[MLE]Maximum likelihood estimation에 대하여
이번 포스팅에서는 Smoothing , Estimation, Probability Distribution등을 조사하며 나오는 Maximum likelihood 가 무엇인지 알아 보도록 하겠다.
Wikipedia를 살펴보면 MLE는 Statistic에서 Maximum likelihood method는 Observation data 가 주어졌을때 가정된 확률분포(Probability Distribution)의 Parameter θ를 추정하는 방법이다. 가정된 Statistic model에서 Observation data에 의존하여 가장 가능성이(Maximizing한) 있는 likelihood function을 추정하는 것이다. 즉 parameter θ의 공간에서 maximize한 Likelihood function의 지점을 구하는것이 목적이다.
Define Maximum likelihood method
다시한번 정리하면 MLE는 Parameteric한 Data 의 Density estimation방식으로 θ = (θ1,....,θm)으로 구성된 Unknown한 Probability density Function P(x|θ)에서 Observation data set X를 X= (x1, x2 , ... ,xn)이라 할때, X에서 Parameter θ를 추정하는 방식이다 .
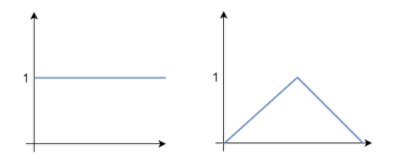
예를들면 Observation data X = { 1,1,1,1,1 }의 데이터 X를 Sensor로부터 얻었다고 가정한다면 X로부터 추정하는 Data distribution이 N개 존재한다고 하였을때 N개의 분포중 Observation Data X가 추측된 Data Distribution 의 중심과 가장 일치하는 분포를 추측하여 해당 분포의 특성을 추정할 수 있게 된다.(왼쪽 그래프가 그에 해당하는 데이터 분포로 추측하게 된다 ) 즉 왼쪽 분포의 데이터 x에 대한 likelihood가 더 높다고 표현할 수 있게 되고 likelihood는 기본적으로 아래의 식으로 표현할 수 있게 된다 .
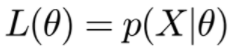
그러면 여기서 위에서 언급한 likelihood function은 무엇인가?
Likelihood - likelihood function.
observation data X의 Likelihood 에대하여 알아보면
likelihood function은 Observation data의 Joint Probability기반 Statistic Model의 Parameter fucntion으로 설명이 가능하다.
여기서 Joint Probability와 Conditional Probability를 다시한번 정리하자면
Conditional Probability
사건 B가 발생했다는 가정하에 사건 A가 일어날 확률.
Joint Probability와 달리 1번의 시행에 대한 확률.
전체 경우의 수가 있을 때, 그중 특정 조건일 때의 확률만 뽑아 내고 싶을때 사용한다.
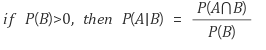
예를 들면 두개의 주사위에서 두 주사위가 둘다 같은 숫자가 나올 경우 그 숫자가 1일 확률에 대하여
1. 두 개의 주사위가 모두 1이 나올 확률 A
2. 두 개의 주사위가 같은 숫자가 나올 확률 B
즉 P(A) = 1/36, P(B)=1/6
두 주사위가 모두 1이 나오는 경우 두 주사위가 같은 숫자가 나오는것의 특수성으로 인해
P(A∩B) = P(A) 이다
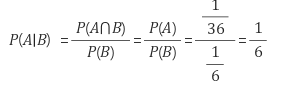
만약 Conditional Probability에서 두 사건이 Independent라면 P(A|B)=P(A)가 된다.
Joint Probability
두개의 서로다른 사건이 동시에 일어나는 확률.
P(A∩B) , P(A,B)
A와B사건이 Independent한 경우 P(A,B) = P(A)P(B)가 된다 .
A와B사건이 Dependent한 경우 P(A,B) = P(A∩B) = P(A|B)P(B) = P(B|A)P(A) 이다
여기서 사건이 N개인 경우 아래와 같이 표현할 수 있게 된다.
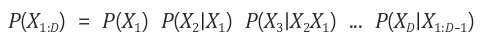
동전의 앞면을 1 뒷면을 0으로 했을때, 동전 2개를 동시에 던졌을때 나오는 경우의 수는
{1,1},{1,0},{0,0} , {0,1}이다. 즉 모든 Joint Probability 는 1/4이다.
다시 원점으로 돌아와서 likelihood function은 Observation data가 i.i.d일때 Joint Probability기반 Statistic Model이다.
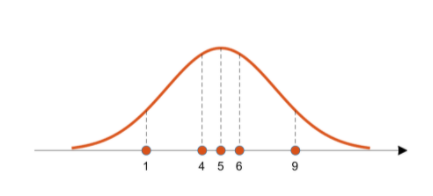
likelihood function p(x|θ)를 직관적으로 살펴보면 likelihood의 기여도는 Sensing 된 Observation data X가 존재할때 data X를 통해 아래의 주황색 분포로부터 나왔을 가능성을 이야기 할 수 있게 된다.
아래의 그래프의 N개의 분포중 가장 가능성이 높은 후보 분포중 하나인 주황색 분포에 대하여 각 X에 대하여 likelihood의 기여도를 점선에 대한 높이로 나타내고 있는 Graph이다.
전체 Observation data X인 Sample space에서 Joint Probability Density Function을 Likelihood function이라고 하며
수식으로 아래의 식과 같이 표현할 수 있게 된다.
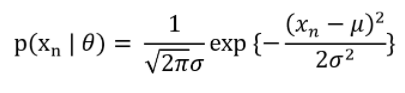
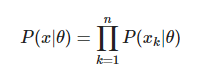
즉 Likelihood function을 기반으로 위의 Graph의 Likelihood가능도를 계산하고자 한다면 각 Data sample에서 후보 분포에 대한 높이 (Likelihood)를 계산하여 다 곱한 것이라고 볼수 있게 된다.
위의 수식중θ를 Estimation θ^으로 표현하여 보는것이 더 직관적으로 확인할 수 있을 것이다.
( 곱하는 이유는 데이터의 추출이 iid하며 Continuous하기 때문이다.)
Log likelihood
위의 Likelihood function 계산식을 구하였지만 Data X가 θ의 Parameter를 가지는 Distribution을 따르기위해 likelihood 가 최대가 되는 distribution을 찾아야 하며 최댓값을 이용할때 주로 미분을 사용한다.
하지만 위의 식은 곱셈으로 이루어져있기 때문에 연산상 미분을 적용하기가 쉽지않다. 그렇기 때문에 곱을 합으로 변환해주는 Log를 취하여 그값이 최소가 되는 값을 구하여 Maximum likelihood를 만드는 값을 구하게 되며 Log likelihood라고 한다 .
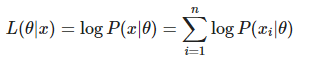
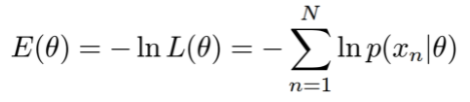
Maximum Likelihood - Likeli hood method의 최대값 구하기 .
본론으로 돌아와 결국에는 MLE는 likelihood 의 최대값을 구하는것이 목적이다 .
위에서 언급 하였지만 parameter θ의 공간에서 maximize한 Likelihood function의 지점을 구하는것이 목적인 샘이다.
log-likelihood 를 설명하며 미분을 이야기하였다. 보통 함수의 최대값을 추적하는 가장 일반적인 방법으로 미분을 하여 미분계수를 찾는 방법이 가장 일반적이다.
즉 아래의 식과 같이 찾고자하는 Parameter θ에 대하여 편미분을 하여 그 편미분계수의 값이 0인 θ를 찾아 likelihood function의 최대값을 가지는 θ를 찾는것이 목적이다 .
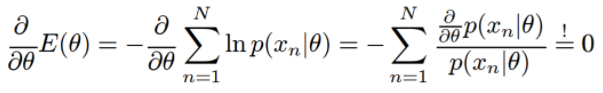
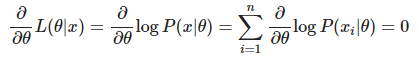
MLE의 Mean, Variance구하기
Mean μ와 Variance σ^2를 모르는 정규분포에서 표본 x1,x2,⋯,xn을 추출했을 때, 이들 값을 이용해서 Population의 Mean과 Variance를 추정해보고자 한다.
1. Mean μ 의 추정값 식은 아래와 같다.
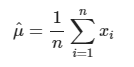
2. Variance σ 의 추정값 식은 아래와 같이 나타난다
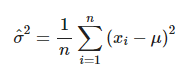
mle의 Mean과 Variance의 계산과정을 보기전에 우선 정규분포를 예를들어 보면 분포가 θ=( μ, σ)의 정규분포라면 P( ) 값은 아래와 같이 정규 분포의 pdf를 따르게 될것이다.
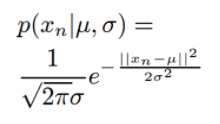
이 θ=( μ, σ)의 정규분포를 식에 대입하게 된다면 아래의 식과 같아진다 .
각 표본들은 정규분포에서 추출됐고 X는 iid라고 가정하면
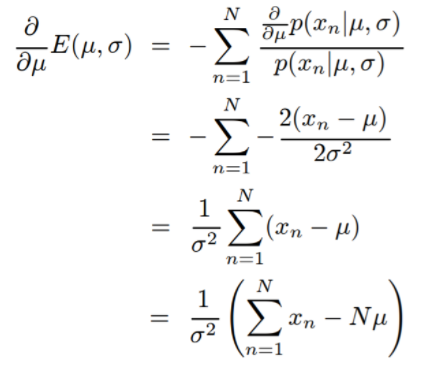
이제 위의 편미분E()에 대한 값을 0으로 만드는 θ=( μ, σ)를 찾아야 한다
1. 여기서 maximum likelihood를 만들어주는 Mean estimation value는 이 되고.
L(θ|x)를 Variance σ로 편미분하면 아래와 같이되고
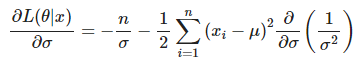
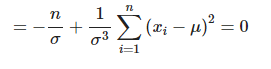
Maximum likelihood를 만들어주는 Variance는 아래와 같이 되는것을 볼 수 있다.
Likelihood를 최대화하는 Parameter를 MLE라고 하며 위으 Mean과 Variance의 Parameter가 정규분포의 MLE와 같다는것을 확인하였다 .
MLE property1 -Asymptotically optimal
다른 estimator와 비교했을 때 MLE는 가장 작은 variance를 가진다.
평균의 MLE는 sample mean인데, sample mean의 variance가 sample median의 variance보다 더 작다.
- overfitting 가능성이 존재하는 한계가 존재한다 .
MLE property2. -Asymptotically normal distribution
MLE는 n이 무한대로 갈 때, 아래와 같이 normal distribution을 따른다.
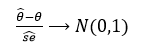
이때 θ^은 parameter θ에대해 예측한 MLE이다.
SE^은 MLE의 표준 에러를 나타낸다.
Score function은 위에서 MLE를 구할 때 log-likelihood function을 θ로 미분했을 때 나온 식이다.
Fisher information은 variance of score functions로 log-likelihood function을 θ로 두 번 미분한 식의 평균에 마이너스(정보가 음수가 되지 않도록)를 붙여주면 된다.
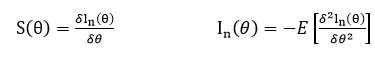
Fisher information은 log-ikelihood function의 뾰족한 정도를 나타낸다.
Function이 더 뾰족할수록 estimation이 잘 되었다고 할 수 있기 때문에 Fisher information이 클수록 estimator가 좋다고 할 수 있다. 또한 Fisher information을 통해 MLE의 variance를 estimate할 수 있다.
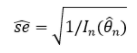
즉, Fisher information을 통해 MLE의 standard error를 구하면, 이를 통해 MLE의 분포를 알 수 있고, 신뢰구간 등을 만들어 볼 수 있다
MLE property3. -Equivalent
Equivalent라는 성질은 다음과 같은 뜻이다.
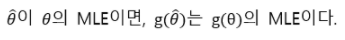
또 이와 관련된 개념으로 delta method가 존재하는데, 이는 theta의 분포가 아닌 theta를 포함한 함수의 분포를 구할 때 사용할 수 있다.
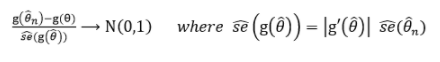
그 외에도 MLE는 unbiased esimator가 아니지만 consistent하다는 특징이 있다.
※참고 Score function과 Fisher function
1. Score function
Log-likelihood function의 1차 미분 값을 Score function이라고 부르게 된다 .
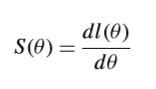
여기서 미분은 θ , 타겟의 Parameter를 기준으로 미분하게 된다.
MLE의 계산은 전형적으로 score 방정식 즉, S(θ) = 0이라는 log likelihood function의 1차 미분 값이 0이라는 방정식을 계산함으로써 구하게 된다.
2. fisher function
피셔정보에 대하여 알아보면 피셔 정보는 log likelihood function의 2차 미분을 한것이다 .curvature라고도 부른다 .

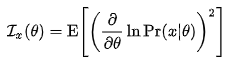
위와 같이 나타난 I(θ)가 피셔 정보이고, 이것은 log likelihood fucntion을 두 번 미분하고 거기에 마이너스를 붙인 것이다.
그리고 관찰된 피셔 정보(Observed Fisher Information)은 다른 것이 아니라, MLE 값을 피셔 정보에 넣으면 된다. 즉, I(θ ML)로써, 하나의 값이 되는 것이다.
피셔 정보를 θ의 함수로 구했다면, Maximum likelihood function을 통하여 θ 값을 구한 뒤에 그 값을 피셔 정보에 넣어 주면 관찰된 피셔 정보 값이 구해지는 것이다.
성질로
독립 확률변수에 대하여 Addtive하다. 즉 동일한 분포를 가진 두 독립 확률변수 X,Y가 측정시 다음이 성립하게 된다 .
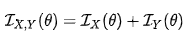
MLE는 무선통신 신호처리와 머신러닝에서 쓰는 기법이며 MLE의 Variance는 실제보다 작게 추정되어 표본헤 대하여 Overfitting이 될 가능성이 존재하는 한계가 존재한다.