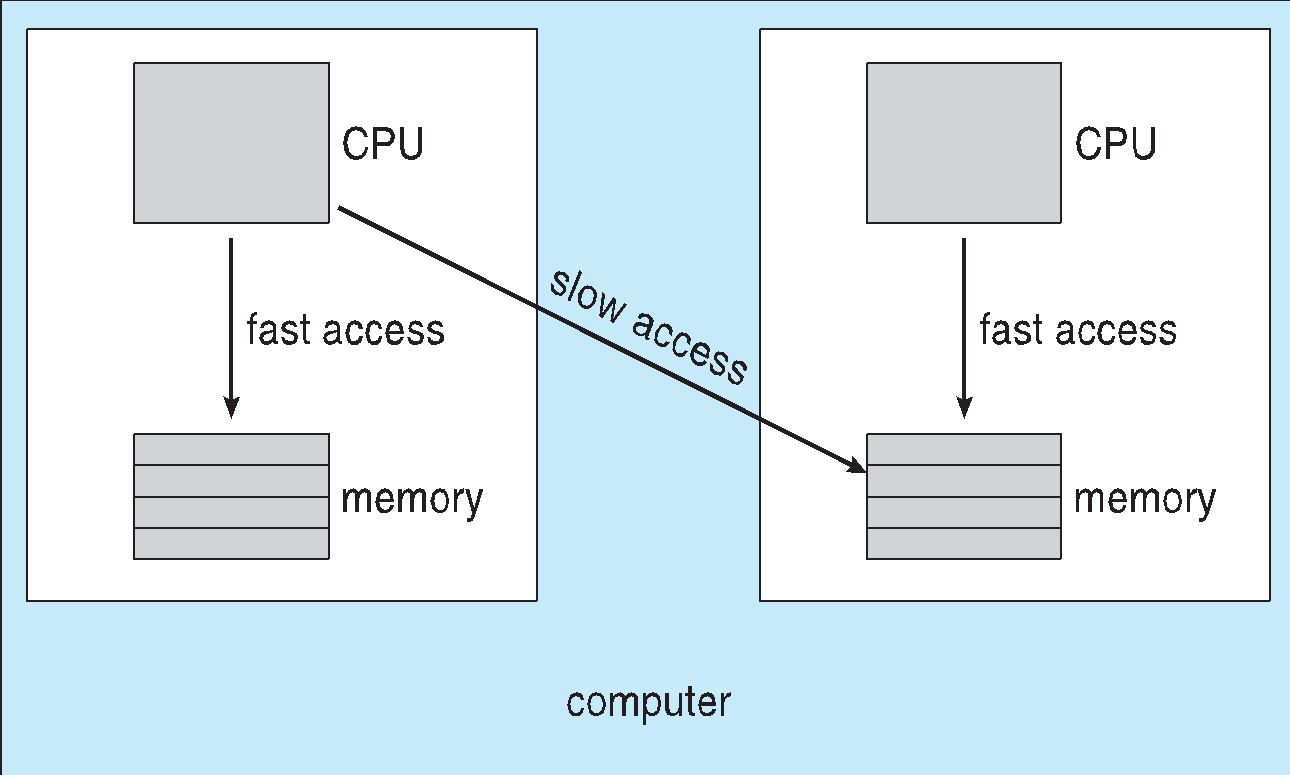
Multiple-Processor Scheduling
1. 여러 CPU사용시
멀티 프로세서 내의 Homogeneous 프로세서,
Asymmetric 멀티 프로세싱 - 단일 프로세서가 시스템 데이터 구조에 접근하여 데이터 공유의 필요성을 줄이는 구조
SMP(Symmetric Multiprocessing ) - 각 프로세서는 자체 스케쥴링하고 모든 프로세스는 공통 Ready queue에 있거나 각 프로세서에서 준비 프로세스의 자체 Ready queue가 존재함.
프로세서 선호도
1. 현재 실행 중인 프로세서 에대한 선호도
1. soft > hard> 프로세서 셋포함 변형 순
Load Balancing
smp의경우 효을위해 모든 CPU를 로드 상태로 유지해야함
로드밸런싱 시도를위해 부하 분산을 시도해야한다.
푸시 마이그레이션 - 각 프로세서의 로드를 주기적으로 확인후 발견시 CPU에서 CPU로 작업을 푸시해야함
풀 마이그레이션 - IDLE한 프로세서가 사용중인 프로세서에서 대기 중인 작업을 가져오는것.
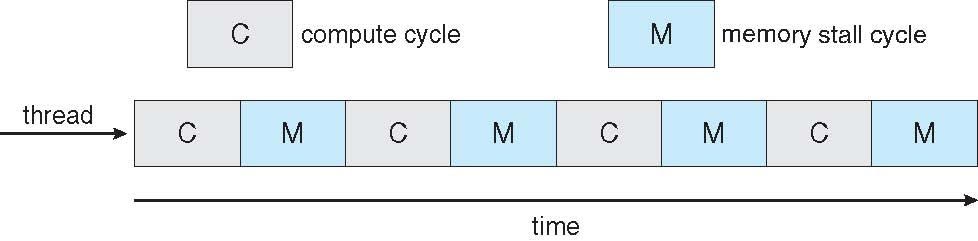
Multicore Processors
빠른 속도와 적은 전력을 소비하는 구조
코어당 다중 스레드 증가
메모리 검색의 발생시 다른 스레드에서 진행하기 위해 메모리 스톨을 활용

Real Time Cpu Scheduling
Real time System,
- Soft
프로세스의 스케쥴에 언제인지 보장되지 않음
- Hard
Deadline까지 task를 처리해야함
Soft와 hard는 지연시간 성능에 영향을 미치게됨
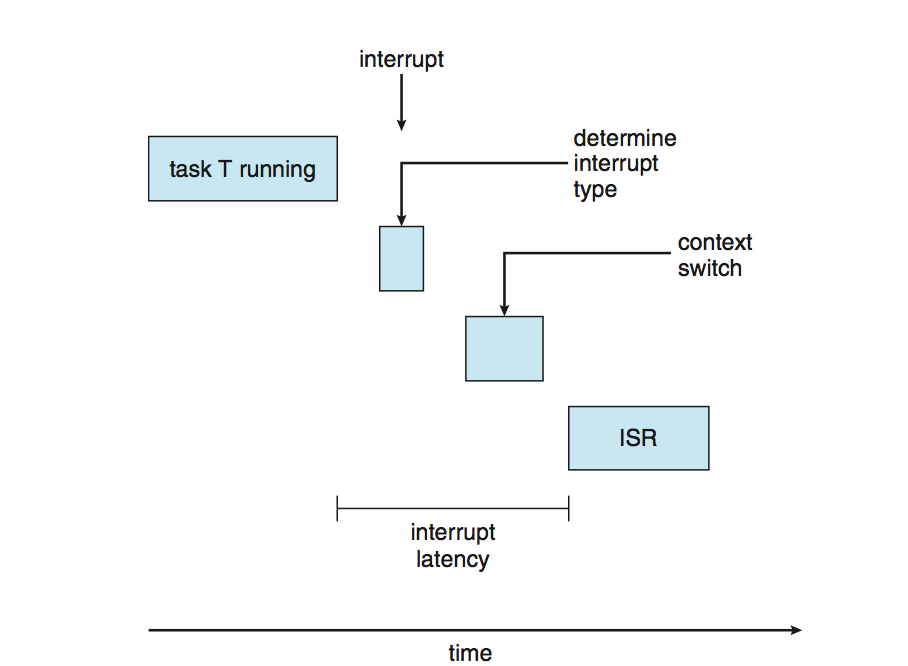
1. 인터럽트 latency
인터럽트 도착부터 인터럽트 처리하는 루틴 시작까지의 시간
2. Dispatch latency
스케쥴이 CPU에서 현 프로세스를 제거후 다른프로세스로 전환하는 시간
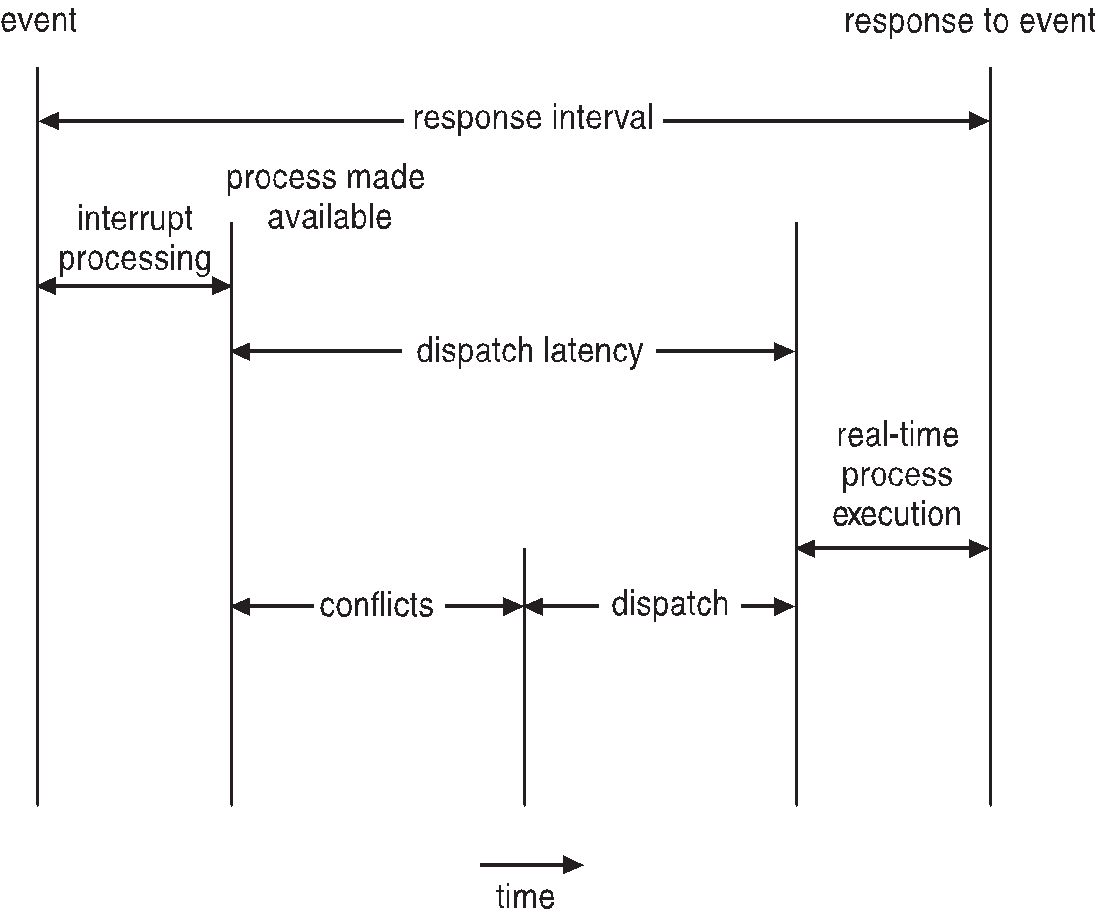
Dispatch 시간 충돌
1. 커널모드에서 실행중인 프로세스 가 우선선점함
2. 우선순위가 높은 프로세스로 인해 필요한 리소스를 우선 순위가 낮은 프로세스에 의해 해제하여 사용 .
Priority 스케쥴링 방법
1. 실시간 스케쥴링의 경우 스케줄러는 Priority 기반하여 Preemptive 스케쥴을 지원해야함
( soft 실시간만 보장이됨 )
2. hard 의경우 Deadline에 대한 조건도 체크해야함
3. 프로세스는 주기적으로 CPU가 일적간격으로 필요함
T ; PROCESSING TIME , D , DEADLINE , P PERIOD
0 <= T <= D <= P
주기는 1/P
가상화 소프트웨어는 cpu에 다수의 게스트를 스케쥴링함.
각 게스트는 자신의 CPU를 소유하지 않는다는 사실을 모름
응답시간이 느려질 가능성이 존재함
RATE MONTONIC 스케쥴링
- A priority is assigned based on the inverse of its period
- Shorter periods = higher priority;
- Longer periods = lower priority
P1 is assigned a higher priority than P2.

Missed Deadlines with Rate Monotonic Scheduling

Earliest Deadline First Scheduling (EDF)
- Priorities are assigned according to deadlines:
the earlier the deadline, the higher the priority;
the later the deadline, the lower the priority

Proportional Share Scheduling
- T shares are allocated among all processes in the system
- An application receives N shares where N < T
This ensures each application will receive N / T of the total processor tim