[Paper - Review& Summary ]Density Forecasting for Long-Term Peak Electricity Demand
논문 리뷰 및 정리 그리고 구현을 시작하기에 앞서...
스마트 그리드 시스템( 하드웨어적 해결법과 소프트웨어적 해결법이 공존하지만 그중 전력량 예측 기법을 이야기하자면)은 에너지 관점에서 본다면 통신인프라 및 전력데이터 수집 통신 인프라를 통해 수집된 빅데이터와 계절성, 인적데이터의 상관관계를 토대로 상용화 할 수 있는 효율적인 에너지 예측 모델이 도출 된다면 산업적, 경제적으로 큰 가치를 가지는 미래 기술이라 생각한다. 또한 스마트 그리드 내의 장기간 시간구간동안의 에너지 수요예측기술은 새로운 인프라 ( 전력과 통신 그리고 기반시설)에 있어 매우 필요한 알고리즘문제라고 생각한다.
왜냐하면 만약 장기간의 에너지 예측결과가 실제 수요보다 크게 평가 된다면 에너지 과생산 문제로 인하여 투비 및 생산과정에 있어 자본손실이 발생하고 반대의 에너지 생산 부족으로 인해 블랙아웃 등의 사태가 벌어져 산업시설에서 생산과 셋업 등에 있어 손실이 발생하게 될것이다.
그렇기때문에 논문을 읽으며 인공지능, 하드웨어적 모듈 , 신호처리, 소프트웨어를 접목시킨 스마트 그리드 시스템에 있어 그중 전력데이터의 관점에서 데이터를 해석하기 위해 우선 논문을 정리하고 요약해보고 내가 가진 전력데이터를 기반으로 딥러닝과 데이터 중심으로 예측 논문을 구현해보고자 한다.
paper reference -Density Forecasting for Long-Term Peak Electricity Demand
Rob J. Hyndman and Shu Fan, Member, IEEE. 2010
abstract
. Density Forecast are more than point Forecast, and are necessary for utilities to evaluate and hedge the financial risk accrued by demand variability and forecasting uncertainty.
. This paper proposes a new methodology to forecast the density of long-term peak electricity demand
. Peak electricity demand in a given season is subject to a range of uncertainties, including underlying population growth, changing technology, economic conditions, prevailing weather conditions (and the timing of those conditions), as well as the general randomness inherent in individual usage.
. additionally , it's also subject to some known calendar effects due to the time of day, day of week, time of year, and public holidays.
. semi parametric additive models are used to estimate the relationships between demand and the driver variables.
.demand distributions are forecasted by using a mixture of temperature simulation, assumed future economic scenarios.
-Abstract와 introduce를 보자면 저자는 Density Forecast 는 Cunsumer(가정 혹은 사업자 )의 전력사용량 즉 사용자의 사용량을 토대로 추론한 미래 생산량(즉 수요량)을 추정한 전체 기간동안의 확률분포로 정의하였고 이 Density Forecast는 Point Forecat보다 전력을 생산함에 있어 전력 수요의 변동성( 예를들면 오일쇼크, 생산과 공급의 불균형, 계절성 영향, 코로나, 특정 계절, 인구 증감소, 기술적 변화, 경제 조건, 기상조건, 그리고 이런 조건의 타이밍, 개별적 사용량, 시간, 요일 , 주기적 시간 , 공휴일등 에 의한)과 불확실한 사회적 사건과 관계속에서 발생하는 예측의 불확실성으로 인해 발생하는 위험들 즉 당해 계획한 생산보다 소비가 적은경우 혹은 그반대의 경우 에너지 생산과 저장의 관점에서 발생하는 재정적 위험을 지표를 통해 평가하고 즉각 대응 하는것이 필요하다 라고 말하고 있다.
장기간의 Density of Peak electricity demand의 데이터 예측의 해석을 1. semi-parametric additive Model과 전력 수요 데이터 와 전력 수요에 영향을 끼지는 데이터( 온도, 날짜, 인적, 경제데이터)의 관계를 통하여 예측을 진행하였고 이후 미래의 온도(가변 블록을 사용하는 방법에기반한 ) 및 경제시나리오에 기반한 시뮬레이션을 합성하여 수요 분포를 예측하도록 진행 및 성능 평가를 진행했다.
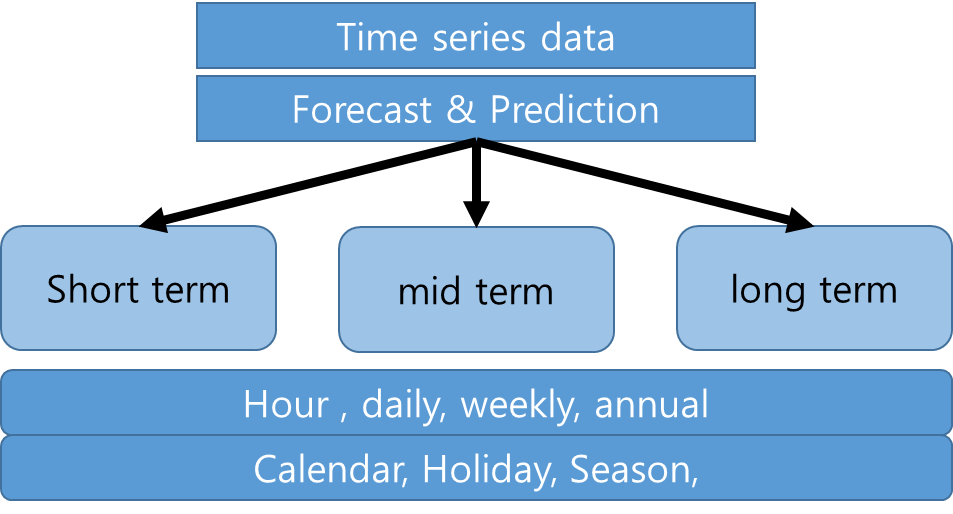
1. 전력데이터는 시계열 데이터에 기반한 데이터이기 때문에 데이터를 예측시 사용자의 특성에 기반하여 데이터가 피크값을 찍을때와 전체적인 전력수요량은 hour, daily, weekly, annual간 데이터의 trand에 영향을 받으며 주기성을 가질 수 있다.
그렇기 때문에 시간의 관점에서 시계열 예측작업은 1. 단기 , 2. 중기, 3.장기 예측으로 분류하여 예측 및 평가를 진행해보아야한다.
예를들어 사람이 가장 활발하게 활동하는 9시~ 6시 [평균 직장인 근무시간 ] 부터 00시 이후 9시까지 취침시간 간의 전력데이터의 사용 분포와 봄 여름 가을 겨울간의 사용분포 여름의 장마철기간등을 포함, 등이 이에 해당하며 또 다른 시계열 데이터의 예를들면 이통사의 서버관점에서 단말 사용자의 트래픽 양을 탐지할때 출근전 대중교통 이용시간대, 점심시간대, 퇴근이후 시간대 혹은 특정 이벤트로 셀에 몰리는 트래픽이슈에 대해 시간적 공간적 분석역시 상관관계를 가지고 있다 고 할 수 있다.
Long Term Demand Forecast 과 Short Term Demand Forecast
단기 예측과 장기예측중 단기예측이 활발하게 이루어진 배경을 살펴보자면 환경변수의 영향이 크다고 할 수 있다.
단기예측의 경우 짧은 구간에 따른 계절 데이터를 획득하기 용이하며 두 데이터의 관계를 통하여 짧은 구간( 약1주 정도의 기간)에대한 소비 데이터와 계절데이터의 관계를 통하여 예측 성능 평가를 결정할 수 있지만 장기 예측의 관점에서는 장기간에 대한 계절의 예측의 실제 변동적인 온도 데이터의 불확실성에 따라 장기간의 예측이 어렵다는 결과가 따라와 예측의 어려움이 따라왔다.
뿐만아니라 장단기 수요예측과 관련하여 가장큰 차이점은 예측방법 역시 다르다.
단기 수요예측의 경우 Point Forecast통하여 예측을 진행하며 장기 예측의 경우 Density Forecast를 통한 예측을 소개한다.
Point Forecast를 사용하는 단기 예측의 경우 전력수요 데이터에 대하여 짧은구간의 평균 혹은 미래 분산값의 중간값을 산출하여 예측하지만 본 연구에서 소개하는 Density Forecast의 장기수요예측의 경우 전체 수요한 미래데이터 값에 대해 전체적인 분포를 예측하여 진행된다.
뿐만아니라 데이터의 관점에서 특정 계절성 피크 전력의 수요 데이터는 인구 증감, 기술의 변화, 경제 성장의 변동성, 기상 조건( 여름 겨울등의 조건), 과 각 개인의 전기 사용시간(전력 인프라를 이용하는 모든 사람의 시간대별 )에 내재된 임의성을 포함한 불확실성에 기반한 데이터에 영향을 많이 받는다 실제로 전기는 지금 이시간에도 어디서나 사용하고 있으니 말이다.
이러한 불확실성에 기반하여 전력의 Density Forecast를 진행하기 위해 수요와 driver variable( 운용시 나타나는 여러 변수들)간의 상관관계등을 semi-parametic additive models을 사용하여 예측을 진행하게 된다.
특히 운용시 나타나는 변수 중 온도 시뮬레이션와 , 미래의 경제 시나리오는 bootstrapping을 혼합하여 수요를 예측하게 되며
온도 시뮬레이션은 가변 블록을 사용하여 새로운 계절 계절 bootstrapping 방법을 통하여 구현되게 된다.
| Short term Forsast | Long term Forecast | |
| Back Ground | . Power system control . Unit Commitment . Economic dispatch & electricticy market |
No received much attention |
| Different two forecast | . interested in Point Forecast *point Forecast ; Forecast of the mean or Median of the future Demand Distribution. |
. Density forecast *Density forecast; Providing estimates of the full probability distributions of the possible future values of the Demand . why Long Term Forecast Not used Point Forecast ? >> the point Forecast are of limited interest as they can't be used to evaluate and hedge the financial risk accyrued by demand variability and forecasting uncertainty. |
| . Another difference between short term and long terrm demand forecasting is in their use of meteorological information. * meteorolgical variables are the key inputs for most demand models. |
||
| can be obtained from weather services infor | unavailable in long term forecast so a feaible method to generate realistic futuretem- peratures is required. |
|
Short and Long term Forecast Classification
1. statistial model including linear regression and time series methods.
2. artificial intelligent approaches including artificial neural networks and fuzzy logic methods
3. machine learning , data mining techiques and grey models.
논문에서 사용한 데이터 설명과 분석.
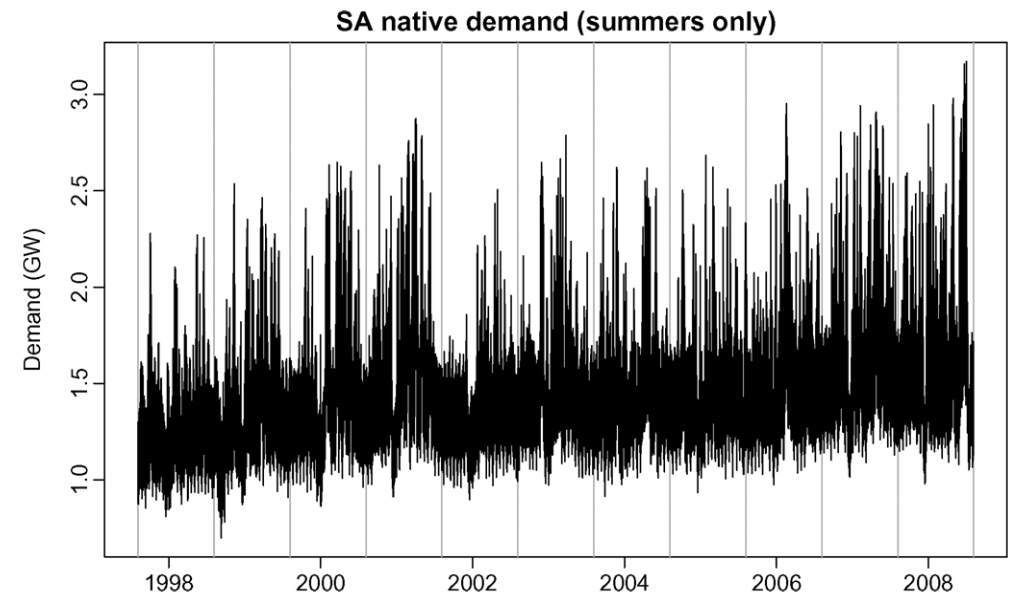
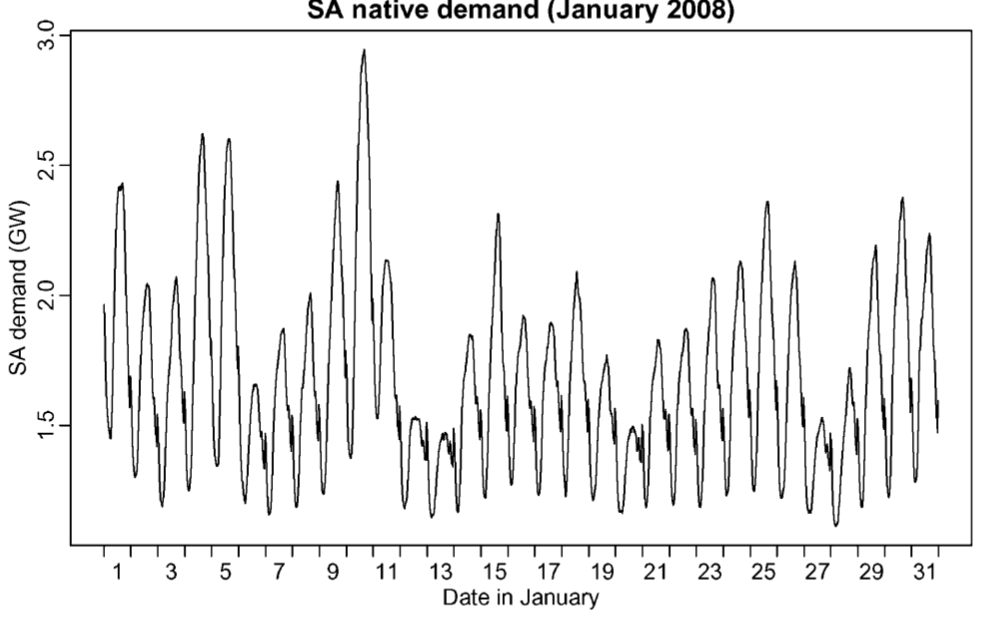
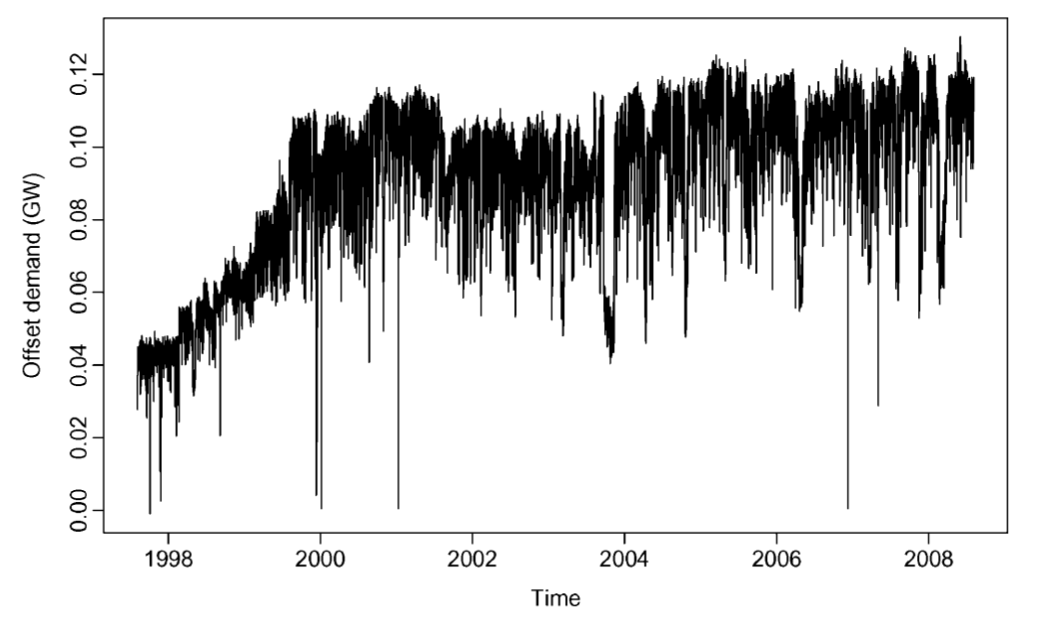
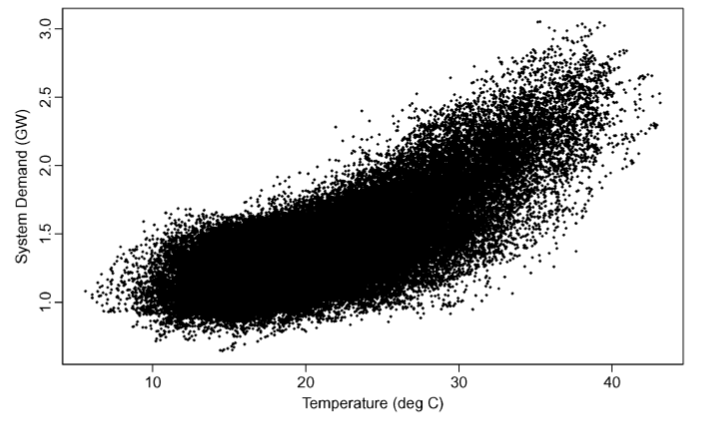
해당 논문에서 제시한 예측 데이터는 남호주의 " 전력 수요에 대한 " 데이터이고 남호주 지역에 공급에 따른 운용 비운용 발전기에 모두 해당하는 전력 수요량이다.
데이터 샘플링 주기는 30분으로 하루당 48개의 데이터를 샘플링한 데이터이다.
지역적 조건을 고려하였을때 남호주는 사막지역으로 구성되어있으며 핵심 지역은 애들레이드와 인근지역에 약 160만명의 인구가 집중되어있는 것을 고려해야한다.
데이터의 출처는 AEMO ( Australian Energy Market Operator)에서 확인할 수 있다.
* Long term damand Forecast의 경우 수요의 증가 원인으로 , 인구통계 및 경제성장률에 따라 큰 상관관계를 가지고 있다는 전제하에
경제데이터와 인구데이터는 1. 추정 거주인원 , 2. 가구당 인원, 3. 세대수 , 4. CPI, 5. 1인당 소득, 6. GSP 볼륨 추정값, 7. 전기 가격 , 8. 에어컨 지수를 추정하여 분석하였다고 한다.
제안 방법
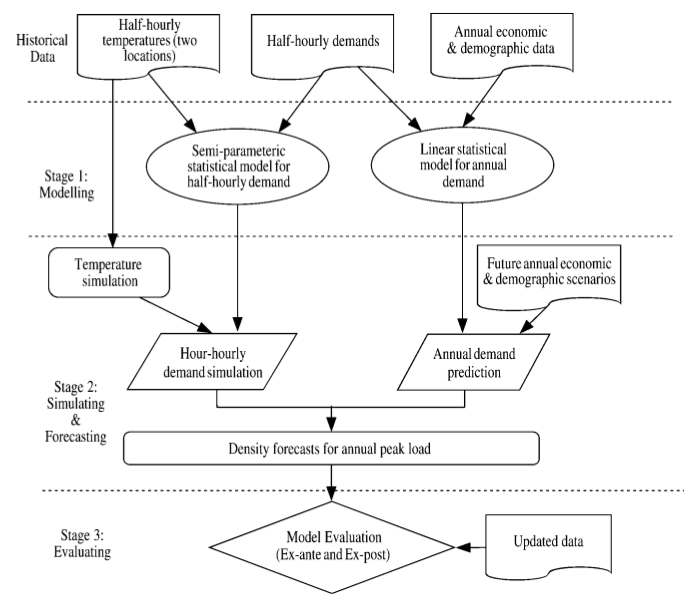
위에서 제안한 모델링 방법은 두지역의 반나절 온도데이터 , 전력 수요데이터, 연간 경제 및 인구데이터를 기반으로 1. 모델링 2. 시뮬레이션 및 예측 , 3. 평가의 3번의 절차를 거치는 방법을 소개한다.
Stage 1:
전력 수요데이터와 온도, 휴일, 인구통계적 그리고 경제성장률과 같은 운용시 나타나는 여러 변수들간의 상관관계는 Semi-parametric additive models를 사용하여 모델링하 였고 annual effect의 annual model은 AIC(Akaike's Information Criterion)을 이용하여 선정하고 halff Hourly model은 표본외 예측오차를 최소화하는 방법을 선정하여 진행한다.
즉 Stage 1에서는 경제 및 인구데이터기반의 annual effect와 온도 및 휴일과같은 변수데이터는 half-hourly effect로 나누어 예측을 진행한다.
Stage 2:
예측 분포 ( forecast Distribution )은 온도 및 Hour-hourly demand simulation과 미래의 인구통계 및 경제 시나리오에 기반하여 모델링을 혼합하여 획득하게 된다.
특히 new Seasonal Bootstrapping method는 가변 블록은 재샘플링 잔여 데이터와 온도데이터를 이용한 bootstrapping method가 적용된다 .
temperature bootstrap은 남호주 지역의 기상데이터를 serial correlation의 캡쳐하도록 설계되었다.
Stage 3:
두 예측된 데이터를 기반으로 남호주 여름의 실제 전력 수요를 비교를 진행하게 되며 사전예측과 사후예측의 차이를 통하여 모델의 효율성을 측정하게 된다.
Stage 1:
Semi-Parametric additive Model
semi-parametric additive model은 regression framework에 속하지만 nonlinear relationship & serially correlated errors가 존재한다.
semi-parametric additive model은
1. Temperature effect 는 regression splines를 사용하여 모델링이 되었고
2. 온도데이터는 같은 시간 및 기간의 온도를 주기로 고려하게 되었고
3. 경제와 인구통계 변수는 linearly하게 모델링하였다.
4. 마지막으로 error part는 serially correlated된다.
즉 시계열 데이터는 30분 샘플링된 기간동안 별도로 모델링을 해야한다 . 왜냐하면 실시간으로 수요요구추정치 및 패턴은 끊임없이 변하기 때문에 각 시간구간당 개별적으로 모델링을 하게 된다.
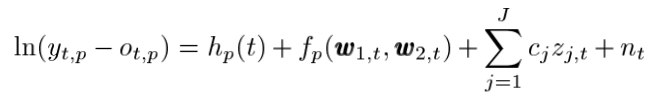
위 수식을 보자면
1. t는 time을 나타낸다.
2. p는 period를 나타낸다.
3. Yt,p는 half-hour구간에서 측정된 period p동안 time t에서의 전력 수요량 이다.
4. Ot,p는 period p동안 time t에서 측정된 산업에서의 전력 수요량이다.
단 여기서 왼쪽파트의 수식을 보자면 전체 전력수요량에서 산업에서 전력수요량을 뺀 일반적인 수요량을 나타나게된다.
즉 주요 산업의 부하를 빼서 별도로 모델링을 하기위해 제거해주었다고 해석하면 된다.
오른쪽 파트로 넘어와서
5. Hp(t)는 calendar effect (work , nonwork)에대한 영향을 모델링한 모델이다.
6. fp(w1,t , w2,t) 모델은 모든 temperature effects이다 .
w1,t 와 w2,t는 남호주의 주요 두 도시의 최근 온도 벡터 데이터이다. 즉 w1,t & w2,t 벡터를 활용하여 온도 영향 모델을 모델링한 결과값으로 보자
7. ∑Cj Zj,t 는 시간 t 의 인구수 또는 경제적 변수이다. ( 수요에 대한 영향은 coefficient cj에 영향을 받으며 period에는 독립적이다 ).
8. 마지막으로 nt는 시간 t에서의 에러 모델이다.
1. Calendar Effect hp(t)
Calendar Effect인 Hp(t) 는 연간, 주간, 그리고 일일 계절 패턴에 대한 모델링이다.
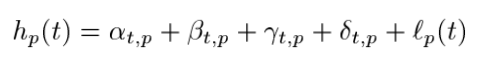
Calendar Effect 수식을 살펴보면
1. 알파 t,p는 매주 각 요일마다 다른값을 사용하게된다 이를 day of the week effect라고 한다.
2. 베타t,p는 휴일이는 0을 , 휴일 전과 다음날은 0이아닌 다른값을 취하게되는 변수로 holiday effect라고 한다.
3. 마지막으로 ℓp(t) 함수는 smooth function으로 매해 반복적으로 사용하게된다 ( time of summer effect 에 의해 사용한다 )
여기서 ℓp(t) smooth function은 주로 cubic regression spline (3차 회귀 )을 사용하여 추론하게 된다.
2. Temperature Effect Fp(W1,t , W2,t )
temperature Effect는 최근 온도가 총 전력수요에 미치는 영향을 모델랑한 모델이다.
Temperature Effect fp(w1,t w2,t)의 input variable w1,t & w2,t는 남호주의 두 도시의 위치에 따른 온도 벡터 데이터 변수이다.
두 온도 벡터 데이터의 경우 상관관계가 높기때문에 직접 모델링하기에 어려움이 많아 상관관계가 적은 온도의 평균 xt 그리고 온도차 dt로 변형하여 모델링에서 사용하게된다.
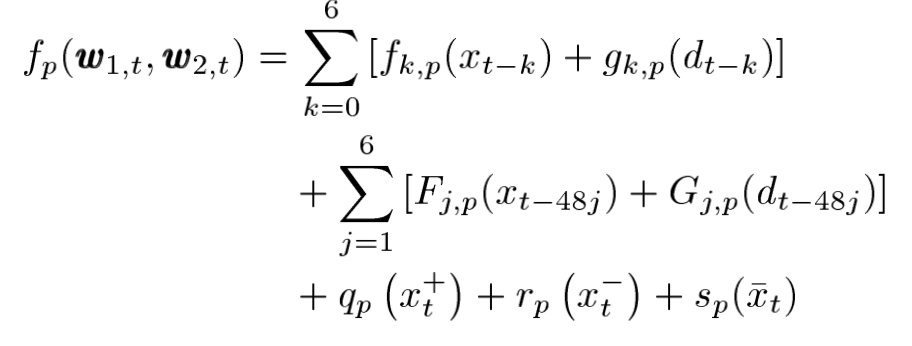
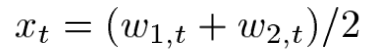
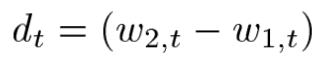
temperature effect의 수식을 보면 variable part에서
1. xt+ 는 24시간 동안 온도 평균의 최대값,
2. xt- 는 24시간 동안 온도 평균의 최솟값
3. xt bar 7일(일주일)간 온도의 평균으로 정의하였다.
이제 temperature effect의 각 함수부분 f,g,F,G,q,r,s를 살펴보자
1. 각 함수는 smooth 되었고 3차 regression spline 으로 추론되었다고 가정한다.
2. f,F,q함수는 22~29에 spline한다.
3. r 함수는 13.8~16.9에 spline 한다.
4. s 함수는 18.2~22.2에 spline 한다
5. g,G함수는 -2.2 ~-0.7도에 spline을 적용한다.
3차 regression spline을 진행시 각 온도 구간마다 A-B온도의 구간과 C-D 온도 구간등 각 구간의 regression spline을 선택하여 진행하게 되었고 그중 가장 성능이 좋은 온도적 구간 위치를 모델로 선택하게된다.
3. Demographic and Economic Effects ∑Cj Zj,t
Demographic & Economic Effect는 demand coefficient Cj와 Zj,t의 합으로 이루어진다.
각 변수는 demand coefficient C와 linear한 관계를 가지게 된다.
왜냐하면 경제적 관계를 따져본다면 상관관계가 상대적으로 다른 effect에비해 변동성이 작게 작용하여 상관관계에 영향이 작으며 변동성또한 샘플링 구간에 대해서 천천히 변하기 때문이다. 그렇기 때문에 linear term으로 추정하게 된다 (일종의 approximation )
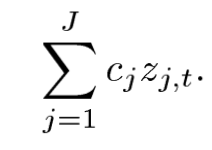
4. Error Term Nt
real world에서 해당 모델에서 모델링되지 않은 특정 이슈들 및 환경적 조건에 대한 오류를 반영하여 serially하게 반영하게된 수식이다.
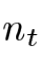
변수 선택 과정
어떠한 모델링이나 마찬가지라고 생각한다. 정확한 예측을 진행하기위해서는 문제를 해결하기 위한 원인과 관련된 최적의 input variable 조합을 찾는게 핵심이다. 단지 최적화된 모델 혹은 가장 성능이좋은 수식을 이용하면 매번 정확하고 옳은 예측을 하는게 아니란 이야기다.
본 논문에서 제안한 모델은 linear term model과 semi-parametric model로 나누어진다.
여기서 linear term 모델은 연간 경제 및 인구 통계적 변수를 기반하는 모델이고 나머지 semi-parametric model은 30분 (half-hourly interval)간격의 샘플링된 모델로 나뉘어진다.
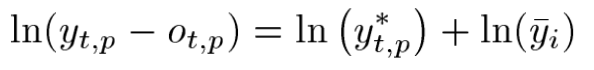
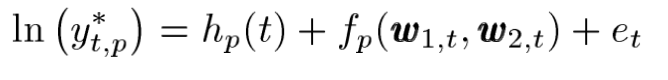
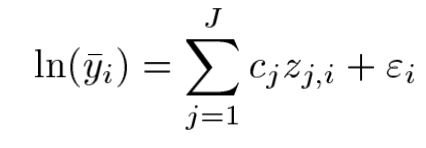
1.위 첫수식을 살펴보면
Yi bar는 time period P 에 대한 median non-mining 수요이다.
Y*t,p는 time t 와 period p에 대한 stardardized 된 non-mining demand이다.
위 수식에서 et와 ei를 합한값이 에러 구간 nt가된다.
제안한 모델에서 사용한 변수중
1. Temperature & calendar Variables 는
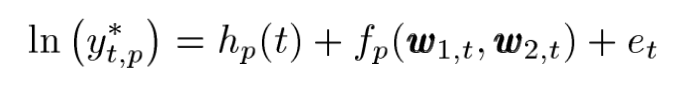
각 모델에서 사용한 temperature & calendar variable은 cross-validation( data 를 training set & validation set으로 분리하여 input variable은 validation set의 누적 예측 오차를 최소화 하여 선택) 을 통하여 선택했고 평가방법으로는 MSE(Mean Squared Error)을 기준으로 평가하게 된다.
모델의 목적은 peak 시간대에 대한 최대 부하 예측이기때문에 최대 부하 시간구간만 MSE 계산을 진행하게 된다.
2. half-hourly demand model input variable 을 선택하기 위해서 . 모든 temperature & calendar variable을 포함한 모든 구간에 대해 전체 데이터구간을 포괄하는 전체 모델로 관점을 바꾸어
실험시 1. 전체 포괄 모델에서 각 변수의 예측 값은 모든 수식은 유지하지만 각 수식의 term을 삭제 하며 독립적으로 테스트를 진행한다.
MSE 감소로 이어지는 변수는 이후 테스트시 모델에서 제외하여 step-wise variable 선택 절차진행시 out of sample predictive accuracy에 기반하여 실험 을 진행한다.
선택된 변수는 아래와같고 best model이 도출되면 전체 데이터를 이용하여 다시 모델을 최적화 진행하게된다. ..(노가다...)
2. Demographic and Economic Variables:
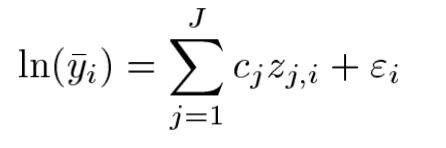
해당 모델을 인구통계 및 경제 변수 모델에 고려되었다. 뿐만아니라 해당 모델은 수요가격의 시차효과로인해 (주식 시간당 차이 혹은 에너지시장은 선물시장에 기반하여 사회 영향에따라 가격 변동이 일어난다). 시차의 평균가격과 여름이라는 기후조건에 에어컨지수(냉방지수)[최대사용량에 가장 큰 영향을 주는 요인) 을 고려cooling degree day 일수를 포함하게 된다.
cooling degree는 평균기온과 18.5도 의 차이로 정의 한다.
만약 cooling degree < 0 이라면 cooling degree = 0 이다.
여름기간동안 cooling degree - day 를 추정하기 위해 매 여름구간마다 합하게 된다.
하지만 해당 모델에서는 데이터의 량이 적기때문에 out-of-sample test를 진행하여 변수 선택을 검증하는것은 제외하게된다
(만약 데이터가 많다면 진행할 것이다...) 그렇기때문에 데이터구해서 해볼것이다...
그렇기 때문에 본논문에서는 AIC기준을
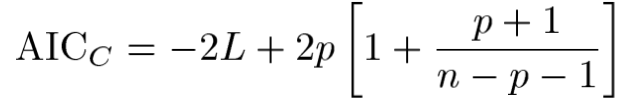
과 같이 수정하게 되었고 수식을 보면
L은 log-likelihood 모델이다.
p는 모델 파라미터의 수이다.
n은 model fitting 시 사용되는 관측치의 수이다.
따라서 AIC값이 낮을수록 더 좋은 모델이고 penalized likelihood method 라고 말할 수 있다.
Model fitting
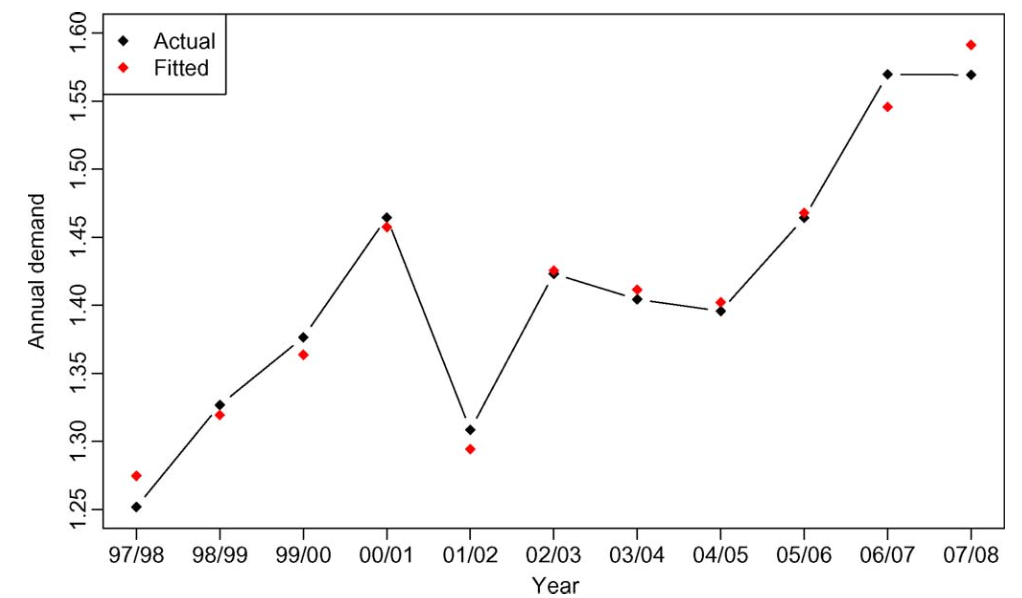
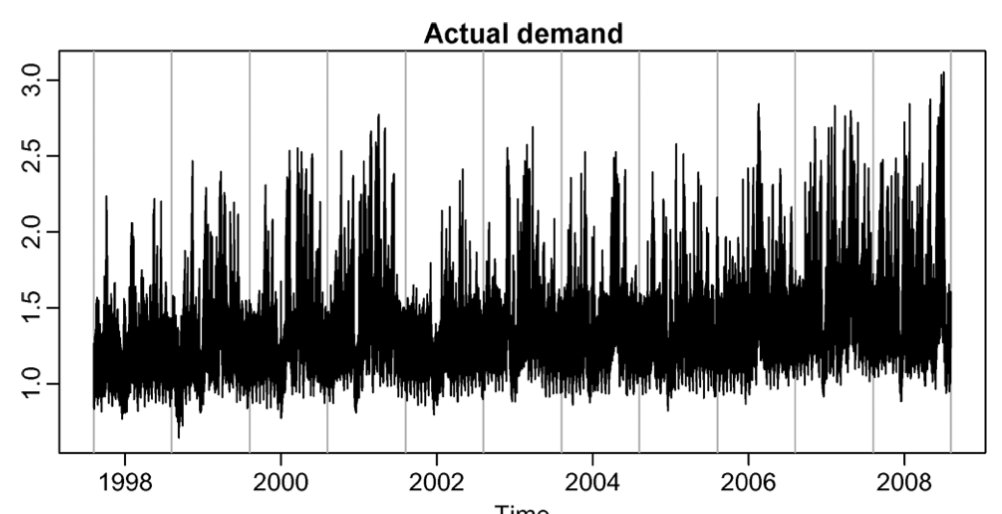
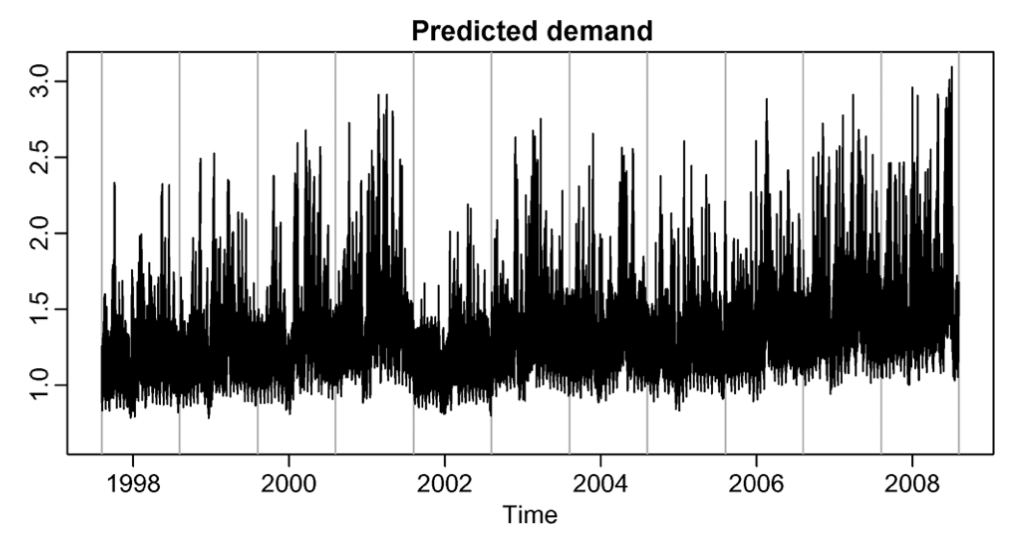
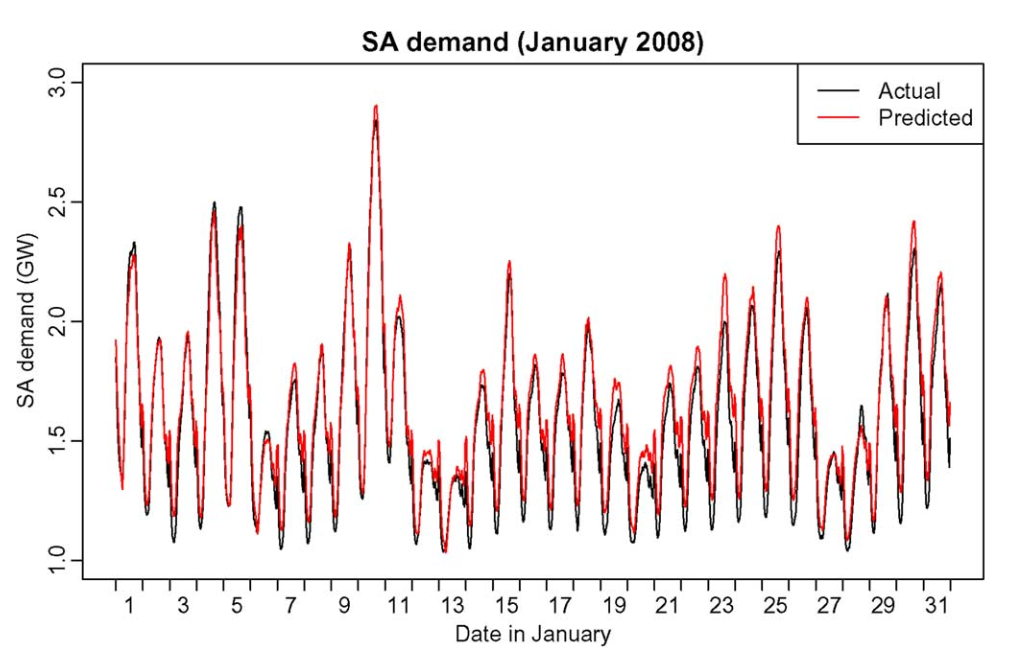
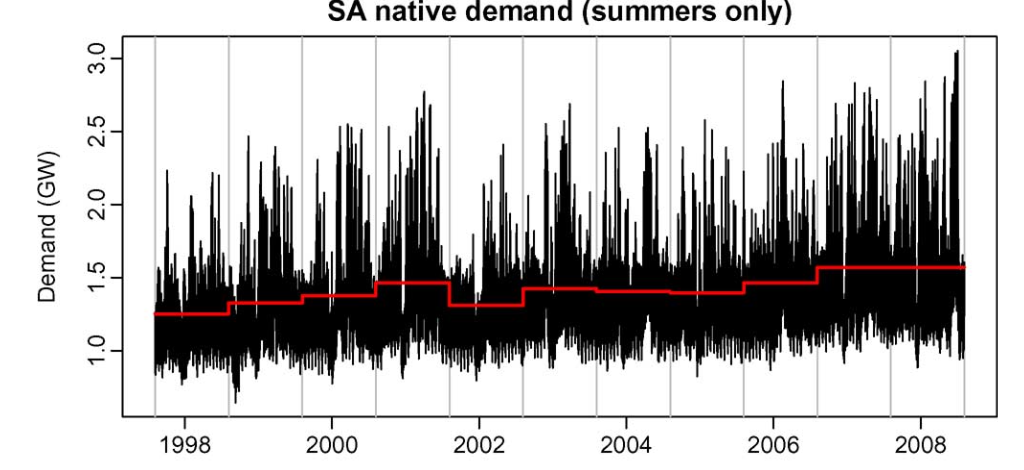
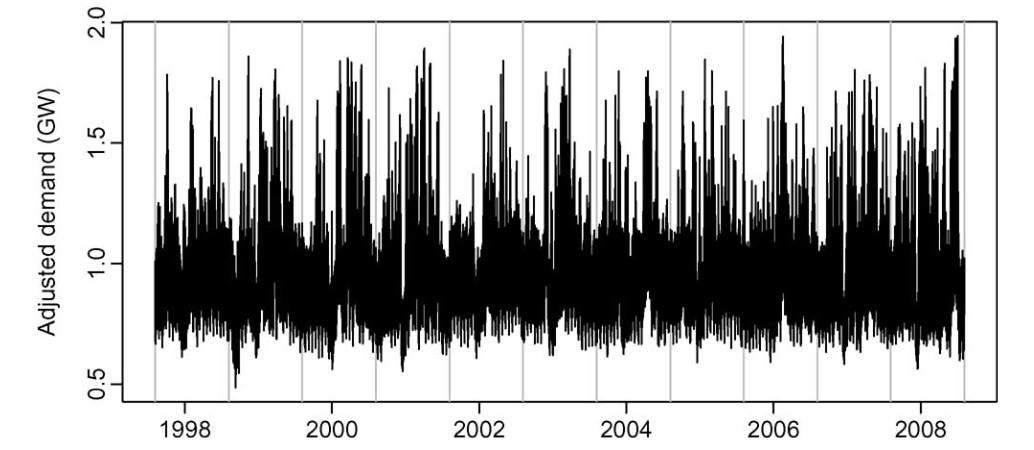
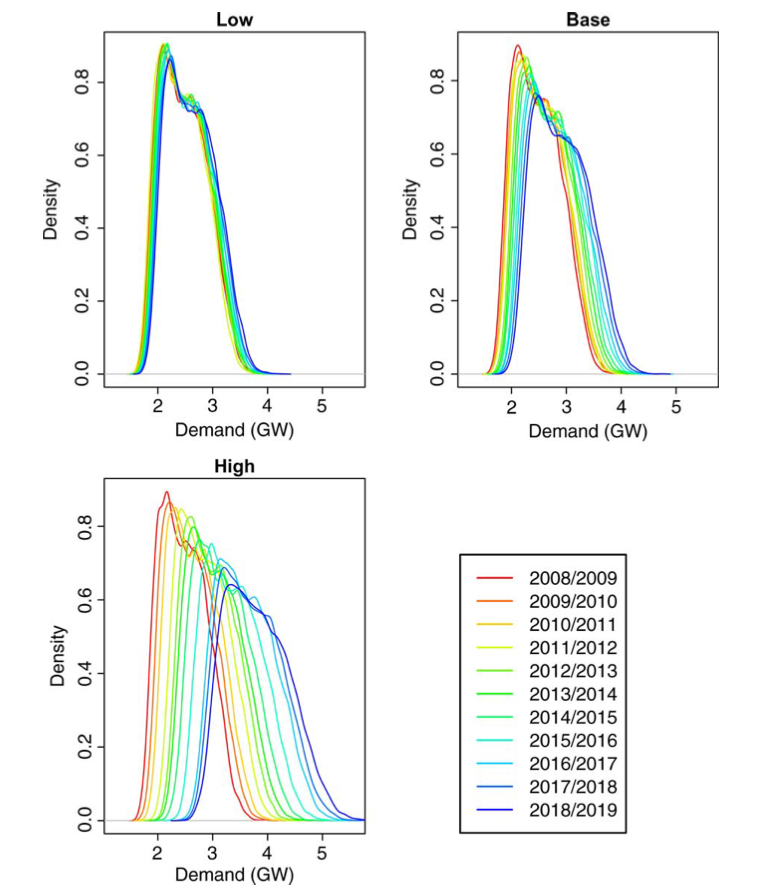
상위 왼쪽의 그림은 연간 median demand를 보여주고 각 데이터의 전력수요에 대한 trend를 확인할 수 있는 개형이다.
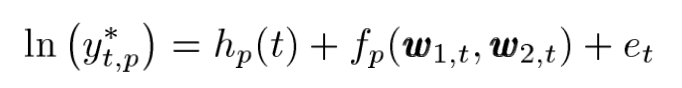
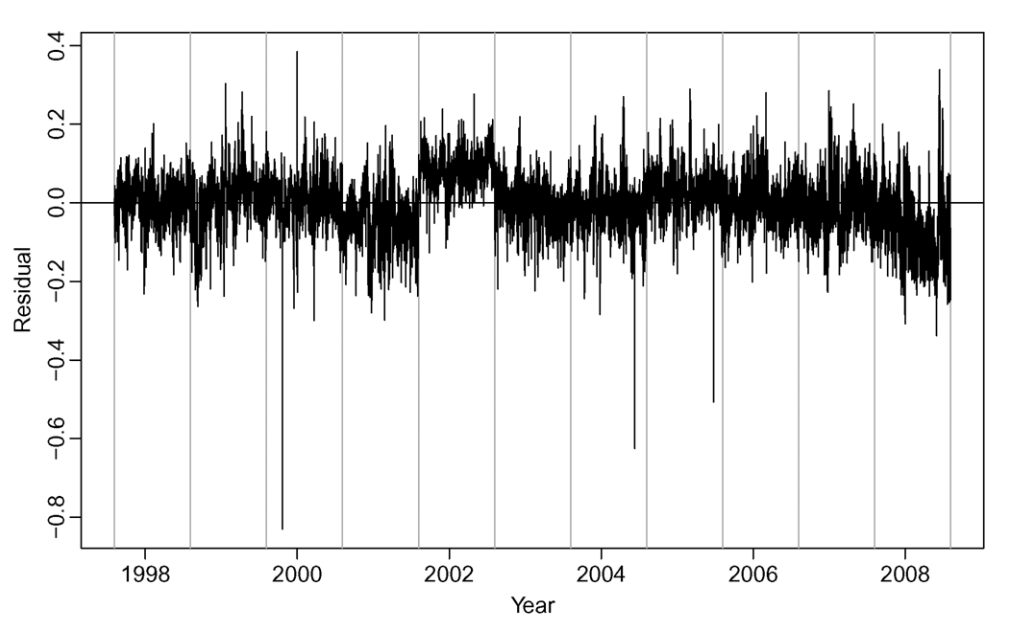
30분 단위 모델과 결합하여 historical data의 각구간별 수요량을 추정 하여 실제 값대비 수요예측 모델 값을 추정 할 수 있게 된다.
residual은 실제 수요값과 예측된 수요의 차이값으로 정의하게 된다.
stage 2:
new double Seasonal Block bootstrap method - temperature Simulation.
연간 온도 분포를 생성하기 위해 1. 가변 길이 블록과 가변 시작 위치 블록이 필요하게 된다.
모델의 검증 방법으로는 시물레이션 온도를 이용하여 위의 수요확률 분포를 확인하여 검증하게된다.
1. Bootstrap Temperature Resampling ( Single Season Bootstrap)
Bootstrap method로 과거 데이터를 무작위로 resampling 하는 방법이다.
시계열 데이터의 특성상 1. 계절성 2. 추세 패턴( seasonal or trend pattern) 3. inherent serial correlation을 유지하는것이 핵심적으로 중요하다.
여기서 시계열의 bootstrapping하는 표준 방법으로는 block bootstrap 방법이있다.
block bootstrap은 과거 시계열 데이터들에서 random segments를 획득하여 new artificial series에 함께 붙여 넣는 방법이다.
block bootstrap의 핵심은 각 세그먼트의 길이값에 따라 결과가 달라지게된다.
즉 데이터에서 추출한 세그먼트의 길이가 모델에 Dependent하게 되어 매개변수로 활동하게 된다.
최적화된 세그먼트의 길이는 1. 시계열 블록의 상관관계를 나타낼 수 있을만큼 길면서,,? 많은 타입의 시계열 특징을 잡아낼 수있을만큼 짧아야한다. 즉 모델에 합성시 새로운 시계열 데이터가 생성되어야한다 .
( 이것도 ...일종의 패턴구간을 자르기위해 기준이 모호해서 ... 아마 노가다성.... )
또한 계절성 시계열 데이터에 적용시, 각 세그먼트길이는 계절 기간에 따라 배수관계에 있어야하는것 역시 중요한 조건이다 .
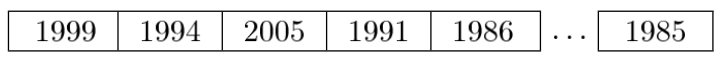
시계열데이터를 각 년도별로 블록을 활용하여 나누어 배열한것 처럼 single Season Bootstrap은 기록된 과거 데이터의 전체 계절로 구성되어 관측된 시점을 기준으로 다른 순서로 함께 데이터가 배열되게 된다.
이러한 방식을 single Season bootstrap이라고 한다.
예를들어보자면 1980년~2007년의 데이터에 적용시 , 계절은 4계절구간으로 4분기로 나누어지고 이는 1년이된다.
기존의 원시데이터의 시계열 데이터의 전체 길이가 동일한 bootstrap 으로 구성된 시계열 데이터의 뒤섞인 버전의 데이터는 위의 구성그림과같이 연도의 쪼개어진 데이터는 모두 가지고있지만 연도의 순서가 섞여서 배열된다.
2. Bootstrap Temperature Resampling ( double Season block Bootstrap)
single season block bootstrap method적 접근방법은 일별, 그리고 연간 계절성 성질의 시계열데이터가 포함되어 temperature simulation 에 적합하지 않다.
Double Season Block Bootstrap 방식은 우선 각 연도를 정수 값에 기반한 길이 m사이즈의 블록으로 데이터로 나누게된다.
( 블록의 길이 size는 m이된다. )
single block bootstrap과 의 차이점은 블록은 관찰된 것과 같은 연도의 동일 시간에 유지되지만 연도 사이가 무작위로 이동되어 배열될수 있다는 점이 다르다.
하지만 double block bootstrap방식을 이용시 특정 블록간 경계로 인해 시물레이션 결과 온도가 비현실적으로 상승할 가능성이 존재한다.
뿐만아니라 시뮬레이션된 시계열 데이터는 특정 주어진 관측된 데이터의 값으로인해 제한되는 문제로 인해 정확한 추정치를 얻기에 편차의 불충분성으로 문제가 야기된다.
그렇기 때문에 고정 길이 m 블록 대신 블록의 길이가 0<= △ < m 의 인 m-△ day 와 m+△ day의 사이값의 길이 변형을 하도록 허용하게된다.
또한 블록이 1년 내에 정확히 같은 위치에 유지되도록 요구하는 대신 원위치에서 며칠까지는 이동할 수 있도록 한다.
이러한 기법은 시계열 패턴에 영향이 거의 미치지 않고 상대적으로 영향도 상대적으로 작아 시뮬레이션이 진행된 일련의 데이터의 온도 데이터는 더 많은 수의 데이터셋을 구할 수 있도록 조작할 수 있게 된다.
블록의 길이를 선택하기 위해서 ( m-△ , m+△ ) 구간의 균일한 분포를 사용하고 , 각 블록의 시작위치에 대한 검증을 하기위해 (-△ ,△ ) 사이의 균일한 분포를 사용하게 된다.
즉 double season block bootstrap은 시뮬레이션 결과로 얻을 수 있는 데이터 셋의 양이 더 많아 지기 때문에 온도 분포를 생성하기에 더 옳은 성능을 내기위한 방법이다 .
(이미지 데이터셋을 변형하기위해 좌로 우로 채널수를 조정하는등의 조작과 비슷하다고 이해하면 될것같다. )
Probability Distribution Reproduction
확률 분포의 검증방법
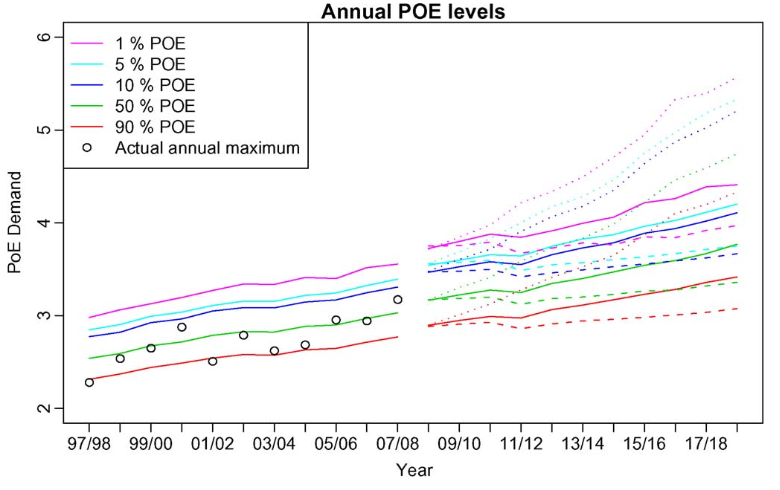
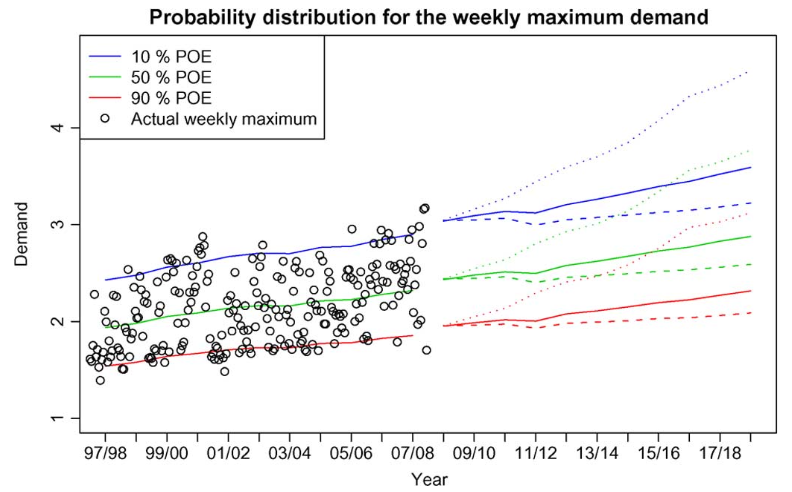
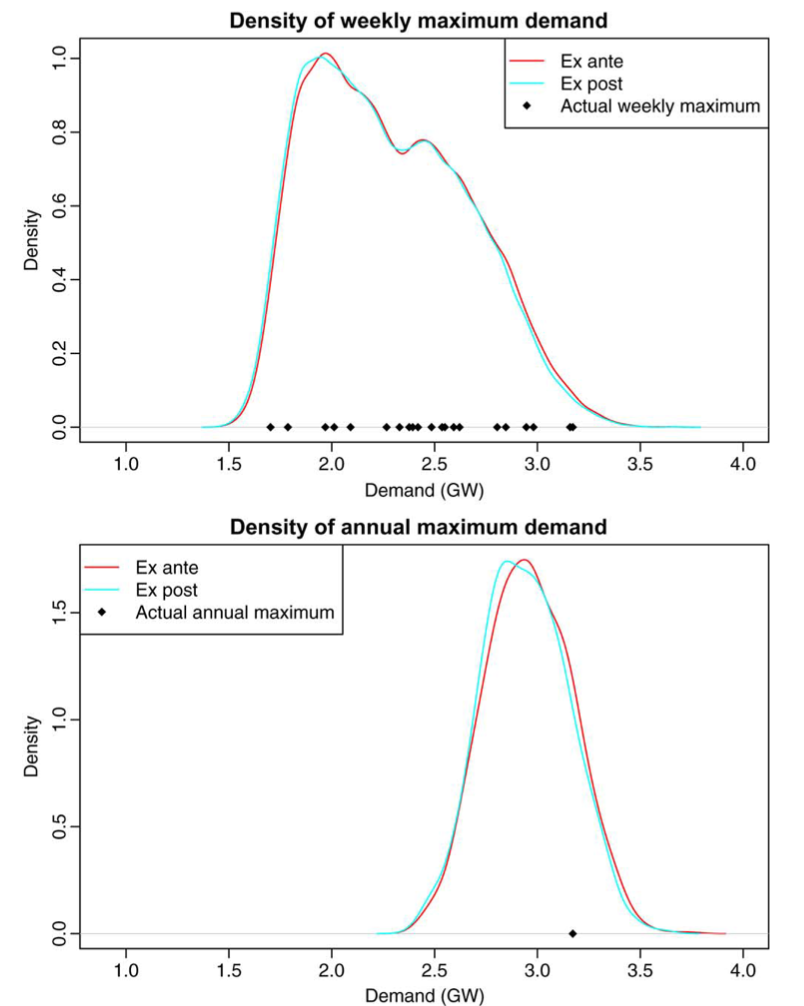
1. 제안된 온도 시뮬레이션의 효율성을 검증하기 위해서 1. 이미 알려진 경제 수치를 활용하여 온도 수치를 시뮬레이션하여 이전의 확률 분포를 재현한 후 실제 수요 데이터와 비교하게 된다.
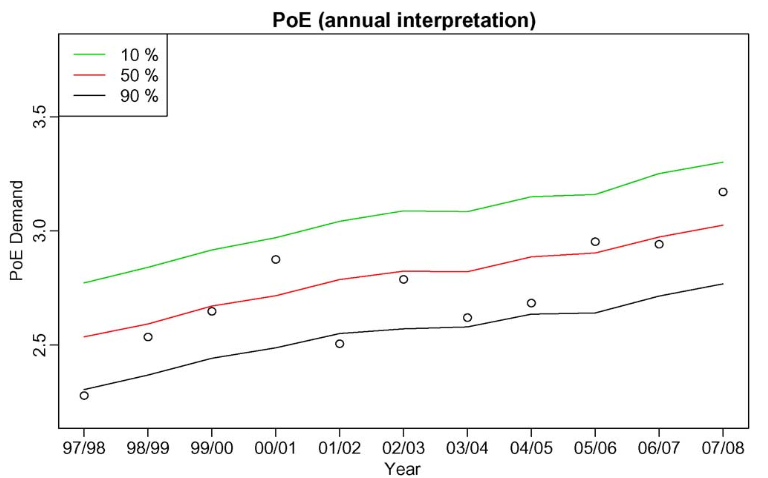
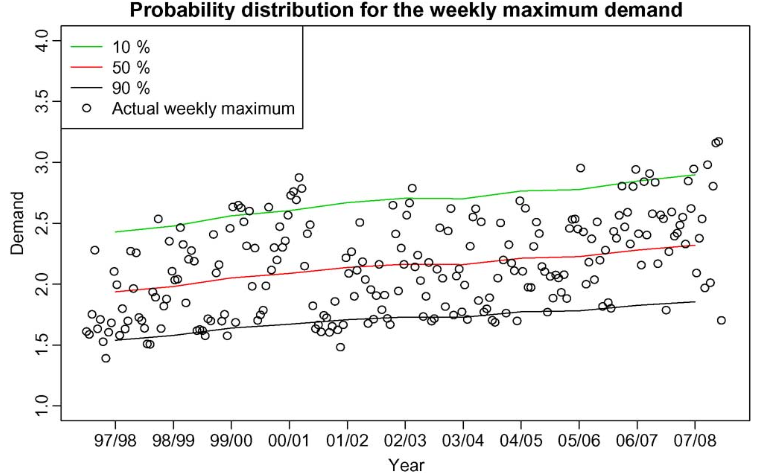
위의 데이터 그래프는 재생산된 확률 분포의 신뢰성을 검증할 수 있는 데이터로 범위 내에서 생산되어지는것을 나타낸다.
Forecasting and Evaluation
예측 결과는 실제 수요데이터와 예측 결과를 바탕으로 모델의 성능을 평가하게된다.
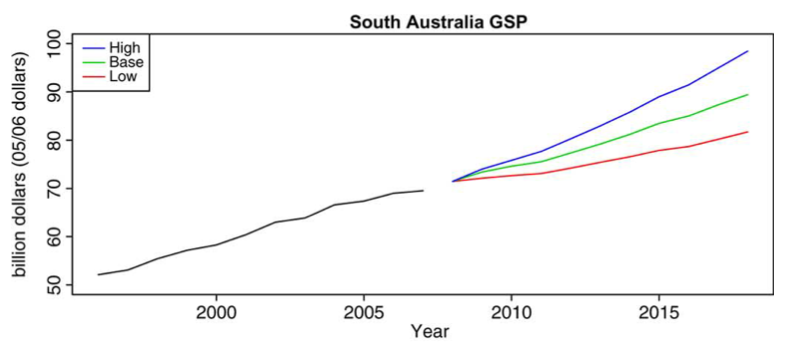
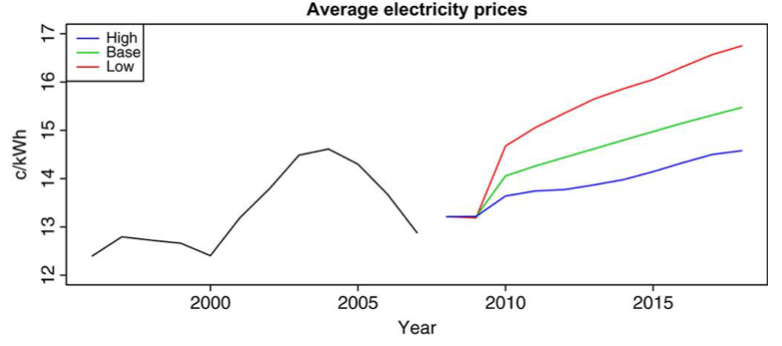
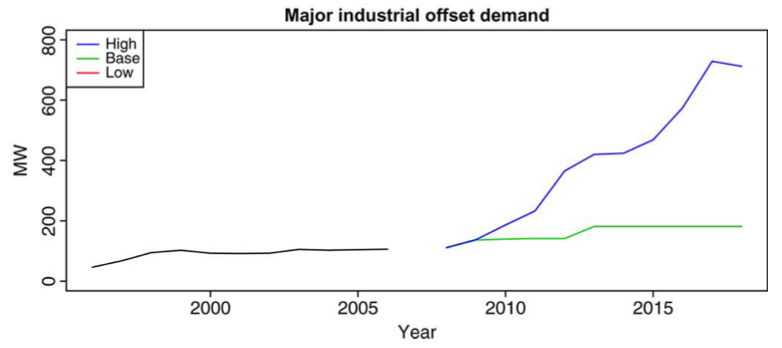
Forecast Result
전력 수요 분포의 예측은 적합한 모델을 시뮬레이션 하여 도출하게 된다.
지난 과거 관측 데이터를 기반으로 매년 예측하도록 데이터를 생성하게 되며 주요 산업의 전력 수요를 시뮬레이션 하기위해
Ot,p = Ot bar + ut,p ,의 형태의 수식으로 Ot bar 는 연간 주요 산업의 전력수요량 , ut,p는 serially correlated한 residual term으로 모델의 모든 구간에서 독립적이라는 전제로 부터 시작하게 된다.
뿐만아니라 single bootstrap method를 활용하여 시뮬레이션을 진행하는데 ut,p와 ot bar는 같다고 가정하고 시뮬레이션을 진행하게 된다.
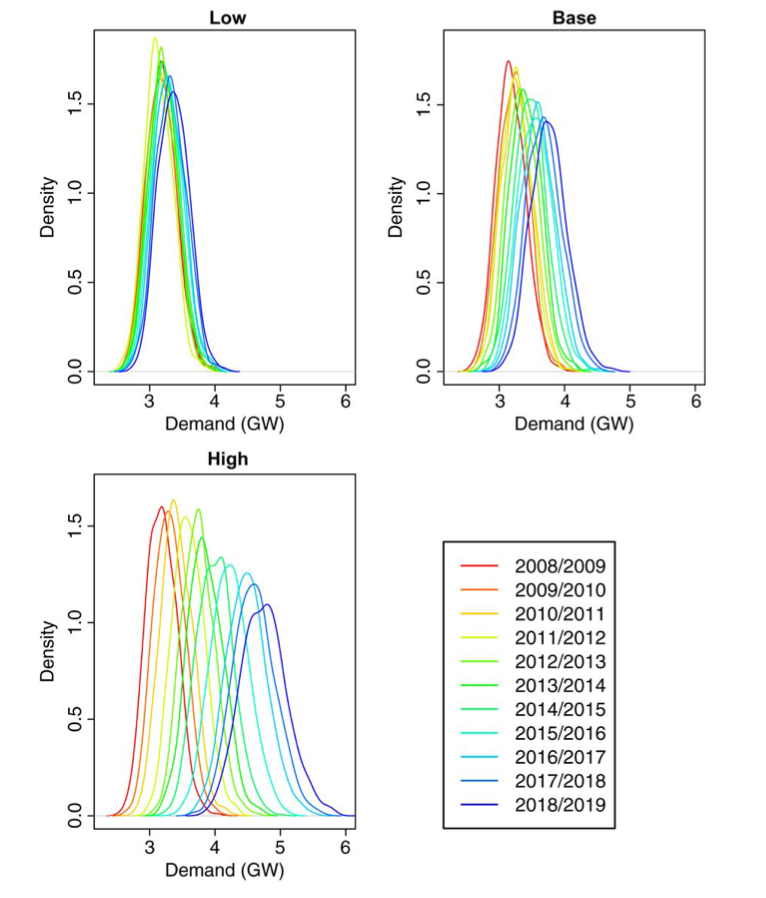
해당 논문은 시계열 전력데이터의 long term peak 데이터의 모델링 방법과 시뮬레이션 , 결과 예측을 포함한 방법론을 제안한것 같다.
1. 수치화 할수 있는 확률적 불확실성 과 , 미래의 최대 수요에 대한 예측성을 보여주었다는점이다.
2. 해당 모델은 연간 데이터와 30분 예측으로 나누어 별도로 데이터를 추정하게 된다.
3. 부스트트랩방법을 샘플링하는 방법으로 생각하여 추후 딥러닝 모델에 데이터 전처리 기법으로 적용해보는 방법도 좋은 생각인것같다.