공룡책 - 운영체제 정리4
본 게시물은 Abraham Silberschatz의 Operating System Concepts 공룡책을 참고하며
개인적으로 공부 및 정리한 자료입니다.
소프트웨어 구조와 운영체제의 관점에서 책을 읽고 있지만 현재 메모리적 관점은 학부시절 전공에서 배웠던
디지털논리회로 , 그리고 컴퓨터구조, 임베디드 프로세싱과 더 관련이 깊어보여 전공지식을 다시 복귀하는 차원으로 추후 추가하도록 할 예정이고 이전에 POSIX시스템기반의 C언어와 파이썬을 통한 딥러닝모델, MCU보드를 활용하여 간단한 프로젝트를 진행해보고자한다 .
1.메인메모리
2.가상메모리
3.저장시스템
1. 메인메모리
배경지식
- 하드웨어 구조에서 대략적인 메모리 protection이 일어나는 상황과 addressing binding이 언제 일어나는지에 대한 논의다.
이슈 1, 속도문제 , 2. protection 이슈 -> base register & limit register로 메모리 protection을 구현함 .
0. 컴퓨터는 CPU, 메모리, storage device로 작동을 하는 구조이다.
1. 프로그램은 디스크에서 메모리로 가져온후 실행하기 위해 프로세스에 프로그램을 배치해야한다.
2. 메인메모리와 레지스터는 CPU가 직접 접근할 수 있는 저장소이다
3. 메모리 유닛은 주소 스트림, 읽기 요청 또는 , 주소와 데이터 , 쓰기 요청 스트림만 볼수 있다.
4. 레지스터는 한번의 CPU클럭동안 접근하게된다. ( one Cycle of the CPU Clock ) ,
/CPU의 레지스터는 크기가 매우 작고 접근이 빠르다 /
5. 메인 메모리는 Stall이기때문에 많은 메모리 사이클이 필요로 하게된다.
/ 메모리는 레지스터보다 비교적 크기가 큰대신 접근성이 느리다 (Many cycle of the CPU clock )
/ 메모리는 버스를 타고 데이터를 송수신하기 때문에 느리다, /
/ stall상태는 CPU가 데이터가 이동하는동안 CPU에서 아무것도 안하는 상태로 생각하자 /
5. 캐시는 메인메모리의 Stall 상태를 최소화하기위해 CPU와 레지스터 사이에 위치하고 있고 적절한 동작을 하기위해서 메모리를 보호한다 .
/ 이떄 protection 이슈로 대체로 base register와 limite register로 메모리 protection을 구현하게된다 /
/ 기본적으로 레지스터는 아래의 링크에서 보는것과같이 7개의 종류의 레지스터가 존재하고
base register는 physical addr의 최소값 , limite register는 physical addr이 가지는 최대값에 대한 정보를 가지고 있다 / 즉 이 base limite regi 를 활용하여 protection 알고리즘을 구현하게된다.
레지스터 종류 링크
레지스터


- 기본적으로 base register & limite register는 local address space을 정의한다.
- 레지스터는 기본적으로 CPU가 요청을 처리시 필요한 데이터를 일시적으로 저장하는 기억장치로 실제 컴퓨터에 데이터를 엉구적으로 저장하기 위해선 하드디스크를 이용하지만 명령을 처리할시 주소 및 명령의 종류를 저장하는 공간이 하나더 필요하게 된다 .
- 즉 명령을 처리하기위해 메모리보다 속도와 접근이 용이해야하기때문에 CPU옆에 붙어있다.
- CPU는 일반적으로 USER모드에서 생성된 모든 메모리에 접근이 사용자에게 base & limite사이에 있는지 체크해야한다.
- CPU에서 GENERATE된 ADDR을 BASE REG와 비교하여 ADDR이 작으면 TRAP으로 크면 BASE+LIMITE와 비교하여 ADDR이 작으면 TREP 크면 메모리로 MAPPING하는 PROTECTION 알고리즘이다. 위의 전제에서 보듯 PROTECTION 알고리즘은 커널모드가 아닌 USER모드에서 모든 ADDR을 BASE & LIMITE REG와 비교하며 BASE와 BASE+LIMITE사이에 ADDR이 있는지 판단하여 체크한다 ( 간략한 알고리즘 구성도 이지 상세한것은 아니라고본다 )
ADDRESS BINDING

- 프로그램은 디스크에서 메모리로 가져와 실행하기 위해 인풋큐 형태로 디스크에서 메모리로 옮겨지며 특별한 API등의 지원이 없다면 Addr은 0000으로 로드되어 진고 첫 유저 프로세스는 이러한 물리적 주소를 항상 0000으로 처리해야하는 불편함이 존재했다.
- 그래서 program's life ( 실행부터 종료까지) 의 여러 step에에서 다른방식으로 주소값이 표현된다.
- 소스코드 주소는 일반적으로 Symbolic 이다.
- 컴파일된 코드 주소는 relocatable addresses에 bind 즉 묶이게된다. ( object 모듈부터 14bites 부터 시작 )
- 링커 혹은 로더는 relocated address들을 absolute address로 bin하게된다. 74014의 값 .
- 각 바인딩은 한 주소공간에서 다른 주소공간으로 매핑됨.
- 메모리 주소들에대한 데이터와 binding 명령은 위의 그림에서 보면 세가지 단계로 구분할 수 있음.
- 1. Compile time : 메모리 위치가 안다면 code 생성이 가능 하고 메모리 시작위치가 변한다면 재컴파일해야한다.
- 2. Load time 컴파일 시간동안 메모리의 위치를 알수 없다면 재배치 후 코드를 생성해야한다.
- 3. Execution time : 프로세스가 실행 중에 한 메모리 세그먼트에서 다른 메모리 세그먼트로 이동할 수 있는 경우 런타임까지 지연된 바인딩,[ base & limite reg의 address map에대한 지원이 필요]
Logical vs Physical Address Space
물리적 주소공간에 바인드된 논리 주소공간이란 개념은 메모리 관리에있어 중요하다.
Logical Address는 CPU에의해 생성되어지고 가상 주소라고 불린다. (상대적으로 코드짤때 포인터 %P하면 나오는 주소 로 생각하면 편할듯 함 )
Physical address는 메모리 유닛(장치) 에서 볼수있는 주소
loading & compile time에서 logical address 와 physical address는 address binding방식 형태가 동일하다 볼수 있다
하지만
execution time동안 logical address binding 과 physical address binding방식에는 다른 차이가 존재한다 .
차이로본다면 logical address space에는 프로그램에의해 생성된 모든 logical address들에 대한 집합이고
physical address space에는 프로그램에의해 생성된 모든 physical address들에 대한 집합이 차이이다.
처음으로 돌아가서 Address space는 메모리 관리에있어 중요한 개념이라고했으니
MMU( Memory Management Unit)에대해 알아보도록하자
Run-Time 동안 Logical Address를 Physical Address로 매핑하는 하드웨어 장치라고 생각하면된다 ( 컴퓨터구조 설계에서 더 자세하게 하드웨어적 관점으로 알아보도록 하자 다음에 ... )
- relocation register(Base Register) 의 값이 메모리로 전송될때 프로세스에 의해 생성된 모든 address 에 추가되는 방식을 생각해볼수 있다. [ Intel 80x86 기반의 MS-DOS는 4 based register이다 ]
- 사용자 프로그램은 logical address을 다루고 physical address는 볼수 없다.
- 메모리에서 위치 참조시 Execution- time binding 이 발생한다.
Dynamic Relocation using a Relocation Register & Dynamic Linking

루틴은 call되기전까지 loading하지 않으며 더 효율적인 메모리 공간 활용을 위해 사용하지 않는 루틴은 로드되지 않는 구조이다.
재배치 가능한 로드 형식으로 디스크에서 모든 루틴이 보관되어 있으며 가끔식 많은 양의 코드를 처리하기위해 필요할때 운용하게 된다.
즉 프로세스가 필요로하는 전체 메모리 공간을 메모리 전부 할당을 하는 방식이아니라 필요할때마다 일부만 로드하여 필요할때만 쓰고 해제하여 메모리를 동적으로 사용하는 방법이다 C언어로 치자면 malloc free구조로 생각하면 편하다.
Dynamic Linking
-Static linking - 바이너리 프로그램 이미지로 결합된 시스템 라이브러리 및 프로그램 코드
-Dynamic linking - 실행시간까지 연기된 linking
Stub즉 코드의 작은 부분을 사용하여 적절한 메모리 라이브러리 루틴을 찾는데 사용함.
Stub은 루틴의 주소를 자신의 주소로 교체하고 루틴을 싱행하게된다.
OS는 루틴이 프로세스의 메모리 주소에 있는지 확인하고 주소공간에 없다면 공간에 추가하게 된다 만약 동적 연결을 진행한다면 라이브러리와 헤더파일로 가지고 공유라이브러리로 관리하는게 편하다.
[ 몇몇 실무에서 진짜 많이 다루는 방법이라 생각한다 ]
Swapping
: 프로세스가 다 끝날때 까지 CPU를 사용하는게 아니라 시간단위로 쪼개어 계속 번갈아가며 CPU를 사용하는것으로
실행되던 프로세스에 대한 정보들이 모두 BACKING STROE로 저장되고 새로운/실행되던 프로세스가 메모리에 LOAD되는것. ( 프로세스가 가진 총 실제 메모리 공간은 컴퓨터의 실제 메모리공간을 초과할 수 있다 )
- 일시적으로 메모리에서 BACKING STORE로 스왑을 하고 다시 메모리에서 계속실행하기위해 가져오는것 .

Backing store - 사용자의 모든 메모리 이미지 복사본을 수용할수 있을만큼 충분히 큰 빠른디스크장치, 메모리 이미지에 직접 엑세스할수 있어야함.
Roll out/ Roll in - 우선순위에 기반한 스케쥴링 알고리즘에 사용되는 스와핑 variant , 낮은 순위 프로세스는 높은 슨위 프로세스를 로드하고나서 실행할수 있음 .
스왑에 대한 대부분의 시간은 전송시간이므로 총 전송 시간은 스왑된(교환된) 메모리의 양과 비례하는 관계를 가진다 .
** 시스템은 항시 ready queue를 즉시 실행할수 있도록 유지해야함 .
addree 바인딩 방법에따라 프로세스 스왑된 프로세스의 물리적주소는 달라짐.
할당된 메모리의 임계값보다 많은 경우 시작됨 스왑이 시작되고 메모리 요구량이 임계값 아래로 감소하면 스왑은 다시 비활성화된다.
Context Switch Time including Swapping
멀티 프로세스 환경에서 하나의 프로세스가 CPU를 사용 중인 상태에서 인터럽트 요청, 멀티태스킹, 모드전환등과 같은 요청에의해 다른 프로세스가 CPU를 사용하도록 하기 위해, 즉 다음 Priority 의 프로세스가 실행되어야 할때 , 이전의 프로세스의 상태 혹은 레지스터 값을 저장하고 새로운 프로세스의 상태또는 레지스터 값을 교체하여 CPU가 수행하도록 하는 작업
* Context Switching은 문맥교환으로 받아들이면 안된다.
Context는 사용자간, 사용자 와 시스템 및 디바이스간에 상호작용에 미치는 개체등의 현 상태를 정의하는 정보를 의미한다. 즉 CPU가 프로세스를 싱행하기 위한 프로세스의 정보를 의미하게되고 PCB에 저장되는 정보이다.
Context Switching시 CPU는 아무 일을 하지못하기때문에 스위칭이 많아지면 오버헤드가 발생하여 효율성이 떨어지게된다.
오버헤드와 처리기 구조
Context Switch 동안에는 유용한 작업을 수행할 수 없기 때문에, Context Switch 시간은 일종의 오버헤드라고 할 수 있다. CISC와 RISC는 각각 장단점이 있는데,Context Switch 측면에 보면 RISC의 경우 레지스터의 용량이 CISC보다 상대적으로 크기 때문에 좀 더 큰 오버헤드가 발생하고 해당 사항은 컴퓨터 구조및 디지털논리회로 내용과 밀접하므로 추후 설명하도록 하겠다.
인터럽트
인터럽트는 CPU가 프로그램을 실행하고 있을때 실행프로그램 밖에서 예외 상황이 발생하여 처리가 필요한 경우 CPU에게 알려 예외상황을 처리할 수 있도록 하는 것을 말하게 되는데 . Context Switching이 일어날때는
1. I/O Request , 2. Time Slice expired , fork a child , Wait for an interrupt, 등의 인터럽트 상황에서 Context Switch가 발생하게 된다 .
Priority는 OS 스케쥴러의 스케쥴링 알고리즘에 의해 정해지며 수행하게된다.
Contiguous Allocation

메인 메모리는 OS단과 유저 프로세스를 둘다 지원해주어야 한다.
Register와 같은 자원은 한정적이기 때문에 효율적으로 할당해야하므로 Contiguous Allocation 방법은 효율적인 자원할당 방법중에 하나로 고려하면 될것같다.
그렇기 때문에 메인 메모리는 보통 상주하는 운영체제 메모리와 유저프로세스용 메모리 두개의 파티션으로 나누어진다
위그림에서 Relocation register는 사용자 프로세스를 타 프로세스로부터 스왑 상황시 코드와 데이터를 보호하기위해 사용하게된다.
Base Register는 최소 물리 주소값을 포함하게되고 Limit Register는 logical address의 범위를 포함한다
즉 logical address는 limit register보다 적은 값일수 밖에 없다.
MMU는 logical address를 동적 매칭하고 커널 코드 및 크기를 변경하는 것과 같은 작업을 허용할수 있게 된다.
Multiple-partition allocation

파티션 수에 제한적인 가변 분할 다중 프로그래밍으로 각 작업이 필요한 만큼의 메모리를 차지하게 -(효율성을 위해 프로세스의 요구에 맞게 가변 파티션의 크기를 조절하여 )Internal Fragmentation을 없앨 수 있다.
. OS는 할당 파티션과 Free 파티션( Hole) 의 정보를 계속 알고 있어야하고 프로세스가 디스크에서 메모리로 도착하게되면 해당 프로세스의 사이즈를 할당할 수 있는 사이즈의 Hole이 존재시 해당 공간에 프로세스를 할당하게 된다.
. Internal Fragmentation은 없지만 External Fragmentation은 존재할 수 있다.
- Free Hole에서 Hole을 선택하는 방법은 First-fit , Best-fit , Worst-fit 세가지가 존재 한다.
- First-Fit
- 가장 큰 첫 번째 Hole에 할당
- 주소로 정렬된 Linked list구조의 Free Hole 관리.
- 작업보다 사이즈가 큰 파티션이 존재시 할당.
- 주소로 정렬된 Free space이기에 반납된 것을 합치기 쉽다.
- 찾는 시간이 오래걸린다.
- Best Fit
- 충분히 큰 Hole중 가장작은 Hole에 할당.
- 오름 차순으로 size정렬된 Linked list 구조의 Free hole을 관찰
- 할당후 남은 Hole은 Free Hole이 size정렬이므로 다시 재정렬
- Size 큰 Hole은 가능한 유지.
- 매우 작은 Hole이 많이 생길 확률이 높음 ( External Fragmentation ).
- Worst Fit
- 가장 큰 Hole에 할당.
- 내림차순으로 size정렬된 Linked list구조의 Free hole을 관리.
- 큰 size의 Free hold가 많이 없을것임.
- 성능 : First-fit = best-fit > worst-fit
- 할당은 사이즈로 정렬하고 합칠때는 주소값으로 정렬하는것이 유용함.
- First-Fit
※ Hole : 사용 가능한 메모리블록으로 다양한 사이즈의 메모리 블록이 메모리공간에 존재하게된다 [ 할당해제를 반복하면서 생긴거임 ] )
※ internal fragmentaion은 하나의 메모리 블락이 전부다 쓰이지 못 해서 그 남는 공간만큼의 비효율이 발생하는 경우를 의미한다.
Fragmentation
External Fragmentation : 전체 메모리 공간이 요청을 충족하기 위해 존재하지만 연속적이지 않음
. 필요한 사이즈로 메모리 할당시 발생
. 해결하기 위해서 떨어져 있는 것을 모을 수 있도록 압축을 사용하면 가능함. ( 메인메모리에서는 압축이 어려움 )
. 압축시 버디 알고리즘을 사용, 버디시스템은 큰버퍼를 반복적으로 이등분하여 작은버퍼를 만들어, 가능할때마다 인접한 Free buffer을 합치는 과정을 반복하는 기법.
. 압축시 주소가 Relocatable Address 이고 Execution Time Binding이어야 하며 재배치가 동적이어야함.
Internal Fragmentation : 할당에 요구되는 사이즈를 할당해도 사용되지 않는 메모리가 있을시 문제가 있는상황.
. 고정 사이즈를 할당시 발생함 .
Segmentation - 메모리 관리체계


. 프로그램은 세그먼트 집합임.
. 세그먼트는 메인 프로그램, 절차, 함수, 메소드, 객체, local , global 변수, stack, symbol table, 배열등과 같은 논리적 단위임.
.구조 :
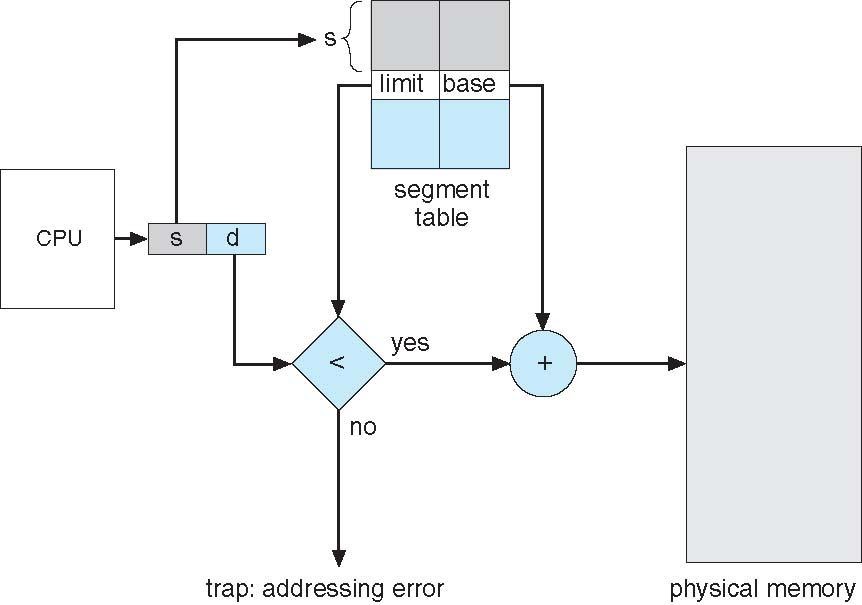
. Logical address는 2개의 튜플 <Segment_num , offset > 으로 구성됨,
Segment table 은 2차원 물리주소를 매핑하게되며 각 테이블의 항목에는 세그먼트가 메모리 첫 시작지점의 물리적 주소를 포함하는 BASE Register와 세그먼트 길이를 지정하는 LIMT가 존재한다
. STBR : Segment table base register : 메모리에서 세그먼트 테이블의 위치를 나타내는 포인터로 역할한다.
. STLR : Segment table length Register : 사용중인 프로그램의 세그럼트 수의 길이값.
즉 Segment num S < STLR 이된다 .
. Protection.
세그먼트 테이블의 각항목에서 Validation bit =0 이면 읽기/쓰기/실행권한이 잘못된 세그먼트 를 연관하게된다.
세그먼트 관련 보호비트에서 코드 공유는 세그먼트 수준에서 발생하게되며, 세그먼트의 길이가 다르기 떄문에 메모리 할당에서 문제가 된다.
Paging : Logical Addr -> Physical Addr로 변환해주는 과정 .
External Fragmentation과 다양한 메모리 Chunk사이즈를 피하기 위해 프로세스의 물리적인 주소공간은 비연속적일수 있다, 그렇기때문에 프로세스는 메모리를 사용할 때마다 메모리를 할당하게 된다.
Frames : 고정된 사이즈의 블록으로 메모리공간을 나눈 단위 사이즈는 2의 지수형태이고 512~16Mbyes 사이의 값이다.
Pages : 같은 크기의 블록으로 논리 메모리공간을 나눔.
. 1개의 프로그램을 실행시키기 위한 N개의 Page는 N개의 Frame이 필요하게된다.
PAGE TAGBLE : 논리적 주소공간을 물리적 주소공간으로 변환하기 위해 셋업이 필요하다.
/ * 페이징을 하기위해 만든다 해당 테이블은 프로세스마다 하나씩 있으며 각 페이지를 프레임으로 연결해주는 역할을 담당하고 있다 */
. 백업 저장소 역시 페이지로 분할된다.
Address Translation Scheme
1. logical * physical addr 구분
logical addr : address generated by CPU
physical addr : real address in main memory
logical memory : address space generated by CPU
physical addr : real address space in main memory
Page number (p) : 물리적 메모리에 각페이지의 Base address를 포함하는 page table에서 인덱스를 사용
Page offset (d) : base address와 결합하여 물리 메모리 주소를 정의하고 메모리 유닛으로 전송.
logical address space는 2^m이고 page size는 s^n이다.



페이징을 하기 위해 페이지 테이블이라는 것을 만든후 페이지 테이블은 프로세스마다 하나씩 있는 것으로 각각의 페이지를 각각의 프레임으로 연결시켜주는 역할을 하게된다.
. 프로세스는 논리 주소만 보기때문에 연속된 주소를 사용하는것 처럼 보일수도있다 하지만 그림에서 보는것과같이 실제 물리적 메모리는 불할되어있으며 이를 관리하기위해 프레임과 페이지가 사용된다 .

페이지 테이블 구현시

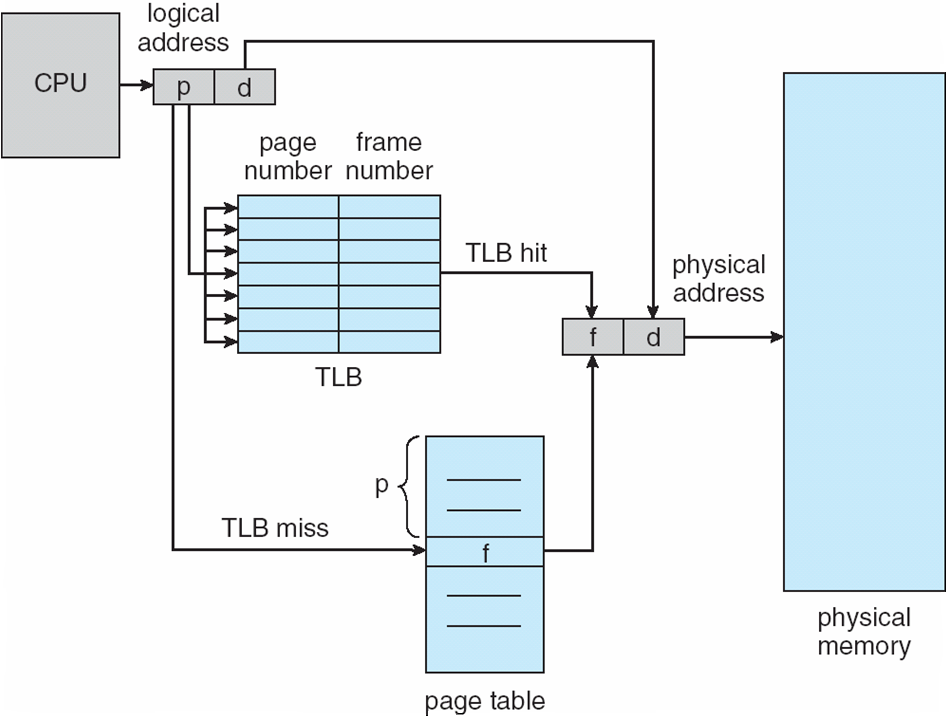

페이지 테이블은 메인메모리에서 유지되며 PTBR(Page-table base register)는 페이지 테이블 시작 주소를 가리키는 포인터 레지스터이고 PTLR(Page table Length Register)는 페이지 테이블의 크기를 지시하는 레지스터이다.
. 페이지 테이블용 과 데이터/명령어용의 두 개의 메모리 액세스가 필요하게된다.
. 두 개의 메모리 액세스 문제는 TLB(Translation Look-Aside Buffers)라고 하는 특수 고속조회 하드웨어 캐시를 사용하여 해결할 수 있다.
. TLB 캐시에는 ASIDs( Address-Space-Identifiers)식별자가 있으며, 프로세스에 속한 페이지 테이블의 식별자를 의미한다. 또한 프로세스마다 따로 사용이 되어야해서 유니크한값을 가져 프로세스를 구분하고 주소공간을 보호하기 위해 사용하게된다.
. ASIDs를 사용하지않는다면 TLB캐시 사용시 FLUSH로 매번 메모리에 접근해야하기 때문에 효율성이 떨어지게된다.
. TLB -> 64~1,024 entry.
. TLB Hit -> 캐시 내에 비교가능한 정보가 있어 매칭하여 정보가 있는 상태로 해당하는 물리적 주솟값을 바로 찾아갈 수있다.
>> 페이지 테이블을 찾아가지 않아 메모리 접근 시간이 한번 한것과 비슷하게 보일수 도 있다.
. TLB miss 는 페이지 테이블에서 값을 찾은후 TLB에 위치하여 주소를 찾아가는 방법이다.
. TLB는 램이 아닌 결합메모리로 Address line decoding이 필요하지 않다.
. TLB가 꽉찬경우 다른것으로 대체할수 있는 Replacement 정책을 잘 고려해야하며 계쏙 사용하는 주소는 묶을수있다.
Memory Protection

메모리 보호는 읽기전용 모드 또는 읽기-쓰기 모드 액세스가 허용되는지 여부를 확인하여 나타내기 위해 Protection Bit를 각 프레임과 연결하여 구현하며 또한 실행모드 등등의 페이지를 지시하기위해 Protection bit를더 추가할수도 있다.
. 페이지 테이블의 각 항목에 attached되어있는 유무효 비트중 유효는 프로세스의 논리주소공간안의 관련있는 페이지를 나타내며 무효는 프로세스의 논리주소 공간또는에 페이지가 없음나타낸다.
Shared Pages

- Shared Code
. 페이지 단위로 공유할수 있고 Read Only Page의 (1회 COPY) reentrant code가 프로세스사이에서 공유된다
. 동일한 프로세스공간에 멀티 스레드를 공유하는것과 유사하며 (Stack 제외 ) R/W 페이지가 허용되어 공유된다면 IPC에서 유용하게 사용할수 있다.
- Private code and Data
. 각 프로세스는 코드와 데이터를 각자 복사하여 유지하고
. Private code and Data 페이지는 논리 주소공간 에서 나타난다.