[python] web Scraping & crawling ) 사용 방법
web crawling 이란 ?
월드 와이드 맵 소위 www상의 웹페이지 데이터를 프로그래밍적으로 추출하는 방법을 말한다.
데이터를 추출하는 방식으로는 web Crawling과 web Scraping방식이 존재한다.
web Crawling은 실시간 연동을 통하여 자동적으로 화면에 있는 data를 업데이트하여 데이터를 유지하는 기법이다.
반면 Web Scraping은 scraping시점의 데이터만 가져오는 방식이지만 자동적 실시간 데이터를 유지하는 방식은 아니라고 할수있다.
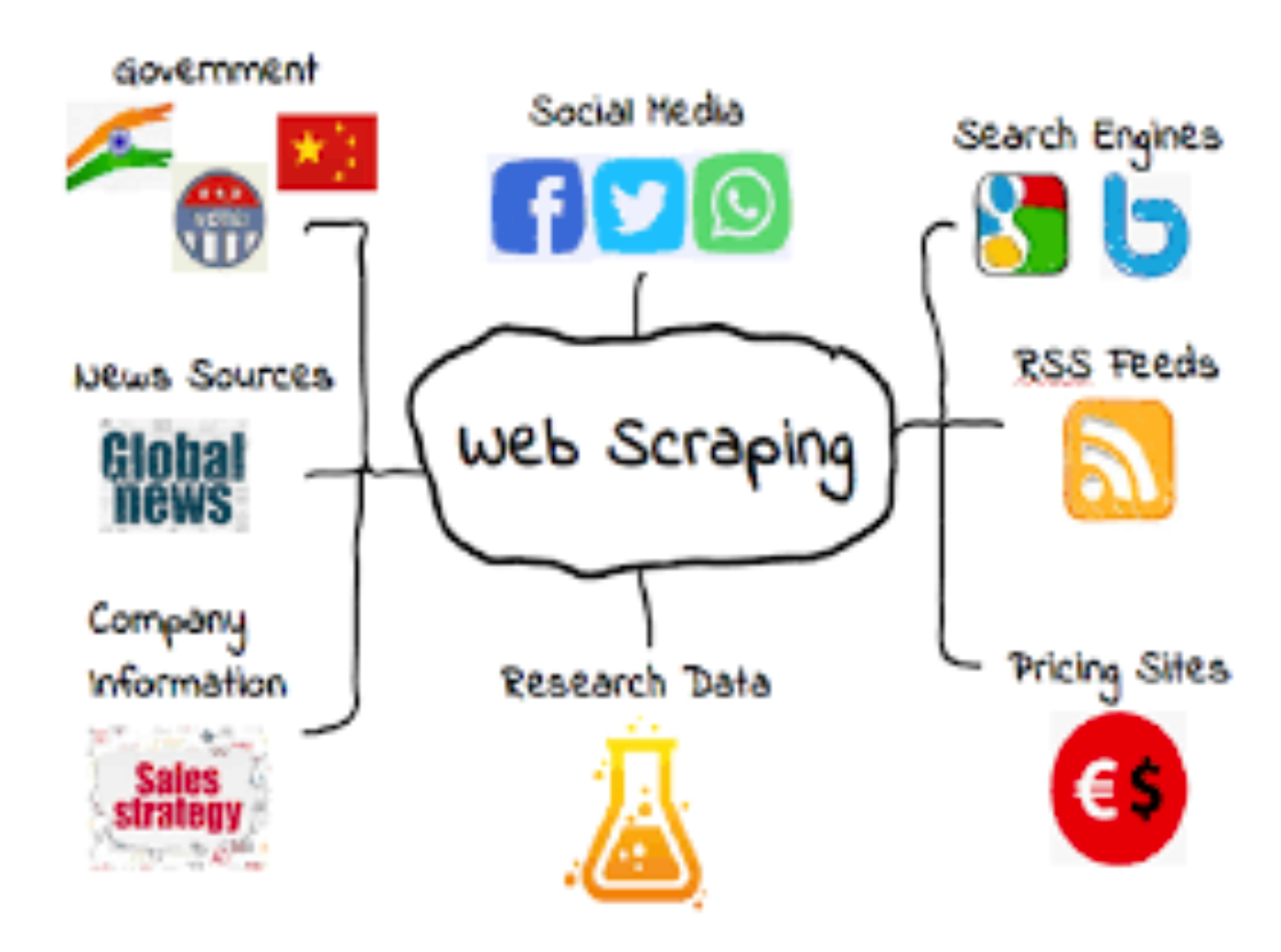
Crawling 툴 및 라이브러리
데이터 수집에있어 본질적으로 어떤 툴이나 라이브러리던 웹상의 데이터를 수집한다는 것에 있어 본질은 변하지 않는다.
하지만 사용자의 데이터 니즈에 따라 툴 및 라이브러리를 알맞게 사용하여 수집하면 된다.
가장 범용적으로 많이사용하는 라이브러리로 Beautiful Soup, Jsoup, Selenium등이 있다.
1. Beautiful Soup : HTML, XML문서를 Parsing하여 데이터를 추출하는 라이브러리로 Parse tree를 생성하여 추출하게 된다.
2. Selenium : 웹 테스트 라이브러리로 브라우저의 활동을 자동화하는데 사용하는 라이브러리 패키지이다.
crawling 원리 및 웹페이지 구성도
웹페이지의 구성을 보면 아래의 그림과 같다.
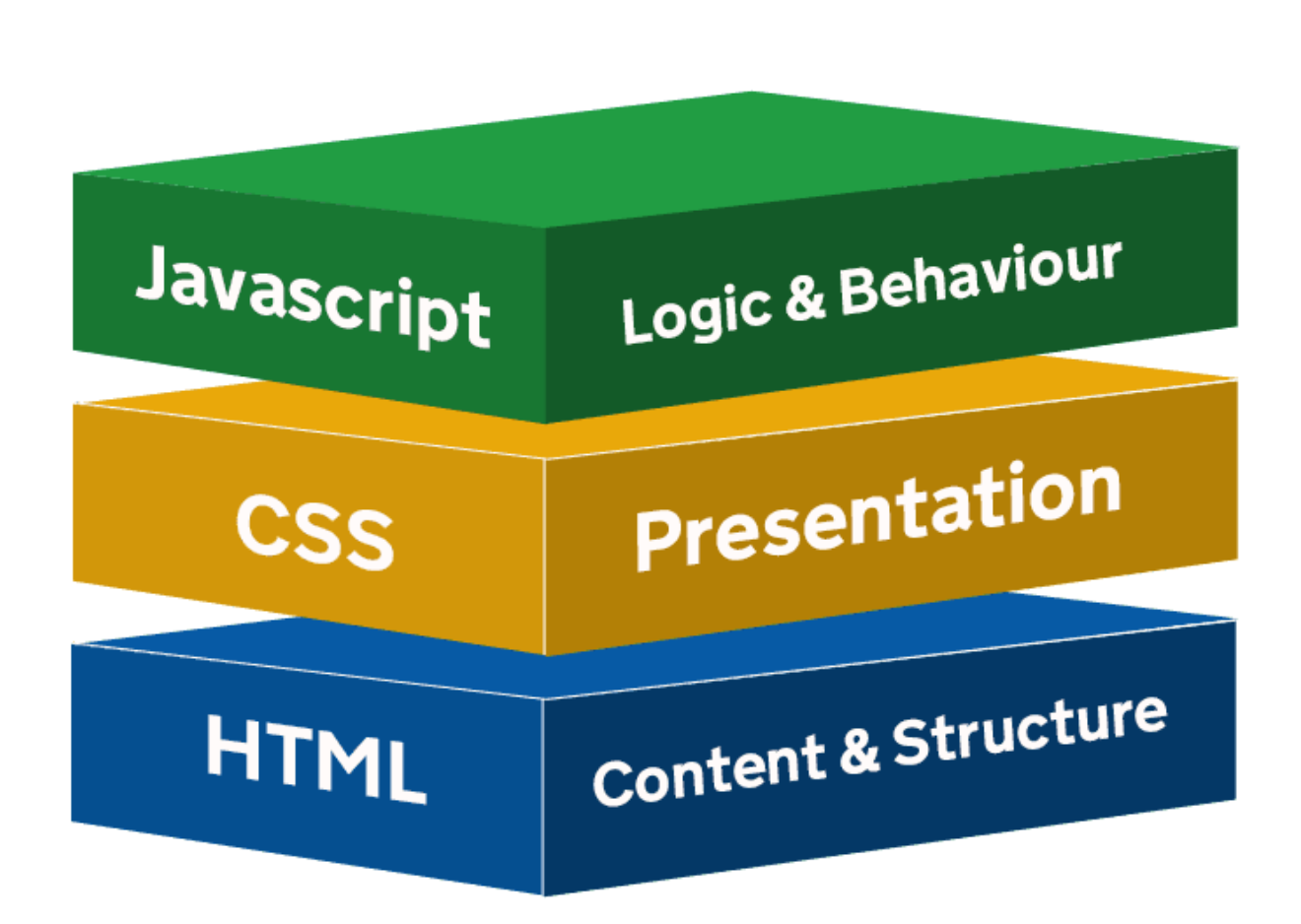
웹페이지는 뼈대가 되는 HTML, 디자인 CSS, 각 유저와 동적 연동하는 JavaScript로 총 3가지로 구성되어 있다.
크롬에서는 f12를 활용하여 위의 세가지 구조를 확인할수 있다.
웹 크롤러 아키텍쳐 및 크롤링 절차
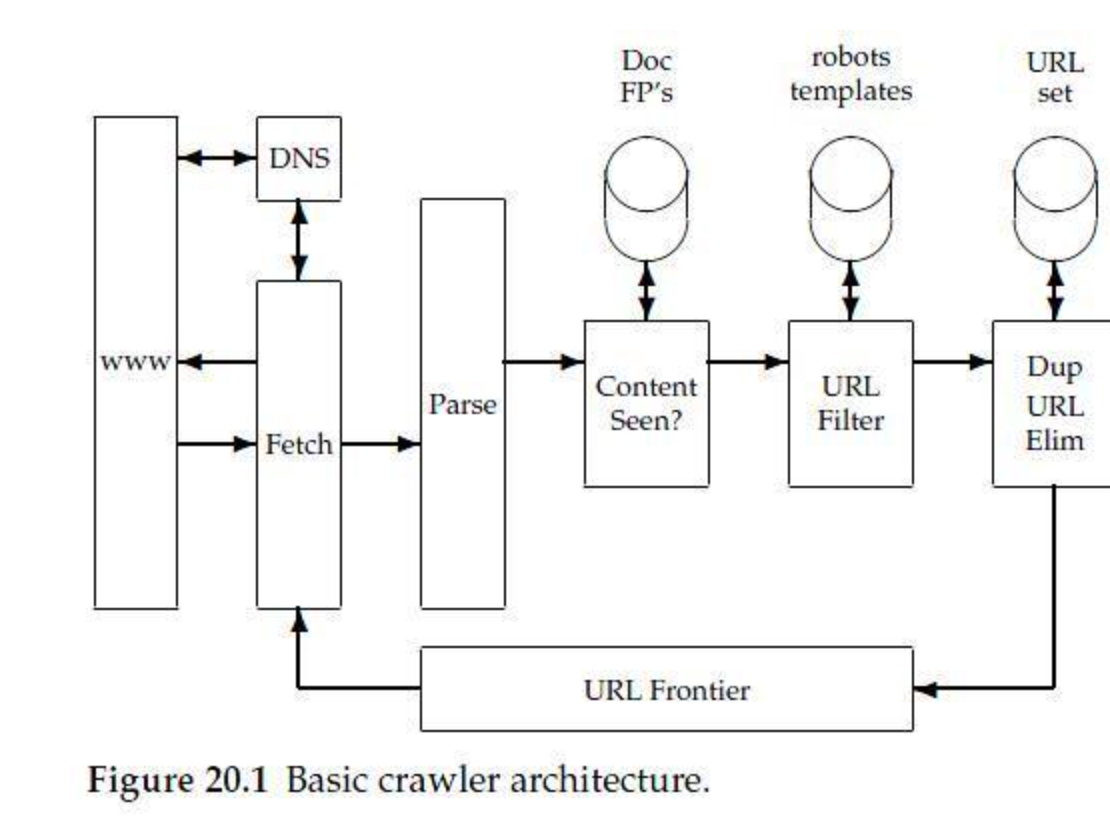
기본적인 크롤러 구조를 살펴보면 Frontier, Fetch, Parse와 하위 구조들이 있다.
우선 Frontier에서 우선 탐색할 URL을 Fetch에게 넘겨주면 Fetch에서 www상의 웹페이지의 Html 정보를 Parse에게 전달하여 Parse는 다른 링크(html a teg, url등)를 찾게된다. parse에서 찾은 URL은 다시 Frontier를 거쳐 Fetch로 가게 되는데. 이미 수집했던 링크를 다시 수집하게 된다면 무한루프 이슈가 생기므로 Dup URL Elim을 통하여 이미 방문history가 존재하는 URL들은 제거한체로 Fetch로 url정보를 전달하게 된다. ( DFS, BFS를 잘해야 하는 이유라고 볼 수 있다. )
Parse다음의 Content Seen은 블록 그대로 본문의 내용이 다른 url에서 본내용과 동일한 내용인지 아닌지를 판별하는 블록이다.
Web Crawling 절차
즉 위에서 구조에따라 다시 한번 작성하면 수집한 url 코드를 실행시 해당 url로 Request 메세지가 전송되고 절차에 따라 HTML, XML페이지를 읽을 수 있도록 하게 된다. 이후 HTML, XML페이지의 구문 분석후 데이터를 찾아 추출하게 된다 .
1. 스크랩할 URL 수집.
2. 페이지 검사
3. 데이터 검색
4. 코드 실행 및 데이터 추출
5. 사용자의 자료형에 따라 데이터 저장
절차에 따른 예제
1. URL 찾기
해당 예제에서는 야후 금융의 Bond data를 찾아 날짜, high ,low 데이터를 긁어 추출할 계획이다.
https://finance.yahoo.com/quote/BOND/history?p=BOND 스크랩할 URL은 YAHOO FINANCE . BOND 이다 .
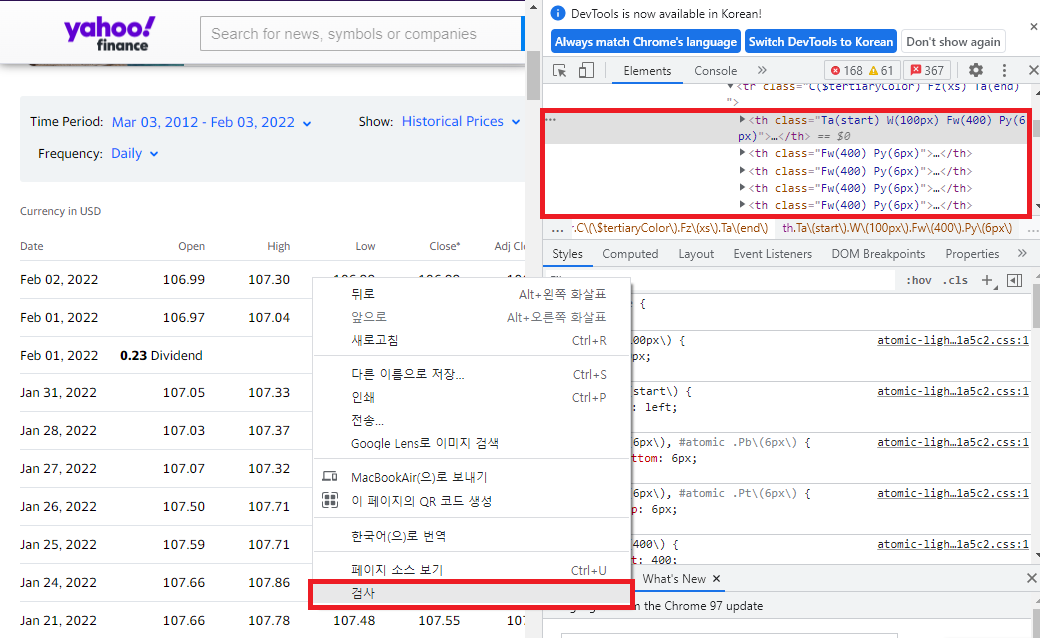
2. 페이지 검사
크롬브라우저의 f12를 눌러 코드를 확인해도 되겠지만 . 웹페이지상의 데이터는 대게 Tag에 중첩되어있다.
따라서 페이지 검사를 진행하여 추출할 데이터가 중첩된 태그 아래에 있는지 확인해야한다.
더 편한방법으로 Ctrl+ shift+c를 눌러 원하는 요소를 확인해볼 수 있다.
페이지 검사는 아래의 그림과 같이 하면 된다.
3. 추출할 데이터 찾기
태그에 있는 Date, Open, High, Low, Close를 찾아 데이터를 추출 해야한다.
야후 증권에서 추출할 데이터는 Table 태그의 Tr태그 안에 td태그에 데이터가 기록되어 있다.
해당 element를 복사해준다.
- Html 태그 정리 ↓↓↓↓↓↓↓↓↓
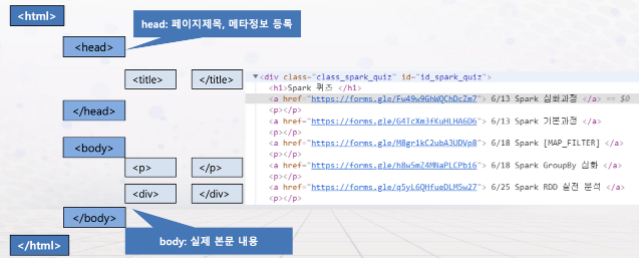
<html> : 웹페이지의 시작과 끝 ( <html> 로 시작해서 </html>로 끝난다 )
<head> : 웹페이지의 정보, 문서에서 사용할 외부 파일들을 링크할 때 사용 <title> <meta>등이 사용된다.
<body> : 브라우저에 실제로 표시되는 내용이다.
<title> : 문서제목 , <title>안의 내용이 웹브라우저의 제목 표시줄에 표시된다.
<meta> : 문자 인코딩 및 문서 키워드, 요약정보 <meta charset = "utf-8">
<div> : 아무 의미 없으며 컨텐츠를 목적에 따라 묶을때 사용한다.
<sapn> : 아무 의미 없으며 컨텐츠를 목적에 따라 묶을때 사용한다.
<a> : anchor, 웹페이지나 외부 사이트 연결 <a href = "link path"> 내용 </a>
<a>는 다른 문서혹은 사이트를 연결해주는 하이퍼링크, 링크를 생성할때 사용하게 되며 링크로 사용할 텍스트 혹은 이미지를 <a>로 묶고 href속성을 이용하여 연결할 웹페이지의 이름이나 웹사이트의 주소를 지정하면된다.
table tag
-tr/ th / td
<tr> : table 태그의 필수 요소로 th, td로 이루어져 Row를 나타내는 태그이다 tr이 사용되면 tr안의 요소는 하나의 행으로 처리된다.
<th> : 테이블의 요소별 제목을 나타낸다. 주로 사용하는 속성으로 (행병합)rowspan, (열 병합) colspan,scope가 있다.
<td> : 제목영역에 대한 데이터 및 정보를 나타낸다.
4. python code 작성
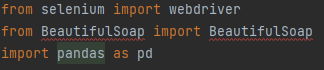
4.1. 코드를 작성 전 크롤링 및데이터 처리시 필요한 selenium , BeautifulSoap, pandas라이브러리를 Import 한다.
cf ) 4.2 ,** Selenium, BeautifulSoap, requests lib 정리
가장 일반적으로 라이브러리를 사용할때 BeautifulSoup을 가장 많이 사용하는 반면 Selenium 패키지는 BeautifulSoup다음으로 사용한다. 보통 BeautifulSoup4로 크롤링을 진행하고 Selenium은 BeautifulSoap으로 크롤링이 되지 않는 자바스크립트 기반의 동적 페이지, SPA기반 사이트의 정보를 가저오는 복잡한 로직기반의 작업을 수행시 사용하게 된다.
Selenium lib의 경우 BeautifulSoup보다 성능상 느리고, 네트워크 요청 및 브라우저의 도움을 받아야 하기때문에 코드 실행시 실제 웹브라우저가 실행 되는 등의 이유로 파이썬 기반 웹 크롤링을 진행시 BeautifulSoup이 안된다면 차선책으로 사용하게 된다. 그리고 BeautifulSoup 패키지를 활용하여 웹 크롤링을 진행시 . BeautifulSoup은 html분석을 편리하게 하는 툴로써 BeautifulSoup만으로 네트웤 통신을 할수 없다. 그렇기 때문에 urllib.requests 라이브러리 혹은 requests라이브러리를 이용하여 웹 서버의 http 규약에 적절한 request를 보내고 response 정보를 받아올 수 있는 네트워크 통신 기능을 가진 코드로 서버의 정보를 가져오게 된다.
요약
1. BeautifulSoup > Selenium
2. BeautifulSoup사용시 urllib.request , requests 패키지를 함께 써야함.
3. html 응답정보를 받은 이후 urlopen( ) 을 사용하여 html 응답 정보를 받아서 분석을 진행하게 됨 .
- Selenium lib 정리 ↓↓↓↓↓↓↓↓↓
- import
import selenium
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import Select
from selenium.webdriver.support.ui import WebDriverWait
Driver & Web Load ( 불러오기 )
URL = 'https://finance.yahoo.com/quote/BOND/history?p=BOND'
driver = webdriver.Chrome(executable_path='chromedriver')
driver.get(url=URL)우선 webdriver.chrome(path) 함수를 사용하여 드라이버를 로드하여 driver변수에 저장한다.
/ 동일 디렉토리라면 파일이름을 입력하면 되지만 경로가 다르다면 상대경로 혹은 절대경로를 이용하여 로드한다/
get(url)을 이용하여 URL을 브라우저에서 실행하는 코드이다.
**현재 URL 얻어오기
print(driver.current_url) 을 활용하면 디버깅시 현재 URL이 무엇인지 확인할 수 있다.
** 브라우저 닫기
driver.close()
**Wait till Load WebPage(로딩대기)
- 브라우저에서 해당 웹 페이지의 요소를 로드시 일정한 시간이 소요되며 element가 존재하지 않을 시
error 결과를 얻을 수 있기때문에 element를 모두 얻기전까지 대기해야한다.
-lmplicit waits
- element가 로드 될때까지 지정 시간동안 대기할 수 있도록 설정.
- webdriver에 영구적으로 작용. Deafult value는 0.
driver.implicitly_wait(time_to_wait = sec_time)
-Explicit Waits
무조건 해당 시간동안 대기하는 방식. ( 효율성이 떨어지는 방식이다 ).
time.sleep(secs)
wait till Load example
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support impoer expected_conditions as EC
driver = webdriver.Chrome('chromedriver')
driver.get(url='https://www.google.com/')
try:
element = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CLASS_NAME , 'gLFyf'))
#class가 gLFyF인 어떤 element를 찾을 수있는 지를 5초 동안 0.5초마다 시행.
# expected_conditions(EC)는 element를 찾을 수있으면 True, 아니면 False를 return.
)
finally:
driver.quit()++https://selenium-python.readthedocs.io/waits.html 링크를 참조하면 다양하 조건으로 custom 할수 있다.
요소 찾기 (Locating Elements)
Selenium lib는 다양한 element를 찾는 방법을 지원한다. Ctrl+Shift+C 키 혹은 검사키 혹은 f12를 이용하여 크롬에서 Element를 클릭하여 소스를 확인해볼수 있다.
각 Element는 Class, Xpath, id등의 속성자료가 존재하며 속성 혹은 경로를 이용하여 Element를 탐색할수 있는데 여기서 mendetory data를( 단일하고 유일한 자료)를 분석하여 찾아볼수 있다
대표적으로 class로 데이터를 찾게된다면
search = driver.find_element_by_class_name('gLFyf')
#키보드 입력 코드
serch.send_keys('gorio')를 활용하여 찾을수 있다. 즉 Search 변수에 검색의 요소가 들어가게 된다.
reference [Selenium 공식문서 ] https://selenium-python.readthedocs.io/index.html
- BeautifulSoup lib 정리 ↓↓↓↓↓↓↓↓↓
-인터넷 문서 구조에서 명확한 데이터를 추출하고 처리하기 가장 쉬운 라이브러리이다.
- 기본적으로 html파일을 가져오거나 urllib혹은 requests 모듈을 통하여 직접 웹에서 소스를 가져올 수 있다.
-주요 함수
find( ) , find_all( )
parameter는 찾고자 하는 태그의 이름, 속성 , 기타 등등이 속하게 된다.
find_all(name, attrs, recursive, string, limit, **kwargs)
find_all( ) 해당 조건에 맞는 모든 태그를 가져오는 함수이다.
find( name , attrs, recursive, string , **kwargs)
find( ) 해당 조건에 맞는 하나의 태그를 가져온다. 중복이라면 가장 첫번째 태그를 가져올것이다.
import
from bs4 import BeautifulSoupSoup Class
import requests
import bs4 import BeautifulSoup as Soup
url = 'url_path'
request = requests.get(url)
soup = Soup(r.text, "html.parser")
reference [ BeautifulSoup 공식 문서 ] https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- urllib.request 정리 ↓↓↓↓↓↓↓↓↓
파이썬에서는 웹과 관련된 데이터를 쉽게 다를수 있도록 urllib 내장모듈을 제공한다.
urllib 패키지는 URL을 통하여 여러 작업을 수행하는 모듈들을 가진 파이썬 내장 패키지이다.
urllib 패키지는 urllib.request , urllib.parse, urllib.error, urllib.robotparse 가 존재하며 그중 urllib.request에대해 공부하여 정리해보고자 한다.
IMPORT
import urllib.request
# URL 열기
urllib.request.urlopen(url)
# urllib.request.urlopen(url, data=None, timeout, cafile=None, capath=None, cadefault=False, context=None)
: URL을 열기 위한 함수
인자설명
url 문자열 url혹은 Request 객체에 해당하는 데이터
data 인자에는 POST 방식으로 요청 시의 데이터
timeout 인자는 선택적으로 사용합니다. 연결 시도에 대한 시간 초과 '초(seconds)'를 지정
cafile, capath, cadefault 인자는 CA 인증서에 대한 인자입니다. 인증서 검증에 대한 값들을 전달
context 인자에는 ssl.SSLContext 객체 SSL 연결에 대한 옵션
urlopen() API
geturl() : 받아온 리소스의 URL를 반환
info() : 패킷의 메타 데이터(헤더 등)를 반환
getcode() : 응답 패킷의 HTTP 상태 코드를 반환
read() : 받아온 데이터를 바이트형으로 반환
readline() : 받아온 데이터를 바이트형으로 한 줄씩 반환
close() : 연결된 요청을 닫기.
간단한 예제코드
import urllib.request
url = 'urlpath'
response = urllib.request.urlopen(url)
print(response.geturl())
print(response.getcode())
print(response.info())
print(response.readline())
response.close()# 요청관리하기
urllib.request.Request(url)
urllib.request.Request(url, data=None, headers = {}, origin_req_host=None, unverifiable=False, method=None)
: URL 요청을 추상화하기 위한 클래스.
urllib.request.urlopen() URL 요청을 인스턴트화하기 위해 사용.
url 유효한 URL의 문자열을 넣습니다.
data 요청에 대한 추가 데이터의 객체를 지정하거나 None을 지정
headers 요청에 필요한 헤더 [ Dictionary형 ]
origin_req_host 원본 트랙잭션의 요청 호스트를 지정 default 는 URL Request Host
unverifiable 요청에 대해 검증할 수 없는지의 여부(True / False)를 지정 . 기본 값은 False 입니다.
method HTTP 요청 메소드. 기본 값은 GET이고 HEAD, POST 등을 지정.
Request 클래스를 통해 해당 요청에 대한 인스턴트를 받아와 urlopen의 인자 사용.
Request API
Request.full_url : 전달된 원본 URL을 담고 있는 변수
Request.type : URL Scheme을 담고 있는 변수
Request.host : 요청된 URL의 호스트 부분을 담고 있는 변수
Request.origin_req_host : 포트를 제외한 원래의 호스트 부분을 담고 있는 변수
Request.method : 요청에 사용되는 HTTP 메소드를 설정하는 변수
Request.get_method() : 요청에 사용될 HTTP 메소드를 반환
- Requests lib 정리 ↓↓↓↓↓↓↓↓↓
Requests는 자주 쓰이는 HTTP 라이브러리 이다.
아래의 urllib.request는 파이썬에 내장되어 있는 Request라이브러리로 생각보다 복잡한 부분이 있어 Requests를 자주 사용하게 되고 urllib.requests보다 requests를 더 선호하는 경향이 많다.
그러나 Requests내부를 보면 urllib.requests를 사용하고 있어 선호하는 용도에 따라 골라서 사용하면 될것같다.
Basic API
requests.get()
requests.post()
requests.put()
requests.delete()
4.3 크롤링하고자 하는 url 가져오기
url을 가져온후 Request라이브러리를 활용하여 url을 호출하여 page를 읽어온다 .

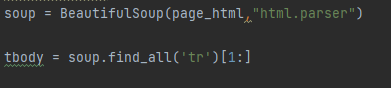
4.4 response html data를 페이지 검사에서 획득한 element기반으로 파싱하기
읽어온 데이터를 기반으로 위에서 tbody > tr 의 td에 위치한 데이터를 받아오기위해 파싱을 진행한다 .
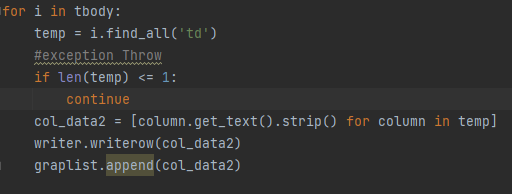
4.5 파싱데이터 수집하기
td에 위치한 데이터를 col_data2로 하여금 추출하는 작업의 코드이다.
4.6 데이터 csv파일로 저장
추출된 코드를 csv파일로 바로 쓰고 해당 데이터를 파일에 저장하여 유지하게 된다.

4.7 데이터 시각화
전체 예제 코드 1
2022.02.07 작성
import csv
from urllib.request import urlopen , Request
from bs4 import BeautifulSoup
from collections import defaultdict
import matplotlib.pyplot as plt
import numpy as np
#global variable
# 1. csv file variable
file_name = 'usa_stock.csv'
# web crawling variable
url = "https://finance.yahoo.com/quote/BOND/history?p=BOND"
col_data = ['date','open','High','low','close','adj Close', 'volume']
# matplot pipe data
graplist = defaultdict(list)
#csv file open and write mode
f = open(file_name, 'w', encoding='utf-8-sig', newline='')
writer = csv.writer(f)
writer.writerow(col_data)
#url html get
response1 = Request(url, headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'})
#opening up connection and grabbing page 1
uclient = urlopen(response1)
page_html = uclient.read()
uclient.close()
#parsing data
soup = BeautifulSoup(page_html,"html.parser")
tbody = soup.find_all('tr')[1:]
#columns get
for i in tbody:
temp = i.find_all('td')
#exception Throw
if len(temp) <= 1:
continue
col_data2 = [column.get_text().strip() for column in temp]
writer.writerow(col_data2)
graplist.append(col_data2)
print(col_data2)
# file read
with open(file_namee) as raw:
reader = csv.DictReader(raw)
for lines in reader:
for k,v in lines.items():
column[k].append(v)
plt.plot(col_data2)
plt.show()